OpenRisc-47-or1200的WB模块分析
引言
“善妖善老,善始善终”,说的是无论什么事情要从有头有尾,别三分钟热度。
对于or1200的流水线来说,MA阶段是最后一个阶段,也是整条流水线的收尾阶段,负责战场的清扫工作。比如,把运算指令的运算结果要写到寄存器里,把从内存读来的数据写到寄存器里,如果在前面的流水阶段出现了异常,WB阶段还要负责把异常指令的地址存到寄存器里。总之呢,就是写回寄存器。
本小节,我们就分析一下or1200五级流水线最后一级,也就是WB(write back)。
1,整体结构
or1200的WB模块,主要包括的rtl文件是or1200_wbmux.v和or1200_rf.v。上面,我们介绍了WB阶段的功能和任务,那么这个模块的整体结构是什么样子的呢?如下所示。
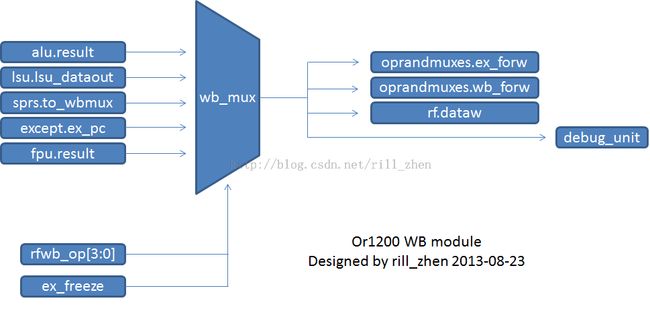
WB模块负责将其他流水阶段的结果写回寄存器堆,而寄存器堆只有一个,所以就需要一个多路选择器(wb_mux)。
wb_mux是一个5选1的多路选择器,指令解码的结果和ex_freeze信号作为多路选择器的选择信号。
需要选择的5路信号分别是:
a,来自运算单元的alu的运算结果和fpu的运算结果(fpu模块,并没有实现)。
b,load指令的处理结果(从内存读来的数据)。
c,异常指令的地址。这个需要说明的是,在采用流水线的cpu结构时,各个流水阶段都可能产生异常,但并不是一旦产生异常后就马上处理,而是把所有流水阶段的异常统一处理,这样才能保证精确异常。
d,来自特殊功能寄存器的数据。
多路选择器的输出:
wb_mux模块的输出,
a,oprandmuxes模块。这个是用作forword的。流水线的forword技术,之前我们曾经介绍过,这里不再赘述。
b,rf模块。这个是显然的,写回阶段,肯定要将数据写回到reg_file里面。
c,调试模块。将输出数据给上述模块的同时,也会送给debug模块,这个是调试单元的需要。
2,wb_mux模块
上面介绍了wb_mux的整体功能,下面我们就是其对应的rtl代码。
module or1200_wbmux( // Clock and reset clk, rst, // Internal i/f wb_freeze, rfwb_op, muxin_a, muxin_b, muxin_c, muxin_d, muxin_e, muxout, muxreg, muxreg_valid ); parameter width = 32; // // Internal wires and regs // reg [width-1:0] muxout; reg [width-1:0] muxreg; reg muxreg_valid; // // Registered output from the write-back multiplexer // always @(posedge clk or `OR1200_RST_EVENT rst) begin if (rst == `OR1200_RST_VALUE) begin muxreg <= 32'd0; muxreg_valid <= 1'b0; end else if (!wb_freeze) begin muxreg <= muxout; muxreg_valid <= rfwb_op[0]; end end // // Write-back multiplexer // always @(muxin_a or muxin_b or muxin_c or muxin_d or muxin_e or rfwb_op) begin casez(rfwb_op[4:1]) `OR1200_RFWBOP_ALU: muxout = muxin_a; `OR1200_RFWBOP_LSU: begin muxout = muxin_b; end `OR1200_RFWBOP_SPRS: begin muxout = muxin_c; end `OR1200_RFWBOP_LR: begin muxout = muxin_d + 32'h8; end `ifdef OR1200_FPU_IMPLEMENTED `OR1200_RFWBOP_FPU : begin muxout = muxin_e; end `endif default : begin muxout = 0; end endcase end endmodule
3,rf模块
1>整体分析
写回的意思,就是写回到寄存器堆(register file),所以,rf模块是WB阶段的核心模块。
寄存器堆,其物理结构就是RAM。其整体结构如下所示:

or1200的寄存器堆是由两个双端口的RAM组成的。关于这两个RAM(rf_a,rf_b),有以下几点需要注意:
a,每个RAM由32个4字节的寄存器(32x32)组成,分别是r0~r31。这32个寄存器的使用遵循一定的规则,请参考OpenRISC architecture manual的register usage章节,这里不再赘述。
b,双端的RAM,有两个端口,portA和portB,其中portA用来读,portB用来写。
c,这两个双端口的RAM是同步的,也就是说读写端口的时钟信号是相同的。
d,这两个双端口RAM的连接也很有意思,rf_a和rf_b的写端口是连在一起的。也就是说,rf_a和rf_b两个寄存器堆的值是完全相同的。rf_a和rf_b的读端口是分开的。
关于为什么采用两个寄存器堆,这两个寄存器堆为什么要这样连接?原因如下:
在解释原因之前,我们先看一条汇编指令:add r2,r2,r1。其含义是将r1和r2的值相加,再将计算结果写回r2。下面我们看一下分别采用1个寄存器堆和两个寄存器堆的处理过程。
采用一个寄存器堆:共需要4步(不包括指令译码)。
a,读取r2的值
b,读取r1的值
c,运算
d,将结果写回r2
采用两个寄存器堆:只需3步(不包含指令译码)。
a,同时读取r2的值,r1的值
b,运算
c,将结果写回r2(同时写入rf_a和rf_b)
可见,如果采用两套寄存器堆,并且想办法使两套寄存器堆的值完全一样的话,就会减少操作时间。
其实CPU采用多套寄存器堆,是很常见的一种做法。采用不止一套寄存器堆,除了可以提高指令执行速度之外,还有另外一种好处,就是MIPS结构中的影子寄存器(shadow register),专门用来进行异常处理中的现场保护,减少异常上下文的切换时间。
关于指令中的两个源寄存器的地址解码是在ID阶段完成的,这个,我们前面在分析ID模块时已说过,如有疑问,请参考相关内容。下面是解码的核心代码(or1200_ctrl.v)。
assign rf_addra = if_insn[20:16]; assign rf_addrb = if_insn[15:11]; assign rf_rda = if_insn[31] || if_maci_op; assign rf_rdb = if_insn[30];
2>代码分析
了解了rf的整体结构之后,再来分析代码就简单多了。
rf模块对应的rtl文件是or1200_rf.v。
1》寄存器堆的例化
下面是例化两个寄存器堆的部分代码。
//
// Instantiation of register file two-port RAM A
//
or1200_dpram #
(
.aw(5),
.dw(32)
)
rf_a
(
// Port A
.clk_a(clk),
.ce_a(rf_ena),
.addr_a(rf_addra),
.do_a(from_rfa),
// Port B
.clk_b(clk),
.ce_b(rf_we),
.we_b(rf_we),
.addr_b(rf_addrw),
.di_b(rf_dataw)
);
//
// Instantiation of register file two-port RAM B
//
or1200_dpram #
(
.aw(5),
.dw(32)
)
rf_b
(
// Port A
.clk_a(clk),
.ce_a(rf_enb),
.addr_a(addrb),
.do_a(from_rfb),
// Port B
.clk_b(clk),
.ce_b(rf_we),
.we_b(rf_we),
.addr_b(rf_addrw),
.di_b(rf_dataw)
);
可见是例化了两个完全一样的双端口ram,关于双端口ram本身的逻辑,我想大家就都很熟悉了,这里不做过多解释,or1200_dpram_32x32.v文件的核心代码如下。
//
// Generic RAM's registers and wires
//
reg [dw-1:0] mem [(1<<aw)-1:0]; // RAM content
reg [aw-1:0] addr_a_reg; // RAM address registered
//
// Data output drivers
//
assign do_a = (oe_a) ? mem[addr_a_reg] : {dw{1'b0}};
//
// RAM read
//
always @(posedge clk_a or `OR1200_RST_EVENT rst_a)
if (rst_a == `OR1200_RST_VALUE)
addr_a_reg <= {aw{1'b0}};
else if (ce_a)
addr_a_reg <= addr_a;
//
// RAM write
//
always @(posedge clk_b)
if (ce_b && we_b)
mem[addr_b] <= di_b;
2》特殊处理
rf模块的读来源有两个,一个是sprs,一个是debug。
rf模块的写来源也有两个,一个是sprs,一个是其它流水阶段的正常结果。
由于两个寄存器堆的内容完全一样,所以debug模块只需要读一个就可以了,对于or1200的具体实现,debug读的是rf_a。
由于rf_a有两个读来源,那么如果不进行特殊处理,当sprs和debug同时发来读请求的话,那么就可能会出现竞争,造成错误的输出结果。为了避免这种情况出现,or1200增加了一个仲裁机制。首先本地设置一个寄存器来保存上次读操作的地址,此外还增加了一根竞争信号线。这样一旦产生竞争,根据优先级设置的仲裁策略,选择是由sprs读还是debug来读。代码如下所示:
其中有两个关键信号:spr_valid和spr_cs_fe。
spr_valid信号是对两个写来源的仲裁结果。
spr_cs_fe是对两个读来源的仲裁结果。
只要弄明白了这两个信号,这个模块就很好理解了。
// Logic to restore output on RFA after debug unit has read out via SPR if.
// Problem was that the incorrect output would be on RFA after debug unit
// had read out - this is bad if that output is relied upon by execute
// stage for next instruction. We simply save the last address for rf A and
// and re-read it whenever the SPR select goes low, so we must remember
// the last address and generate a signal for falling edge of SPR cs.
// -- Julius
// Detect falling edge of SPR select
reg spr_du_cs;
wire spr_cs_fe;
// Track RF A's address each time it's enabled
reg [aw-1:0] addra_last;
always @(posedge clk)
if (rf_ena & !(spr_cs_fe | (du_read & spr_cs)))
addra_last <= addra;
always @(posedge clk)
spr_du_cs <= spr_cs & du_read;
assign spr_cs_fe = spr_du_cs & !(spr_cs & du_read);
//
// SPR access is valid when spr_cs is asserted and
// SPR address matches GPR addresses
//
assign spr_valid = spr_cs & (spr_addr[10:5] == `OR1200_SPR_RF);
//
// SPR data output is always from RF A
//
assign spr_dat_o = from_rfa;
//
// Operand A comes from RF or from saved A register
//
assign dataa = from_rfa;
//
// Operand B comes from RF or from saved B register
//
assign datab = from_rfb;
//
// RF A read address is either from SPRS or normal from CPU control
//
assign rf_addra = (spr_valid & !spr_write) ? spr_addr[4:0] :
spr_cs_fe ? addra_last : addra;
//
// RF write address is either from SPRS or normal from CPU control
//
assign rf_addrw = (spr_valid & spr_write) ? spr_addr[4:0] : addrw;
//
// RF write data is either from SPRS or normal from CPU datapath
//
assign rf_dataw = (spr_valid & spr_write) ? spr_dat_i : dataw;
//
// RF write enable is either from SPRS or normal from CPU control
//
always @(`OR1200_RST_EVENT rst or posedge clk)
if (rst == `OR1200_RST_VALUE)
rf_we_allow <= 1'b1;
else if (~wb_freeze)
rf_we_allow <= ~flushpipe;
assign rf_we = ((spr_valid & spr_write) | (we & ~wb_freeze)) & rf_we_allow;
assign cy_we_o = cy_we_i && ~wb_freeze && rf_we_allow;
//
// CS RF A asserted when instruction reads operand A and ID stage
// is not stalled
//
assign rf_ena = (rda & ~id_freeze) | (spr_valid & !spr_write) | spr_cs_fe;
//
// CS RF B asserted when instruction reads operand B and ID stage
// is not stalled
//
assign rf_enb = rdb & ~id_freeze;
4,小结
自此,我们已经分析了or1200的流水线的整个条数据通路。