Oracle11gR2 Aactive DataGuard(手动)安装部署及维护文档(四)之broker
一.使用gurad broker管理DG
· 1.Data Guard Broker配置管理
配置data guard broker配置文件基本参数
每个数据库中都会维护两份配置文件,这样能保证任何时候我们都有一个可用的配置文件存在,两份配置文件的位置和名字根据系统参数DG_BROKER_CONFIG_FILE1,DG_BROKER_CONFIG_FILE2决定,如果没有设置将使用默认的值来创建。在设置这两个参数的时候需要注意下面几个问题:
- RAC系统中每个数据库实例中的参数设置必须是一致的。
- 只有在broker没有运行的时候才能修改此参数,即DG_BROKER_START=FALSE的时候。
- These parameters must specify a raw device, ASM file, or cluster file system file that resolves to the same set of physical files for all RAC instances.
在修改DG_BROKER_CONFIG_FILEn的时候,如果指向的配置文件不是放在裸设备上的话不需要其他的更多的操作,重新启动DMON进程(设置DG_BROKER_START=TRUE)之后会自动的生成配置文件,如果配置放在裸设备上则需要手工的将配置文件的内容从旧的位置复制到新位置上。
启动data guard broker
只需要将初始化参数DG_BROKER_START设置为TRUE则系统会自动的启动DMON进程,将其设置为FALSE之后则DMON进程会自动退出。
--启动broker
SQL> alter system set dg_broker_start=true;
SQL> !ps -ef|grep dmon|grep -v grep
oracle 20539 1 0 Sep06 ? 00:01:30 ora_dmon_htdb2
--停止broker
SQL> alter system set dg_broker_start=false;
SQL> !ps -ef|grep dmon|grep -v grep
data guard broker的管理周期
data guard broker状态查看
[oracle@hotel01 trace]$ dgmgrl sys/oracle123
DGMGRL for Linux: Version 11.2.0.2.0 - 64bit Production
Copyright (c) 2000, 2009, Oracle. All rights reserved.
欢迎使用 DGMGRL, 要获取有关信息请键入 "help"。
已连接。
DGMGRL> show configuration
配置 - htdb1
保护模式: MaxAvailability
数据库:
htdb1 - 主数据库
htdb3 - 物理备用数据库
htdb2 - 物理备用数据库
快速启动故障转移: DISABLED
配置状态:
SUCCESS
禁用和启动broker操作
禁用和启用操作分为两个层次的,第一个层次是数据库级别的,对应于ENABLE/DISABLE DATABASE命令,受影响的是被操作的数据库,另一个层次是配置级别的,对应于ENABLE/DISABLE CONFIGURATION命令,影响的是被broker管理的所有的数据库。但是不管是什么级别的禁用/启用操作都是影响的DMON进程对于受影响数据库的下列操作:
- 管理和监控受影响的数据库
- 管理受影响的数据库的配置信息,比如说通过DGMGRL修改数据库参数什么的。
注意:
- 禁用操作并不会影响data guard的正常运行,日志传送服务或是日志应用服务等等就还是正常的工作的。
- 被禁用的数据库的配置信息并不会从broker配置信息中删除,只是相应数据库的状态信息改变了而已。
- 如果在禁用的状态下更改了数据库的属性,那在启用操作执行之前这些被更改的属性将不能被应用到对应的数据库的,但是启动配置之后这些更改将会马会的被应用到数据库中。
在主库hotel01:
DGMGRL> disable configuration
已禁用。
DGMGRL> show configuration
配置 - htdb1
保护模式: MaxAvailability
数据库:
htdb1 - 主数据库
htdb3 - 物理备用数据库
htdb2 - 物理备用数据库
快速启动故障转移: DISABLED
配置状态:
DISABLED
DGMGRL> enable configuration
已启用。
enable configuration的时候broker会重新设定数据库的很多系统的初始化参数,确保数据库运行的参数和broker配置文件中所设定的是一致的,这些动作我们可以从broker monitoring的日志DRCdb_unique_name.log里面看到,这个日志文件存放位置和alert.log是一样的,下面是primary数据库上的一部分日志示例:
[oracle@hotel01 ~]$ cd /u01/app/ora11g/diag/rdbms/htdb1/htdb1/trace/
[oracle@hotel01 trace]$ ls *.log
alert_htdb1.log drchtdb1.log
[oracle@hotel01 trace]$ tail -100f drchtdb1.log
2011-09-21 11:07:14.023 00000000 2104245480 DMON: Entered rfm_get_chief_lock() for CTL_ENABLE, reason 0
2011-09-21 11:07:14.026 00000000 2104245480 DMON: start task execution: CTL_ENABLE
2011-09-21 11:07:14.027 Executing SQL [ALTER SYSTEM REGISTER]
2011-09-21 11:07:14.052 SQL [ALTER SYSTEM REGISTER] Executed successfully
2011-09-21 11:07:14.058 00001000 2104245480 DMON: Evaluating critical status of standbys in configuration
2011-09-21 11:07:14.061 00001000 2104245480 DMON: Evaluating critical status of 0x02010000
2011-09-21 11:07:14.063 00001000 2104245480 ChangeCritical value is FALSE
2011-09-21 11:07:14.063 00001000 2104245480 IsCritical value is FALSE
2011-09-21 11:07:14.064 00001000 2104245480 DMON: Evaluating critical status of 0x03010000
2011-09-21 11:07:14.064 00001000 2104245480 ChangeCritical value is FALSE
2011-09-21 11:07:14.064 00001000 2104245480 IsCritical value is FALSE
2011-09-21 11:07:14.065 DMON: Updated Seq.MIV to 5.5, writing metadata to "+DATA/dr1htdb1.dat"
2011-09-21 11:07:14.313 INSV: Received message for inter-instance publication
2011-09-21 11:07:14.316 req ID 1.1.2104245480, opcode CTL_ENABLE, phase RESYNCH, flags 5
2011-09-21 11:07:14.315 00001000 2104245480 DMON: status from rfi_post_instances() for CTL_ENABLE = ORA-00000
2011-09-21 11:07:14.316 00001000 2104245480 DMON: dispersing message to standbys for ENABLE phase RESYNCH
2011-09-21 11:07:14.317 INSV: Reply received for message with
2011-09-21 11:07:14.319 req ID 1.1.2104245480, opcode CTL_ENABLE, phase RESYNCH
2011-09-21 11:07:14.318 NSV2: (Seq.MIV = 5.5) Start sending metadata file: "+DATA/dr1htdb1.dat"
2011-09-21 11:07:14.343 NSV1: (Seq.MIV = 5.5) Start sending metadata file: "+DATA/dr1htdb1.dat"
2011-09-21 11:07:14.630 NSV2: Sending block #1 (containing Seq.MIV = 5.5), 5 blocks
2011-09-21 11:07:14.640 NSV2: (Seq.MIV = 5.5) End metadata file transmission: opcode CTL_ENABLE (1.1.2104245480)
2011-09-21 11:07:15.093 NSV1: Sending block #1 (containing Seq.MIV = 5.5), 5 blocks
2011-09-21 11:07:15.107 NSV1: (Seq.MIV = 5.5) End metadata file transmission: opcode CTL_ENABLE (1.1.2104245480)
2011-09-21 11:07:20.360 00001000 2104245480 DMON: status from rfi_post_instances() for CTL_ENABLE = ORA-00000
2011-09-21 11:07:20.362 00001000 2104245480 DMON: dispersing message to standbys for ENABLE phase BEGIN
2011-09-21 11:07:20.362 INSV: Received message for inter-instance publication
2011-09-21 11:07:20.364 req ID 1.1.2104245480, opcode CTL_ENABLE, phase BEGIN, flags 5
2011-09-21 11:07:20.365 00001000 2104245480 DMON: Entered rfmeexinst for phase 1
2011-09-21 11:07:20.367 INSV: Reply received for message with
2011-09-21 11:07:20.368 req ID 1.1.2104245480, opcode CTL_ENABLE, phase BEGIN
2011-09-21 11:07:20.414 INSV: Received message for inter-instance publication
2011-09-21 11:07:20.414 00001000 2104245480 DMON: status from rfi_post_instances() for CTL_ENABLE = ORA-00000
2011-09-21 11:07:20.416 req ID 1.1.2104245480, opcode CTL_ENABLE, phase TEARDOWN, flags 5
2011-09-21 11:07:20.416 00001000 2104245480 DMON: dispersing message to standbys for ENABLE phase TEARDOWN
2011-09-21 11:07:20.420 00001000 2104245480 DMON: Entered rfmeexinst for phase 2
2011-09-21 11:07:20.426 RSM0: Received Set State Request: rid=0x01041001, sid=1, phid=1, econd=7, sitehndl=0x7fffffff
2011-09-21 11:07:20.434 Log Transport Resource: SetState ONLINE, phase TEAR-DOWN, External Cond ENABLE
2011-09-21 11:07:20.437 RSM0: Received Set State Request: rid=0x01011001, sid=9, phid=1, econd=7, sitehndl=0x7fffffff
2011-09-21 11:07:20.438 Database Resource[IAM=PRIMARY]: SetState READ-WRITE-XPTON, phase TEAR-DOWN, External Cond ENABLE, Target Site Handle 0x7fffffff
2011-09-21 11:07:20.453 RSM: DRC's protection mode is 'MaxAvailability'
2011-09-21 11:07:20.454 Database Resource SetState succeeded
2011-09-21 11:07:20.457 RSM0: Received Set State Request: rid=0x01012001, sid=9, phid=1, econd=7, sitehndl=0x7fffffff
2011-09-21 11:07:20.465 INSV: Reply received for message with
2011-09-21 11:07:20.467 req ID 1.1.2104245480, opcode CTL_ENABLE, phase TEARDOWN
2011-09-21 11:07:20.469 00001000 2104245480 DMON: status from rfi_post_instances() for CTL_ENABLE = ORA-00000
2011-09-21 11:07:20.470 00001000 2104245480 DMON: dispersing message to standbys for ENABLE phase BUILDUP
2011-09-21 11:07:20.470 INSV: Received message for inter-instance publication
2011-09-21 11:07:20.474 req ID 1.1.2104245480, opcode CTL_ENABLE, phase BUILDUP, flags 5
2011-09-21 11:07:20.481 00001000 2104245480 DMON: Entered rfmeexinst for phase 4
2011-09-21 11:07:20.483 RSM0: Received Set State Request: rid=0x01011001, sid=9, phid=2, econd=7, sitehndl=0x7fffffff
2011-09-21 11:07:20.484 Database Resource[IAM=PRIMARY]: SetState READ-WRITE-XPTON, phase BUILD-UP, External Cond ENABLE, Target Site Handle 0x7fffffff
2011-09-21 11:07:20.487 Set log transport destination: SetState ONLINE, phase BUILD-UP, External Cond ENABLE
2011-09-21 11:07:20.493 Executing SQL [ALTER SYSTEM SET log_archive_trace=0 SCOPE=BOTH sid='htdb1']
2011-09-21 11:07:20.976 SQL [ALTER SYSTEM SET log_archive_trace=0 SCOPE=BOTH sid='htdb1'] Executed successfully
2011-09-21 11:07:20.976 Executing SQL [ALTER SYSTEM SET log_archive_format='%t_%s_%r.dbf' SCOPE=SPFILE sid='htdb1']
2011-09-21 11:07:21.061 SQL [ALTER SYSTEM SET log_archive_format='%t_%s_%r.dbf' SCOPE=SPFILE sid='htdb1'] Executed successfully
2011-09-21 11:07:21.118 Executing SQL [ALTER SYSTEM SET standby_file_management='AUTO' SCOPE=BOTH sid='*']
2011-09-21 11:07:21.131 SQL [ALTER SYSTEM SET standby_file_management='AUTO' SCOPE=BOTH sid='*'] Executed successfully
2011-09-21 11:07:21.289 Executing SQL [ALTER SYSTEM SET archive_lag_target=0 SCOPE=BOTH sid='*']
· 2.数据库管理
查看数据库当前的状态
DGMGRL>show database htdb1
数据库 - htdb1
角色: PRIMARY
预期状态: TRANSPORT-ON
实例:
htdb1
数据库状态:
SUCCESS
DGMGRL> show database htdb2
数据库 - htdb2
角色: PHYSICAL STANDBY
预期状态: APPLY-ON
传输滞后: 0 秒
应用滞后: 0 秒
实时查询: ON
实例:
htdb2
数据库状态:
SUCCESS
DGMGRL> show database htdb3
数据库 - htdb3
角色: PHYSICAL STANDBY
预期状态: APPLY-ON
传输滞后: 0 秒
应用滞后: 0 秒
实时查询: ON
实例:
htdb3
数据库状态:
SUCCESS
修改数据库当前的状态
数据库状态分类:
通过edit命令来修改数据库的状态,命令语法如下
EDITDATABASE'db_unique_nmae'SETSTATE='database_state';
DGMGRL> edit database htdb2 set state='offline';
操作要求关闭实例 "htdb2" (在数据库 "htdb2" 上)
正在关闭实例 "htdb2"...
数据库已经关闭。
已经卸载数据库。
ORACLE 例程已经关闭。
DGMGRL> show database htdb2
数据库 - htdb2
角色: PHYSICAL STANDBY
预期状态: OFFLINE
传输滞后: (未知)
应用滞后: (未知)
实时查询: OFF
实例:
htdb2
数据库状态:
SHUTDOWN
显示/修改数据库属性
broker管理的数据库属性包含两类:第一类是可监控的属性,第二类是可配置的属性。
可监控属性:顾名思义,可监控的属性是能在broker的界面中看到属性的设定值,但是不能够修改。
可配置属性:可配置属性既能监控,同时还能够动态的修改。可配置属性在数据库处于任何状态的是很都能够修改,不过当数据库处于OFFLINE状态或者是DISABLE状态的时候,属性的修改会先记录到broker配置文件中,在数据库broker被启用之后会被应用到据库中。
对于可配置的数据库属性,broker会保证启用了broker的数据库它在broker配置文件后中记录的数据库的属性和数据库运行所使用的参数是一致的,但这也有两种情况:
(1).如果对应的数据库参数是可以动态更新的,那么broker配置文件、SGA、spfile这三个地方所涉及的属性值将会是一样的。
(2).如果对应的数据库参数不能动态更新,那么在数据库重启之前broker配置文件、SGA这两个地方的参数值是一样的,spfile中参数值要在数据库重新启动之后才能与broker配置文件值一致。
Ø 使用show database verbose命令可以查看数据库当前的属性设置,值显示为“(monitor)”的自然就是可监控的属性了,其他的属性都属于可配置的。
DGMGRL> show database verbose htdb2
数据库 - htdb2
角色: PHYSICAL STANDBY
预期状态: APPLY-ON
传输滞后: 0 秒
应用滞后: 0 秒
实时查询: ON
实例:
htdb2
属性:
DGConnectIdentifier = '(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=hotel02)(PORT=1521))(CONNECT_DATA=(SERVICE_NAME=htdb2)(SERVER=DEDICATED)))'
ObserverConnectIdentifier = ''
LogXptMode = 'ASYNC'
DelayMins = '0'
Binding = 'optional'
MaxFailure = '0'
MaxConnections = '1'
ReopenSecs = '300'
NetTimeout = '30'
RedoCompression = 'DISABLE'
LogShipping = 'ON'
PreferredApplyInstance = ''
ApplyInstanceTimeout = '0'
ApplyParallel = 'AUTO'
StandbyFileManagement = 'AUTO'
ArchiveLagTarget = '0'
LogArchiveMaxProcesses = '4'
LogArchiveMinSucceedDest = '1'
DbFileNameConvert = ''
LogFileNameConvert = 'null, null'
FastStartFailoverTarget = ''
InconsistentProperties = '(monitor)'
InconsistentLogXptProps = '(monitor)'
SendQEntries = '(monitor)'
LogXptStatus = '(monitor)'
RecvQEntries = '(monitor)'
SidName = 'htdb2'
StaticConnectIdentifier = '(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=hotel02)(PORT=1521))(CONNECT_DATA=(SERVICE_NAME=htdb2_DGMGRL)(INSTANCE_NAME=htdb2)(SERVER=DEDICATED)))'
StandbyArchiveLocation = 'USE_DB_RECOVERY_FILE_DEST'
AlternateLocation = ''
LogArchiveTrace = '0'
LogArchiveFormat = '%t_%s_%r.dbf'
TopWaitEvents = '(monitor)'
数据库状态:
SUCCESS
Ø 通过edit database命令修改数据库属性,基本语法如下
EDITDATABASEdb_unique_nameSETPROPERTY'property_name'=property_value;
DGMGRL> show database htdb2 nettimeout
NetTimeout = '30'
DGMGRL> edit database htdb2 set property 'NetTimeout'=120;
已更新属性 "NetTimeout"
可以到在主库htdb1的broker日志文件, broker在修改log_archive_dest_2值
[oracle@hotel01 trace]$ tail -200f drchtdb1.log
2011-09-22 10:39:26.846 SQL [alter system set log_archive_dest_2='service="(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=hotel02)(PORT=1521))(CONNECT_DATA=(SERVICE_NAME=htdb2)(SERVER=DEDICATED)))"', 'LGWR ASYNC NOAFFIRM delay=0 optional compression=disable max_failure=0 max_connections=1 reopen=300 db_unique_name="htdb2" net_timeout=120','valid_for=(all_logfiles,primary_role)'
可以在备库htdb1的broker日志文件,broker在同步配置
2011-09-22 10:29:41.553 Database Resource: Verify Resource; level VERIFY-PARAMETERS, number of properties changed 1
2011-09-22 10:29:41.553 Property Name: NetTimeout
2011-09-22 10:29:41.553 Property type CONFIGURABLE
2011-09-22 10:29:41.553 Value type INT
2011-09-22 10:29:41.553 Value: 120
2011-09-22 10:29:41.554 02010000 253724409 DMON: Entered rfm_release_chief_lock() for EDIT_RES_PROP
2011-09-22 10:29:44.994 DRCX: Start receiving metadata file: "+DATA/dr2htdb2.dat"
2011-09-22 10:29:45.025 DRCX: Receiving block #1 (containing Seq.MIV = 5.13), 5 blocks
设置数据库的保护模式
保护模式与其他设置之间的关系
| 保护模式 |
日志传送模式 |
是否需要standby日志? |
是否能和fast-start failover一起用 |
| MAXPROTECTION |
SYNC |
是 |
否 |
| MAXAVAILABILITY |
SYNC |
是 |
是 |
| MAXPERFORMANCE |
ASYNC或ARCH |
|
|
Ø 使用broker来设置保护模式也是通过edit configuration来操作
DGMGRL> show configuration
配置 - htdb1
保护模式: MaxAvailability
数据库:
htdb1 - 主数据库
htdb3 - 物理备用数据库
htdb2 - 物理备用数据库
快速启动故障转移: DISABLED
配置状态:
SUCCESS
DGMGRL> edit configuration set protection mode as MaxPerformance;
成功。
DGMGRL> show configuration
配置 - htdb1
保护模式: MaxPerformance
数据库:
htdb1 - 主数据库
htdb3 - 物理备用数据库
htdb2 - 物理备用数据库
快速启动故障转移: DISABLED
配置状态:
SUCCESS
--此时查看视图htdb1,htdb2,htdb3保护模式已经改变
SQL> select protection_mode from v$database;
PROTECTION_MODE
--------------------
MAXIMUM PERFORMANCE
不同的保护模式对broker操作的影响
1). 当升级保护模式的时候,broker会自动的重启primary数据库。降低保护模式级别的时候是不需要重启数据库的。(11g更改保护模式都不用重启数据库)
2). switchover操作不会改变当前的保护模式。
3). 做手工的failover之后,如果原来保护模式是MaxProtection的话会被自动降级为MaxPerformance;如果是其他模式的话则保持不变。
4). fast-start failover所作的自动的failover操作不会改变数据库的保护模式。
5). 做disable操作或remove database之前,broker会检查disable之后是否还能保证满足当前的保护模式,如果不能的话disable/remove会失败。
6). fast-start failover启用的是很不能做disable configuration操作。
数据库监控状态查看
broker会自动的收集同一个配置之下的所有数据库的健康状态,管理员只需要通过简单的show命令就可以查看数据库的状态了。命令格式如下
show database db_unique_name statue_name可用的状态命令列表如下:
StatusReport
显示所有broker检查到的问题
LogXptStatus
显示日志传送的状态
InconsistentProperties
显示不一致的数据库属性
InconsistentLogXptProps
显示不一致的日志传送设定
DGMGRL> show database htdb1 statusreport
STATUS REPORT
INSTANCE_NAME SEVERITY ERROR_TEXT
DGMGRL> show database htdb1 LogXptStatus
LOG TRANSPORT STATUS
PRIMARY_INSTANCE_NAME STANDBY_DATABASE_NAME STATUS
htdb1 htdb2
htdb1 htdb3
· 3.数据库角色转换
数据库转换的基本概念
转换的类型
数据库之间的转换有switchover和failover两种方式。
Switchover:
switchover是primary数据库和它的一个standby数据库之间角色的切换,通常是有计划的数据库转换,保证不会有数据丢失。
Failover:
failover发生在primary数据库失败之后,它的一个standby接替它成为primary数据库。failover通常发生primary数据库不可恢复的情况下,根据数据库保护模式的不一样failover可能会有数据丢失。
转换目标的选择
对于switchover操作来说,遵循以下的步骤:
1).首先选择未应用的redo的standby,这个可以通过SHOW DATABASE db_unique_name RecvQEntries看到。
2).对于物理和逻辑standby同时存在时,优先选择redo apply queue最小的物理standby,因为物理standby在转换之后所有的standby都能正常工作,而转换到逻辑standby之后同一组里面的物理standby将要重建。
对failover操作来说,遵循以下的步骤:
1).为降低数据丢失的数量,首先要选择应用日志最多的standby。
2).对于物理和逻辑standby同时存在时,优先选择物理standby,因为物理standby在转换之后所有的standby都能正常工作,而转换到逻辑standby之后同一组里面的standby将要重建。另外一个如果逻辑standby使用DBMS_LOGSTDBY.SKIP忽略了一部分数据库话也会造成数据丢失。
Data Guard转换的三个层次
第一个层次是在没有配置broker的环境中,在这种环境下,如果要进行数据库的角色却换的话通常需要3个步骤:
1).首先是检查data guard环境中的数据库是否满足转换的条件。
2).然后登陆到primary数据库运行sql转换角色,再重启primary数据库使其变成standby。
3).再登录到要转换的standby数据库上,运行sql转换角色,再重新启动standby以变成新的primary。
第二个层次是配置了broker但是没有配置FSF(fast-start failover)的环境中,在这里做switchover和failover都只需要一个简单的命令,剩下的重启primary和standby的操作就交给broker去做了。
第三个层次是配置了FSF的机器,这时候数据库的状态由FSF Observer监控着,一旦primary数据库出现了问题需要failover操作,FSF会自动进行数据库的转换,根本就不需要人来参与了。
broker管理switchover和failover
Switchover:
broker管理下的switchover的过程
1).检查primary和standby是否online,是否有错误,如果有错误则switchover失败。
2).如果primary是RAC,则关掉RAC中所有不参与switchover的instance。
3).将primary数据库转换成standby数据库,然后将目标standby数据库转换成新的primary数据库。
4).更新broker控制文件记录转换之后的数据库角色信息。
5).如果新的standby是物理standby的话将会重启之,然后开始redo log应用。RAC环境中将会重启那些被关闭的instance。
6).如果是物理standby环境的话重启新的primary数据库然后开始rodo log的传送到其他的standby中。
最后broker会确认转换之后的新primary和standby都工作正常,redo log传送和应用都正常。对于那些没有参与switchover的standby将会保持不变。
Switchover实例:
--查看当前数据库状态
DGMGRL> show configuration
配置 - htdb1
保护模式: MaxAvailability
数据库:
htdb1 - 主数据库
htdb3 - 物理备用数据库
htdb2 - 物理备用数据库
快速启动故障转移: DISABLED
配置状态:
SUCCESS
--执行switchover切换
DGMGRL> switchover to htdb2
立即执行切换, 请稍候...
新的主数据库 "htdb2" 正在打开...
操作要求关闭实例 "htdb1" (在数据库 "htdb1" 上)
正在关闭实例 "htdb1"...
ORACLE 例程已经关闭。
操作要求启动实例 "htdb1" (在数据库 "htdb1" 上)
正在启动实例 "htdb1"...
无法连接到数据库
ORA-12514: TNS: 监听程序当前无法识别连接描述符中请求的服务
失败。
警告: 您不再连接到 ORACLE。
请执行以下步骤以完成切换:
启动实例 "htdb1" (属于数据库 "htdb1")
--此时查看htdb1的alert日志
Switchover: Primary controlfile converted to standby controlfile succesfully.
Switchover: Complete - Database shutdown required
Completed: ALTER DATABASE COMMIT TO SWITCHOVER TO PHYSICAL STANDBY WITH SESSION SHUTDOWN
Thu Sep 22 14:53:35 2011
Performing implicit shutdown abort due to switchover to physical standby
Shutting down instance (abort)
License high water mark = 13
USER (ospid: 9909): terminating the instance
Instance terminated by USER, pid = 9909
Thu Sep 22 14:53:39 2011
Instance shutdown complete
ORA-1092 : opitsk aborting process
--启动实例 htdb1
[oracle@hotel01 trace]$ !sql
sqlplus "/as sysdba"
SQL*Plus: Release 11.2.0.2.0 Production on 星期四 9月 22 14:55:01 2011
Copyright (c) 1982, 2010, Oracle. All rights reserved.
已连接到空闲例程。
SQL> startup
ORACLE 例程已经启动。
Total System Global Area 2438529024 bytes
Fixed Size 2228920 bytes
Variable Size 1828719944 bytes
Database Buffers 587202560 bytes
Redo Buffers 20377600 bytes
数据库装载完毕。
数据库已经打开。
--查看数据库状态
Htdb1:
SQL> select open_mode from v$database;
OPEN_MODE
--------------------
READ ONLY WITH APPLY
Htdb2:
SQL> select open_mode from v$database;
OPEN_MODE
--------------------
READ WRITE
DGMGRL> show configuration
配置 - htdb1
保护模式: MaxAvailability
数据库:
htdb2 - 主数据库
htdb1 - 物理备用数据库
htdb3 - 物理备用数据库
快速启动故障转移: DISABLED
配置状态:
SUCCESS
Failover:
failover有两种类型:完全failover和立即failover。
完全failover:
进行完全failover操作的是很broker会竟可能的恢复数据,同时在failover完成之后会根据情况尽可能的将没有参与failover的standby变成新的primary的可用的standby。
立即failover:
立即failover的操作开始之后broker不再去试图恢复更多的数据,另一个就是failover完成之后所有没有参与failover的standby都要重新启用。
调用这两种failover的命令如下
-- 完全failover
FAILOVERTOstandby_database_name;
-- 立即failover
FAILOVERTOstandby_database_nameIMMEDIATE;
broker执行完全failover的过程
1).检查primary是否可用,可用的话给出一条警告信息。
2).确认目标standby可用,不可用的话failover失败。RAC环境中将关闭standby的其他不参与的instance。
3).等待目标standby完成还在队列中的redo信息之后关闭redo log apply或是sql apply。
4).将目标standby转换成新的primary。
将新的primary数据库打开为读写模式。
检查其他的standby是否能成为新primary的standby,如果可以的话则该standby的状态保证不变,否则则需要re-enable。
启动redo传送服务将redo传送给那些不需要re-enable的standby数据库。
5).如果是RAC环境则重启那些之前关闭的instance。
broker执行立即failover的过程
1).确认目标standby可用,不可用的话failover失败。RAC环境中将关闭standby的其他不参与的instance。
2).立即停止redo log apply或是sql apply,不管是否还有可恢复的数据,这样可能会造成数据丢失。
3).将目标standby转换成新的primary并打开到读写模式,并启动redo传送服务。
实例:完全failover
--查看数据库当前状态
DGMGRL> show configuration
配置 - htdb1
保护模式: MaxAvailability
数据库:
htdb2 - 主数据库
htdb1 - 物理备用数据库
htdb3 - 物理备用数据库
快速启动故障转移: DISABLED
配置状态:
SUCCESS
--现在模拟主库故障,停止htdb2
SQL> shutdown immediate
数据库已经关闭。
已经卸载数据库。
ORACLE 例程已经关闭。
--故障转移failover
DGMGRL> failover to htdb1
立即执行故障转移, 请稍候...
故障转移成功, 新的主数据库为 "htdb1"
--再次查看状态
DGMGRL> show configuration
配置 - htdb1
保护模式: MaxAvailability
数据库:
htdb1 - 主数据库
htdb3 - 物理备用数据库
htdb2 - 物理备用数据库 (禁用)
ORA-16661: 需要恢复备用数据库
快速启动故障转移: DISABLED
配置状态:
SUCCESS
角色转换之后的数据库的启用
在角色转换之后我们可能还需要进行额外的操作来启用被禁用的数据库,操作已经data guard的类型不同需要启用数据库情况也不同。
| 转换操作 |
reinstate或recreate 有问题的primary数据库 |
重新启用没有参与failover的standby |
| switchover到物理standby |
不需要其他操作 |
不需要其他操作 |
| switchover到逻辑standby |
不需要其他操作 |
所有物理standby需要recreate |
| 完全failover到物理standby |
如果启用了flashback而且retention足够的话可以reinstate,否则只能recreate |
对于物理standby如果启用了flashback而且retention足够的话可以reinstate,否则只能recreate |
| 完全failover逻辑standby |
如果启用了flashback而且retention足够的话可以reinstate,否则只能recreate |
所有standby都会被disabled,都需要recreate |
| 立即failover到物理standby或逻辑standby |
必须要recreate |
所有standby都会被disabled,都需要recreate |
Reinstate:
在broker中进行reinstate数据库操作只需要运行一个命令就行了,不过前提是配置了flashback以及足够的retention。
REINSTATEDATABASEdb_unique_name;
基本步骤是:
1).重启数据库到mount状态
2).使用dgmgrl连接到primary数据库
3).运行REINSTATE DATABASE命令
下面对上一步failover之后的新standby((禁用))做一次reinstate操作
--查看当前数据状态
DGMGRL> show configuration
配置 - htdb1
保护模式: MaxAvailability
数据库:
htdb1 - 主数据库
htdb3 - 物理备用数据库
htdb2 - 物理备用数据库 (禁用)
ORA-16661: 需要恢复备用数据库
快速启动故障转移: DISABLED
配置状态:
SUCCESS
--reinstate操作
实例reinstate:
DGMGRL> show configuration
配置 - htdb1
保护模式: MaxAvailability
数据库:
htdb2 - 主数据库
htdb1 - 物理备用数据库 (禁用)
ORA-16661: 需要恢复备用数据库
htdb3 - 物理备用数据库
快速启动故障转移: DISABLED
配置状态:
SUCCESS
DGMGRL> reinstate database htdb1
正在恢复数据库 "htdb1", 请稍候...
操作要求关闭实例 "htdb1" (在数据库 "htdb1" 上)
正在关闭实例 "htdb1"...
ORA-01109: 数据库未打开
已经卸载数据库。
ORACLE 例程已经关闭。
操作要求启动实例 "htdb1" (在数据库 "htdb1" 上)
正在启动实例 "htdb1"...
无法连接到数据库
ORA-12514: TNS: 监听程序当前无法识别连接描述符中请求的服务
失败。
警告: 您不再连接到 ORACLE。
请完成以下步骤并重新发出 REINSTATE 命令:
启动并装载实例 "htdb1" (属于数据库 "htdb1")
--启动htdb1实例
SQL> startup mount
ORACLE 例程已经启动。
Total System Global Area 2438529024 bytes
Fixed Size 2228920 bytes
Variable Size 1828719944 bytes
Database Buffers 587202560 bytes
Redo Buffers 20377600 bytes
数据库装载完毕。
DGMGRL> reinstate database htdb1
正在恢复数据库 "htdb1", 请稍候...
已成功恢复数据库 "htdb1"
DGMGRL> show configuration
配置 - htdb1
保护模式: MaxAvailability
数据库:
htdb2 - 主数据库
htdb1 - 物理备用数据库
htdb3 - 物理备用数据库
快速启动故障转移: DISABLED
配置状态:
SUCCESS
· 4.Fast-Start Failover管理
基本概念
Fast-Start Failover是建立在broker基础上的一个快速故障转换的机制,通过fast-start failover可以自动检测primary的故障,然后自动的failover到预先指定的standby上面,这样可以最大化的减少故障时间,提高数据库的可用性。
结构
Fast-Start Failover是在broker的基础上再增加了一个单独的observer,用来监控primary和standby数据库的状态,一旦primary不可用,observer就会自动的切换到指定的standby上面。
准备工作
1.确保broker配置为运行在MaxAvailability或MaxPerformance模式。
2.如果在MaxAvailability模式,主库和FSF目标的备库的LogXptMode属性必需设为SYNC
3.如果在MaxMaxPerformance模式,主库和fsf目标的备库的LogXptMode属性必需设为ASYNC。
4.在primary和standby机器上都启用flashback database,这个在reinstate failed的数据库的时候要用。
5.在运行observer的机器上安装DGMGRL工具,用于启动observer。
6.配置tnsname.ora文件,保证observer能正常的连接到primary和standby数据库上面。
7.确保存在有效的FSF standby目标。
配置及启用Fast-Start Failover
在满足上面的条件之后在经过下面少许的配置就可以启用Fast-Start Failover了。
1.配置每个数据库Failover的目标,这一步是决定当数据库出问题之后会自动failover到那个standby。
DGMGRL> edit database htdb1 set property FastStartFailoverTarget='htdb2';
已更新属性 "faststartfailovertarget"
2.设定FastStartFailoverThreshold值,这个设置是决定了primary坏了多长时间之后会执行自动的failover操作,这里我们设置的是30s。
DGMGRL> edit database htdb1 set property FastStartFailoverThreshold = 30;
已更新属性FastStartFailoverThreshold
3.启用Fast-Start Failover。
DGMGRL> enable fast_start failover
已启用。
4.在htdb2节点启动observer。
DGMGRL> start observer;
观察程序已启动
5.查看broker状态
DGMGRL> show configuration verbose
配置 - htdb1
保护模式: MaxAvailability
数据库:
htdb1 - 主数据库
htdb2 - (*) 物理备用数据库
htdb3 - 物理备用数据库
(*) 快速启动故障转移目标
属性:
FastStartFailoverThreshold = '30'
OperationTimeout = '30'
FastStartFailoverLagLimit = '30'
CommunicationTimeout = '180'
FastStartFailoverAutoReinstate = 'TRUE'
FastStartFailoverPmyShutdown = 'TRUE'
BystandersFollowRoleChange = 'ALL'
快速启动故障转移: ENABLED
阈值: 30 秒
目标: htdb2
观察程序: hotel01
滞后限制: 30 秒 (未使用)
关闭主数据库: TRUE
自动恢复: TRUE
配置状态:
SUCCESS
Fast-Start Failover工作过程及实例
在启用了fast-start failover和observer之后,broker会来监控primary和standby数据库的状态,一旦primary数据库出现故障,observer会根据一定的程序来执行自动的failover操作。
1.当发生下列情形是observer会尝试启动failover操作
Ø observer和primary数据库之间连接出现故障时
Ø 当primary数据库故障或者是RAC环境中所有instance都故障时
Ø 执行SHUTDOWN ABORT之后,特别注意正常的SHUTDOWN操作(NORMAL,IMMEDIATE,TRANSACTIONAL)不会引发 failover操作
Ø 数据库文件OFFLINE
除了最后一个数据库文件OFFLINE的情形,其他的情况下observer都会尝试在FastStartFailoverThreshold制定的时间之内重新连接数据库,如果还是无法连接之后才会执行自动failover操作。
2.在FastStartFailoverThreshold指定的时间内重新连接数据库,在RAC环境中会尝试连接其他的instance。
3.尝试时间结束后,observer将确定目标standby可用。下面的这些情形会导致failover失败
Ø fast-start failover没有启用
Ø observer无法连接到standby数据库
Ø standby与observer中记录的状态不一致
Ø observer在primary fail的时候正好没有运行,再次启动之后只能找到一个standby
Ø 目标standby没有和primary完成同步
Ø 目标standby是逻辑standby时,在V$DATABASE中显示LOADING DICTIONARY时
Ø 目标standby还能和primary正常通讯时
Ø 在V$DATABASE的列FS_FAILOVER_STATUS中显示了其他无法进行failover操作时
Ø 有手工failover正在进行时
4.执行failover操作,使目标standby变成新的primary。
5.reinstate之前失败的primary
FSFO实例:
--查看当前状态
DGMGRL> show configuration
配置 - htdb1
保护模式: MaxAvailability
数据库:
htdb1 - 主数据库
htdb2 - (*) 物理备用数据库
htdb3 - 物理备用数据库
快速启动故障转移: ENABLED
配置状态:
SUCCESS
--然后登录到主库htdb1上,执行一个SHUTDOWN ABORT命令
SQL> shutdown abort
ORACLE 例程已经关闭。
--然后在前面htdb2启动observer的会话里面我们可以看到自动failover信息了
DGMGRL> start observer
观察程序已启动 --在前面开启的会话里会一直停在这里
……
15:39:40.14 2011年9月30日 星期五
正在为数据库 "htdb2" 启动快速启动故障转移...
立即执行故障转移, 请稍候...
故障转移成功, 新的主数据库为 "htdb2"
15:40:18.15 2011年9月30日 星期五
……
--再看下状态,主库变成了htdb2,htdb1是禁用状态
DGMGRL> show configuration verbose
配置 - htdb1
保护模式: MaxAvailability
数据库:
htdb2 - 主数据库
警告: ORA-16817:快速启动故障转移配置不同步
htdb1 - (*) 物理备用数据库 (禁用)
ORA-16661: 需要恢复备用数据库
htdb3 - 物理备用数据库
(*) 快速启动故障转移目标
属性:
FastStartFailoverThreshold = '30'
OperationTimeout = '30'
FastStartFailoverLagLimit = '30'
CommunicationTimeout = '180'
FastStartFailoverAutoReinstate = 'TRUE'
FastStartFailoverPmyShutdown = 'TRUE'
BystandersFollowRoleChange = 'ALL'
快速启动故障转移: ENABLED
阈值: 30 秒
目标: htdb1
观察程序: hotel02
滞后限制: 30 秒 (未使用)
关闭主数据库: TRUE
自动恢复: TRUE
配置状态:
WARNING
--启动htdb1到mount状态,
SQL> startup mount
ORACLE 例程已经启动。
Total System Global Area 2438529024 bytes
Fixed Size 2228920 bytes
Variable Size 1828719944 bytes
Database Buffers 587202560 bytes
Redo Buffers 20377600 bytes
数据库装载完毕。
--此时再观察前面htdb2启动observer的会话的信息
DGMGRL> start observer
观察程序已启动
15:39:40.14 2011年9月30日 星期五
正在为数据库 "htdb2" 启动快速启动故障转移...
立即执行故障转移, 请稍候...
故障转移成功, 新的主数据库为 "htdb2"
15:40:18.15 2011年9月30日 星期五
--下面是mount htdb1时observer会话的信息
15:54:24.50 2011年9月30日 星期五
正在为数据库 "htdb1" 启动恢复过程...
正在恢复数据库 "htdb1", 请稍候...
操作要求关闭实例 "htdb1" (在数据库 "htdb1" 上)
正在关闭实例 "htdb1"...
ORA-01109: 数据库未打开
已经卸载数据库。
ORACLE 例程已经关闭。
操作要求启动实例 "htdb1" (在数据库 "htdb1" 上)
正在启动实例 "htdb1"...
无法连接到数据库
ORA-12514: TNS: 监听程序当前无法识别连接描述符中请求的服务
失败。
警告: 您不再连接到 ORACLE。
请完成以下步骤并重新发出 REINSTATE 命令:
启动并装载实例 "htdb1" (属于数据库 "htdb1")
15:55:04.92 2011年9月30日 星期五
--再次启动htdb1到mount状态
SQL> startup mount
ORACLE 例程已经启动。
Total System Global Area 2438529024 bytes
Fixed Size 2228920 bytes
Variable Size 1828719944 bytes
Database Buffers 587202560 bytes
Redo Buffers 20377600 bytes
数据库装载完毕。
--执行reinstate操作(在htdb2上)
DGMGRL> reinstate database htdb1
正在恢复数据库 "htdb1", 请稍候...
已成功恢复数据库 "htdb1"
--查看状态已经成功failover
DGMGRL> show configuration verbose
配置 - htdb1
保护模式: MaxAvailability
数据库:
htdb2 - 主数据库
htdb1 - (*) 物理备用数据库
htdb3 - 物理备用数据库
(*) 快速启动故障转移目标
属性:
FastStartFailoverThreshold = '30'
OperationTimeout = '30'
FastStartFailoverLagLimit = '30'
CommunicationTimeout = '180'
FastStartFailoverAutoReinstate = 'TRUE'
FastStartFailoverPmyShutdown = 'TRUE'
BystandersFollowRoleChange = 'ALL'
快速启动故障转移: ENABLED
阈值: 30 秒
目标: htdb1
观察程序: hotel02
滞后限制: 30 秒 (未使用)
关闭主数据库: TRUE
自动恢复: TRUE
配置状态:
SUCCESS
--DG管理页面状态
查看Fast-Start Failover状态
通过SHOW CONFIGURATION VERBOSE命令可以查看Fast-Start Failover的基本运行状态
DGMGRL> show configuration verbose
配置 - htdb1
保护模式: MaxAvailability
数据库:
htdb1 - 主数据库
htdb2 - (*) 物理备用数据库
htdb3 - 物理备用数据库
(*) 快速启动故障转移目标
属性:
FastStartFailoverThreshold = '30'
OperationTimeout = '30'
FastStartFailoverLagLimit = '30'
CommunicationTimeout = '180'
FastStartFailoverAutoReinstate = 'TRUE'
FastStartFailoverPmyShutdown = 'TRUE'
BystandersFollowRoleChange = 'ALL'
快速启动故障转移: ENABLED
阈值: 30 秒
目标: htdb2
观察程序: hotel02
滞后限制: 30 秒 (未使用)
关闭主数据库: TRUE
自动恢复: TRUE
配置状态:
SUCCESS
要查看Fast-Start Failover更多的信息就要查看V$DATABASE视图中的相关的列了。
FS_FAILOVER_STATUS
这个列显示了Fast-Start Failover的状态,通过查看这个列我们可以知道数据库时处于什么状态之中,详细的状态信息在这里。
FS_FAILOVER_CURRENT_TARGET
当前数据库的failover的目标数据库
FS_FAILOVER_THRESHOLD
执行自动failover的时间超时值
FS_FAILOVER_observer_PRESENT
是否启动了observer,通过查看这个列我们可以知道是否有observer在监控着这个数据库
FS_FAILOVER_observer_HOST
监控此数据库的observer所在的位置
禁用Fast-Start Failover
禁用Fast-Start Failover的命令为:
DISABLE FAST_START FAILOVER [FORCE]
加上FORCE之后将会强行在执行DISABLE命令的数据库以及这个数据库可连通的其他数据库上面上禁用Fast-Start Failover,而其他无法连接上的数据库将保持原来的状态;不加FROCE时如果有那个数据库暂时无法连接的话那么DISABLE操作将会失败。所以在当primary和standby数据库的网络连接良好的情况下要使用不带FORCE的命令。
通常需要使用FORCE的情形
Ø 当因为网络问题造成primary无法和observer及那些已完成同步的standby通讯时,primary将会停止工作,如果primary的恢复时间可期,且想要primary继续工作的话就需要使用FORCE选项暂时在primary上禁用fast-start failover,不过之前一定要检查看数据库有没有自动failover。
Ø 当primary和standby没有完成同步的时候想要手工的执行failover的命令,在fast-start failover启用的时候是无法执行的,这时候也需要使用FORCE选项强行禁用fast-start failover。
Ø 在fast-start failover失败之后还想将数据库failover到其他可用的standby上时也需要先使用FORCE强制禁用fast-start failover然后在手工进行failover操作。
Ø 如果确定有问题的primary可以很快的恢复,此时不想让fast-start failover自动failover,也可以使用FORCE选项强行禁用fast-start failover。
Observer管理
启用observer的操作很简单,使用DGMGRL连接到数据库,然后执行START OBSERVER命令就行了。
要启动observer的话必须使用SYS连接到DGMGRL,同一时间只能启动一个observer,如果尝试启动多个observer将会收到这样的消息
ORA-16647: could not start more than one observer
要停止一个observer的话只需要用DGMGRL连接到数据库,然后执行STOP OBSERVER命令就行了。
要确定一个数据库是否在observer的监视中必须要去查看V$DATABASE视图中的FS_FAILOVER_OBSERVER_PRESENT和FS_FAILOVER_OBSERVER_HOST。只有当FS_FAILOVER_OBSERVER_PRESENT为YES的时候才说明这个数据库时处于observer的监控之中。
同时数据库是否有observer监视这个信息我们也可以从DGMGRL中查看到
DGMGRL> show database htdb2 statusreport
STATUS REPORT
INSTANCE_NAME SEVERITY ERROR_TEXT
* ERROR ORA-16820: 快速启动故障转移观察程序不再对此数据库进行观察
在启动observer的时候,observer会自动的在当前目录中生成一个默认名字为fsfo.dat的二进制文件,这个文件里面保存了fast-start failover的配置信息,同时也包含了到primary和standby的连接方式。也可以在启动observer的时候使用FILE参数指定配置文件的位置,命令如下
STARTOBSERVER [FILE=<observerconfigurationfile>];
--内容如下
[oracle@hotel01 ~]$ ls -l fsfo.dat
-rw------- 1 oracle oinstall 322 09-30 15:07 fsfo.dat
[oracle@hotel01 ~]$ cat fsfo.dat
vE懑_贪#htdb1htdb2t(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=hotel01)(PORT=1521))(CONNECT_DATA=(SERVICE_NAME=htdb1)(SERVER=DEDICATED)))t(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=hotel02)(PORT=1521))(CONNECT_DATA=(SERVICE_NAME=htdb2)(SERVER=DEDICATED)))vE懑_贪
· 5.Troubleshooting
(1)通过EM重建物理备库失败问题解决
环境:DB:oracle 11gR2 dataguard OS:oracle linux 5.6
问题:
在DG环境中,当我们进行failover转换后,如果原来的主库没有开闪回功能,则主库不能用broker的reinstate命令或PL/SQL的flashback命令恢复成新主库的物理备库,所以只能再重新建一个新的物理备库。
但是我在删除(drop database )原来failover以后的主库后,通过Grid control EM页面建新的物理备时,遇到下面的问题:
a).在最后一步创建物理备库时失败
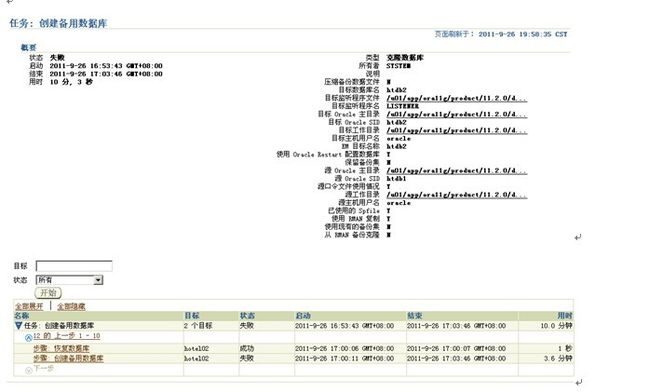
b).备库状态
--创建完成后alert.log出现下面的错误:
Mon Sep 26 17:11:21 2011
alter database flashback on
Errors in file /u01/app/ora11g/diag/rdbms/htdb2/htdb2/trace/htdb2_ora_18431.trc:
ORA-38706:无法启用 FLASHBACK DATABASE 事件记录。
ORA-38788:需要更多的备用数据库恢复
ORA-38706 signalled during: alter database flashback on...
--尝试open数据库
SQL>select open_mode from v$database;
-------------
Mount
SQL>alter database open;
Errors in file /u01/app/ora11g/diag/rdbms/htdb2/htdb2/trace/htdb2_ora_26454.trc:
ORA-10458: standby database requires recovery
ORA-01152:文件 1 没有从过旧的备份中还原
ORA-01110:数据文件 1: '+DATA/htdb2/datafile/system.261.762866019
--此时alter.log出现下面的错误:
alter database open
Data Guard Broker initializing...
Data Guard Broker initialization complete
Signalling error 1152 for datafile 1!
Beginning standby crash recovery.
Serial Media Recovery started
Managed Standby Recovery starting Real Time Apply
Media Recovery Waiting for thread 1 sequence 45
FAL[client]: Error fetching gap sequence, no FAL server specified
FAL[client]: Failed to request gap sequence
GAP - SCN range: 0x0000.00585a00 - 0x0000.00585a00
DBID 1139129460 branch 762535446
FAL[client]: All defined FAL servers have been attempted.
-------------------------------------------------------------
Check that the CONTROL_FILE_RECORD_KEEP_TIME initialization
parameter is defined to a value that is sufficiently large
enough to maintain adequate log switch information to resolve
archivelog gaps.
-------------------------------------------------------------
Mon Sep 26 12:44:21 2011
Standby crash recovery need archive log for thread 1 sequence 45 to continue.
Please verify that primary database is transporting redo logs to the standby database.
Wait timeout: thread 1 sequence 45
Standby crash recovery aborted due to error 16016.
Errors in file /u01/app/ora11g/diag/rdbms/htdb2/htdb2/trace/htdb2_ora_26454.trc:
ORA-16016:线程 1 sequence# 45 的归档日志不可用
Recovery interrupted!
Completed standby crash recovery.
Signalling error 1152 for datafile 1!
Errors in file /u01/app/ora11g/diag/rdbms/htdb2/htdb2/trace/htdb2_ora_26454.trc:
ORA-10458: standby database requires recovery
ORA-01152:文件 1 没有从过旧的备份中还原
ORA-01110:数据文件 1: '+DATA/htdb2/datafile/system.261.762866019'
ORA-10458 signalled during: alter database open...
--通过以上日志发现有些参数没有配置
SQL> show parameter log_archive_config
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
log_archive_config string
SQL> show parameter fal_server
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
fal_server string
c).主库状态:
--查看主库alter.log,发现主库archive不能传输到备库。
FAL[server, ARC0]: FAL archive failed, see trace file.
ARCH: FAL archive failed. Archiver continuing
ORACLE Instance htdb1 - Archival Error. Archiver continuing.
Mon Sep 26 17:52:02 2011
FAL[server, ARC0]: FAL archive failed, see trace file.
ARCH: FAL archive failed. Archiver continuing
ORACLE Instance htdb1 - Archival Error. Archiver continuing.
d).broker状态:
DGMGRL> show configuration
配置 - htdb1
保护模式: MaxAvailability
数据库:
htdb1 -主数据库
htdb3 -物理备用数据库
htdb2 - 物理备用数据库(禁用)
快速启动故障转移: DISABLED
配置状态:
WARNING
解决:
1.修改备库的参数
SQL>ALTER SYSTEM SET fal_server='(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=hotel01)(PORT=1521))(CONNECT_DATA=(SERVICE_NAME=htdb1)(SERVER=DEDICATED)))';
SQL>ALTER SYSTEM SET log_archive_config='dg_config=(htdb3,htdb1,htdb2)';
2.通过broker启动管理备库
DGMGRL> ENABLE DATABASE htdb2
--此时可以看到备库alter.log已经收到主库的归档
Mon Sep 26 19:49:01 2011
RFS[2]: Completed archive log 3 thread 1 sequence 69 (htdb2)
Mon Sep 26 19:49:01 2011
ARC3: Evaluating archive log 4 thread 1 sequence 69
ARC3: Beginning to archive thread 1 sequence 69 (5824304-5832872) (htdb2)
ARC3: Creating local archive destination LOG_ARCHIVE_DEST_2: '/u01/app/ora11g/product/11.2.0/db_1/dbs/dgsby1_69_762535446.dbf' (thread 1 sequence 69) (htdb2)
ARC3: Creating local archive destination LOG_ARCHIVE_DEST_1: '+FRA' (thread 1 sequence 69) (htdb2)
Mon Sep 26 19:49:01 2011
ARC0: Evaluating archive log 4 thread 1 sequence 69
ARC0: Unable to archive thread 1 sequence 69
Log actively being archived by another process
Mon Sep 26 19:49:02 2011
Media Recovery Waiting for thread 1 sequence 70
ARC3: Closing local archive destination LOG_ARCHIVE_DEST_2: '/u01/app/ora11g/product/11.2.0/db_1/dbs/dgsby1_69_762535446.dbf' (htdb2)
Committing creation of archivelog '/u01/app/ora11g/product/11.2.0/db_1/dbs/dgsby1_69_762535446.dbf'
ARC3: Closing local archive destination LOG_ARCHIVE_DEST_1: '+FRA/htdb2/archivelog/2011_09_26/thread_1_seq_69.540.762896941' (htdb2)
Committing creation of archivelog '+FRA/htdb2/archivelog/2011_09_26/thread_1_seq_69.540.762896941'
Archived Log entry 6 added for thread 1 sequence 69 ID 0x441cdff7 dest 1:
Archived Log entry 7 added for thread 1 sequence 69 ID 0x441cdff7 dest 2:
--查看配置发现broker的属性与数据库不一致
DGMGRL> show configuration
配置 - htdb1
保护模式: MaxAvailability
数据库:
htdb1 -主数据库
htdb3 -物理备用数据库
htdb2 -物理备用数据库
警告: ORA-16792:可配置属性的值与数据库设置不一致
快速启动故障转移: DISABLED
配置状态:
WARNING
--具体查看哪些属性不一致
DGMGRL> show database verbose htdb2
数据库 - htdb2
Enterprise Manager名称:
角色: PHYSICAL STANDBY
预期状态: APPLY-ON
传输滞后: 0 秒
应用滞后: 0 秒
实时查询: ON
实例:
htdb2
警告: ORA-16714: 属性 LogFileNameConvert的值与数据库设置不一致
警告: ORA-16714: 属性 LogArchiveFormat的值与数据库设置不一致
……
3.修改为与数据库一致的属性
DGMGRL> edit database htdb2 set property 'LogArchiveFormat'='%t_%s_%r.dbf';
已更新属性 "LogArchiveFormat"
DGMGRL> edit database htdb2 set property 'LogFileNameConvert'='null, null';
已更新属性 "LogFileNameConvert"
--再次查看配置正常
DGMGRL> show configuration
配置 - htdb1
保护模式: MaxAvailability
数据库:
htdb1 -主数据库
htdb3 -物理备用数据库
htdb2 -物理备用数据库
快速启动故障转移: DISABLED
配置状态:
SUCCESS
4.解决EM页面不一致问题
--此时在EM页面发现物理备库还于“未知”状态,当尝试“移去”htdb2配置时,出现下面的错误,此时不能进行EM页面“移去”、“添加备用数据库”操作:

--此时用remover命令可删除htdb2的broker配置
DGMGRL> remove database htdb2
已从配置中删除数据库 "htdb2"
--然后再通过EM页面“添加备用数据库”(或是使用ADD DATABASE命令)
->使用 Data Guard中介管理现有备用数据库
->选择htdb2数据库,再重新进行Broker的配置。
这时可以看到EM页面状态正常了

总结:
1. 在物理备库删除重建时,如果之前使用了broker进行DG的管理,可能会有些配置不能彻底的删除,再重建时就会出现问题,即数据库与broker配置不一致的问题。
2. 当出现问题我们可以通过数据库的alter.log日志、broker的dr.log进行分析错误,然后可以通过SQL命令、broker命令、EM页面综合来解决问题。在一种方法不能解决时,可以通过另一种方法来代替和补充,来提高解决问题的速度。