用数据说话:北京房价数据背后的数据
从2014年对楼市的普遍唱衰,到2015年的价格回暖,到底发生了怎样的改变?本文就尝试通过大数据来和丰富的图表,为大家展现数据背后的数据。
- 数据采集采用笔者用C#开发的爬虫工具。
- 数据清洗ETL采用了笔者开发的工具软件。
- 数据分析采用ipython notebook和pandas
- 可视化使用了matplotlib和seaborn.
- 热力图使用了百度地图API, 按经纬度0.01度为一个子区域,计算其中的平均值作为当前区域的房价/二手房数量。
至于搭建ipython notebook和安装相应类库的操作,以及各个类库使用方法,可参考相应的教程。
之前曾发表在博客园首页后被撤回,应管理员要求进行修改,重新发布。
数据来源
这些数据是笔者在2014年10月年和2015年10月份两次,在链家官网上抓取的在售二手房数据,2014年约为64000条,2015年总计约7W条。数据源可能会有偏差,因此结论仅供参考。附件有前1W条样例数据,可供下载。
首先我们导入所需的类库:
# -*- coding:utf-8 -*- import mongo; import pandas as pd; import csv; from pandas import DataFrame,Series
之后加载所需的数据:
table2014 = pd.read_table("LJ2014.txt",encoding='utf-8',engine='python',quoting=csv.QUOTE_NONE)
table2015 = pd.read_table("LJ2015.txt",encoding='utf-8',engine='python',quoting=csv.QUOTE_NONE)
table2014[u'小区名']=table2014[u'小区名'].map(lambda x:unicode(x).strip("'"))
table2014[u'区县']=table2014[u'区县'].map(lambda x:unicode(x).strip("'"))
table2014[u'楼名']=table2014[u'楼名'].map(lambda x:unicode(x).strip("'"))
year= table2014[u'年份'].map(lambda x:str(x).split('/')[0])
table2014[u'小区']=table2014[u'位置'].map(lambda x:unicode(x).strip("'"))
疯长的房价
从1992年到2015年,北京的房价经历了怎样的疯狂?可以查看下面的图表。
![]()

可以看到,1992年到2002年,呈现一个非常稳定的状态。从2008年起,北京的房价如同火箭一般上窜。

有意思的是,如果按照建造时间来绘制图表,会发现在2000年和2004年左右,达到高峰。在6W套二手房中,2000年总共建造了7697套,占比百分之11.21%。
xcqu2014=table2014.groupby(by=u'位置') p=year.value_counts(); p=p.sort_index()[50:-1] p.plot(title=u'北京各年建造房屋数量变化')
![]()

到了2014年,北京各个区县的二手房价格如下图:
areag=table2014.groupby(by=u'区县') areag[u'价格'].mean().order(ascending=True).plot(kind='barh',title=u'各城区的二手房平均房价')
![]()
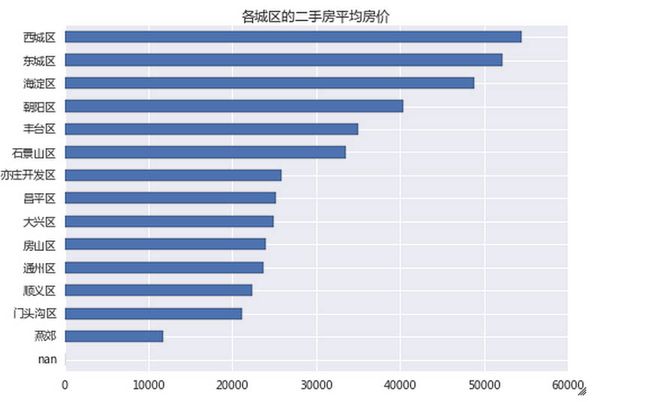
西城区和东城区的平均价格在五万五左右,之所以没有达到网上其他数据所提到的丧心病狂的9万,是因为我们分析的是二手房。目前二环内新楼盘的数量极少,几乎没有讨论的价值。
我们将房价以热力图方式绘制在地图上,就会非常直观:
![]()

颜色越深,代表其价格越高。除了西城,东城这些老城区,中关村(包含大量的学区房)和国贸(北京CBD)都价格高企。

如果我们改变缩放等级,进一步缩小地图范围,可以看到最贵的房子,集中在西单,南锣鼓巷,国贸,以及北新桥地区。
这些最贵小区的房价有多贵呢?下面列出排名前十的十个小区的价格:
xcqu2014[u'价格'].mean().order(ascending=False)[1:10].plot(kind='barh',title=u'价格最高的十个小区的平均房价')

文华胡同的位置在哪里呢?笔者专门去搜索了一下。这个超牛无比,价格在33万/平的文华胡同在靠近闹市口大街的西单商圈。
更夸张的是,两套房子都是平房,面积分别是12平和15平,其中一套还是1949年建的。中介给出的宣传标语是,最牛实验二小学区房,抢抢抢!这么小的面积,估计是四合院的厢房改造的吧。现在官网上已经下架。
什么样的房子最多?
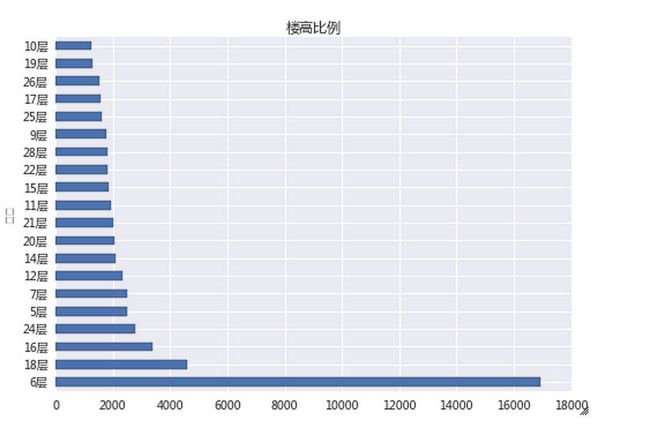
我们先看,什么类型的楼房最多,下面给出了楼房总体高度的比例。可以看到,二手房中,六层是最多的。国家规定,七层就要装电梯了。因此在2000年以前,大部分的居民楼都是6层。
lc=lc=table2014.groupby(by=u'楼层').size();
lc.order(ascending=False)[:20].plot(kind='barh',title=u'楼高比例')
![]()
再看看不同面积的房子所占总数的比例。我们取面积为40-140平米的房子,进行了统计分析,结论如下图:
size=table2014.groupby(by=u'面积').size(); import re; takenum= re.compile('\d+'); size=size[size.index.map(lambda x:takenum.match(x) is not None)] size.index=size.index.map(lambda x:int(x)) size.order(ascending=False)[:100].sort_index().plot(kind='line',title=u'房型面积和对应比例')
首先选出面积值不为空且为数字的所有行,之后将其转换为int类型,后对其进行排序并绘图。
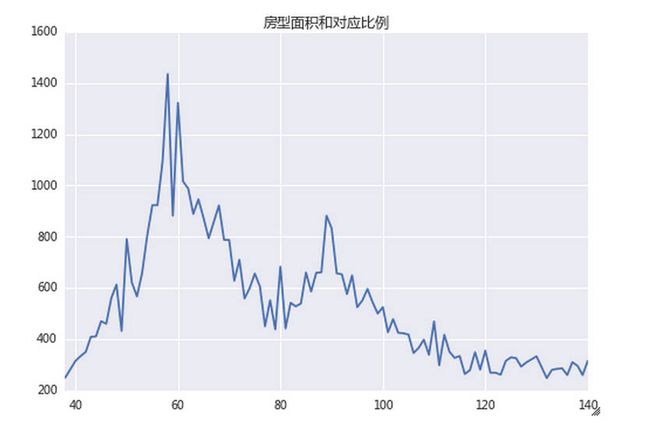
可见,60平的一室一厅或两室一厅最为常见。90平米的三居和两居也较多。
我们再对二手房存量绘制热力图:
![]()
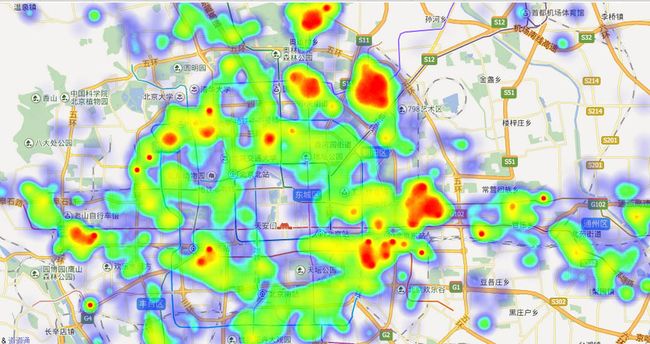
可以看到,二手房主要集中在天通苑,北苑,望京,十里堡和通州。这基本上与北京2004年发布的《北京市城市总体规划2004-2020》的内容相符:
![]()
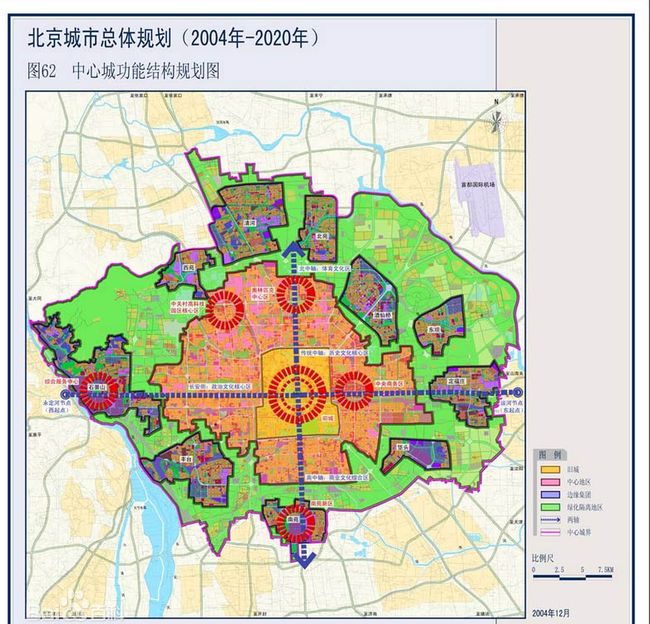
很有意思的是,绿色的区域相当空旷,比如笔者目前所在的三元桥地区,和酒仙桥之间隔了好大一片荒地,晚上夜跑时荒无人烟。
2014年到2015年的房价变化
下面是刚需读者最关心的内容,2014年到2015年的北京房价,经历了怎样的变化?众所周知,2014年房价走低,整体唱衰,甚至有商家打出了降价6000元/平的广告来推销房子。2015年,降准降息政策出炉,公积金贷款比例提高,北京房价回暖,我们知道肯定涨价了。但到底涨了多少呢?
这部分的代码多一些,选取价格少于10万,面积大于四十平米的房子,以减少错误的数据。求出2014年和2015年小区的交集,构造change结构,里面保存了每个小区的房子数量,2014年和2015年的平均价格。
table2014= table2014[(table2014[u'价格']<100000) & (table2014[u'面积']>40)] table2015= table2015[(table2015[u'单价']<100000) & (table2015[u'面积']>40)] xcqu2014=table2014.groupby(by=u'位置') table2015[u'面积']= np.round(table2015[u'总价']*10000/table2015[u'单价']) xcqu2015=table2015.groupby(by=u'小区') p2015=xcqu2015.mean()[u'单价'] p2014=xcqu2014.mean()[u'价格'] xcqumonunt2014=xcqu2014.size() xcqumerge=p2014.index&p2015.index change= DataFrame({'2014': p2014[xcqumerge].values,'2015':p2015[xcqumerge].values,'mount2014':xcqumonunt2014[xcqumerge],'mount2015':xcqumonunt2015[xcqumerge]}) change['diff']=change['2015']-change['2014'] change['percent']= np.round( change['diff']/change['2014']*100.0)
我们按照2014和2015年价格增减的百分比,绘制出下面的房价变化数量比例图。可以看到,房价变化基本呈现正态分布趋势。但均值不在0点,靠近5%左右,整体右移:
change[(change.percent>-30) & (change.percent<50)].groupby(by='percent').size().plot(title=u'不同涨跌幅度房子所占的数量')
![]()
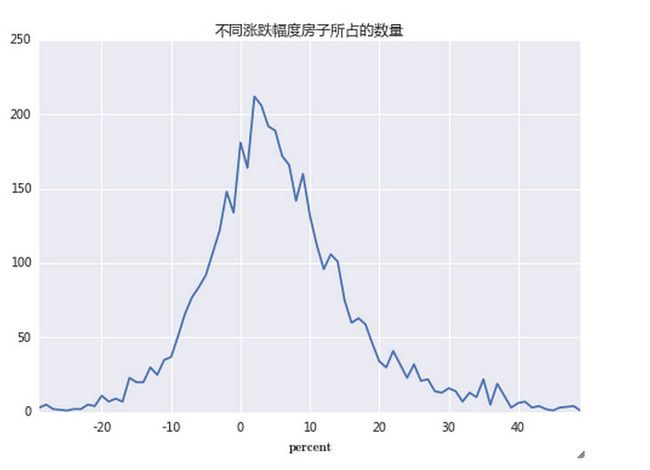
经过统计,2014年的平均房价为40125/平,2015年为42535/平。涨价比例5.64%。也就是说,一套三百万的房子,平均涨了16万左右。
change[(change.percent>-30) & (change.percent<50)].mean(by='percent')
2014 40054.083797
2015 42400.225776 mount2014 15.352119 mount2015 13.466281 diff 2346.141979 percent 5.508430
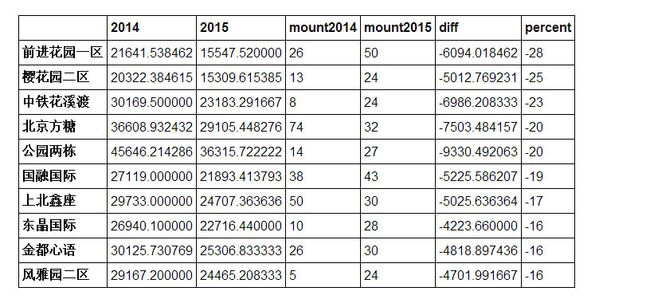
我们列出10万元以下单价,2015年小区内二手房数量超过20套的涨价排名前十的小区:
change[change.mount2015>20].sort(columns='percent',ascending=False)[:10]
![]()
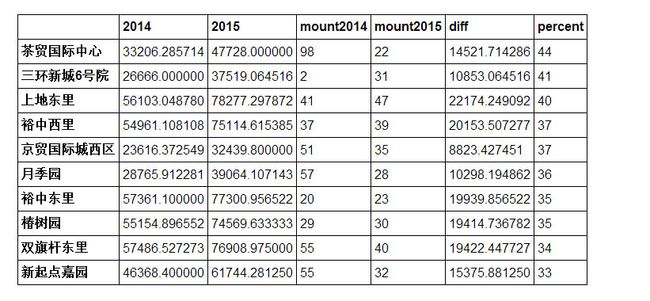
上地房价怎么涨了这么多?即使在北京,7万8的价格都已经是豪宅,可是上地的房子,一般都是普通的住宅。
![]()

原因还是学区房,海淀区教改使得这边的房子变化极大。 上地东里小区内建有上地实验小学,该小学可直升一零一中学上地分校,一零一中学上地分校位于上地西里北侧,就是这9年直升的诱惑导致该区域房价直线攀升。可怜天下父母心!
当然,有涨价就有降价:基本上,降价的小区都在非中心城区,例如樱花园就在顺义。
change[change.mount2015>20].sort(columns='percent',ascending=True)[:10]
结论
5%的涨幅,已经说明2015年比2014年价格回暖不少。也有少部分郊区小区降价。当然,这种涨幅和之前火箭般的涨价不可同日而语。可以肯定的是,像北京这样的城市,房子几乎是不可能大跌的。但未来的事情,谁知道呢?
安得广厦千万间,大庇天下寒士俱欢颜!
文章已经很长,因此没有将更多的内容囊括其中。我们还做了以下的事情:
-
分析不同小区涨降价的原因并将其可视化到地图上。
-
同一个小区中,不同的房子价格差别很大,甚至能差两万元。为什么会出现这种情况?
-
根据房子周边的学校,医院,商场等场所,计算房子的附加价值。
- 尝试预测不同小区未来的房价趋势。
附录:
样例数据下载
链家在去年有约7W条数据,今年的出售二手房已经达到10W套,但是这些房源里有多少水分呢?根据2014年的数据按照编号检查一下重复:一万两千多套房子出现了两次,将近五千套房子出现过三次,甚至有一套房子出现过八次。其中水分可想而知。
同时,2014年的网页数据还会提供地理坐标信息,2015年就不存在了,所以文中涉及到地理信息的图表都是2014年的。另外,虽然对房子的位置描述非常详细,但中介不会告诉你这是几号楼几层。仅仅提供了楼房的总层高。原因不言自明。
同样,数据的准确性也有问题。很多房子价格都是1万,2万,明显是随意标的。也有一部分价格高的离谱,如88万/平。这些数据在处理前都已经筛掉。以免干扰分析结果。