Mining Massive Datasets课程笔记(四)推荐系统
Recommender System 推荐系统
由于网络电商的兴起,商品由实体中有限的个数到互联网时代无数商品可以购买,使得长尾理论被广泛关注。这些都是推荐系统兴起的条件。推荐有多种类型,我们关注的是对个体用户的定制推荐。
Formal Model

Utility Matrix

上图是一个Utility Matrix的例子,A-D表示用户,矩阵中是用户对不同电影的评分。推荐系统的目标就是推测出空白处的评分。当然在现实场景中这个矩阵肯定是极其稀疏的,我们没必要推测所有空白栏的值,而是计算一部分评分较高的电影,作为根据用户喜好做出的推荐。
Key Problem
- 如何获取Utility Matrix中的R,即上例中的评分。
- 如何根据已有的用户评分推断用户对未评分item的喜好度。(主要关注高分部分)
- 如何评价推荐系统的推荐方法
下面来解决上述问题:
Gathering Ratings获取评分
explicit
ask people to rate items
doesn’t scale: only a small fraction of users leave ratings and reviewsimplicit
Learn ratings from user actions- E.g., purchase implies high rating
What about low ratings?
Extrapolateing Utilities推断未知项
主要的问题是utilities Matrix是非常稀疏的,而且许多用户没有对物品进行评分。
推荐系统的推荐方法主要有三种:基于内容的,协同过滤以及基于隐含元素的。具体的方法实现在后面详细讲解。Evaluation将在后面的讲解。
Content-Based Recommendations
Main idea: 将与用户X打高分的物品相似的物品推荐给用户X。例如,有相同演员或导演的电影用户可能都喜欢,相似内容的文章或新闻用户可能都感兴趣以及将有共同好友的人推荐为好友等。

Item Profiles
item profile 就是特定物品的特征,如电影的演员,导演,类型等特征就是电影的profile。
For each item,create an item profile.将item profile看作是一个向量。
因此,profile可以看成是item(document)的重要的特征或词。这个重要特征的选取往往使用的是TF-IDF。(TF-IDF的解释就不说了,可自行百度之)
User Profiles
根据已有的item profiles得到user profiles

More Sophisticated aggregations possible
对于Boolean utilities Matrix,user profile的计算直接求平均即可。
但是对于任意数字评分,如1-5,由于不同用户的评分标准不同,则需要对数据进行一个归一化处理,图例:

有了这user profile x和item profile i后,要预测用户对于i的喜好,可以通过计算余弦相似度求得,即U(x, i)= con( θ)=(x⋅i)/(|x||i|)
Pros: content-based approach
- 不需要其他用户的数据
- 可以为每个用户量身推荐
- 可以推荐新的或者不火爆的物品(no first-rater problem)
- 推荐时有推荐理由(content features that caused an item to be recommended)
Cons: content-based approach
- 寻找和合适的feature有时候是很困难的,如图像,音乐等等的特征如何界定
- 过度特化 overspecialization

- 新用户的Cold-start 问题
Collaborative Filtering 协同过滤
协同过滤的核心思想就是喜欢相同东西的用户可能有类似的喜好。因此将类似用户评分较高的东西作为推荐。

Measuring Similarity
因此我们首先需要找到相似的用户群,我们可以使用Jaccard相似度或者余弦相似度。
Jaccard Similarity
problem:它只考虑了同时给分的情况而忽略了用户的评分大小。

Cosine Similarity
problem:将未评分的项视作了negative

Centered Cosine皮尔逊相似度
我们看到cosine相似度虽然分类正确,但是sim(A, B)和sim(A,C)之间的差距很小,而且未评分的项都当做negative处理了,下面介绍在此基础上的改进——Centered Cosine。
将评分都减去每行评分的平均值,从而正值表示高于平均分,负值表示低于平均分。
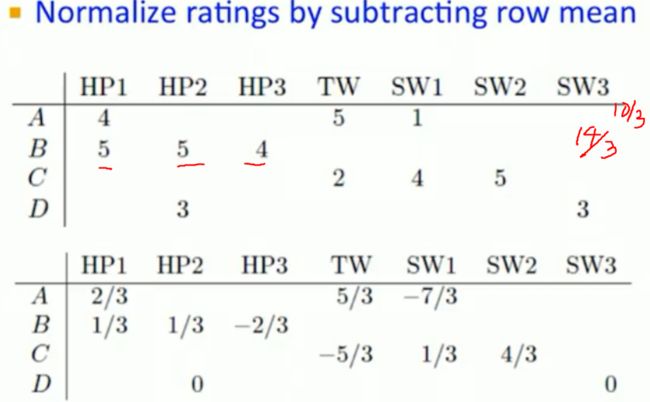
通过这个归一化处理使得空白项不再为negative而是均值,同时也解决了不同用户评分标准不同的问题。结果如下:

Rating Prediction

Option1: rxi=1/k∑y∈Nryi 最简单的方法就是计算N中用户对item i的平均评价,这里没有考虑N中不同用户和user x之间的相似度大小差异。因此我们容易相当加入相似度权值的方法:
Option2: rxi=∑y∈NSxyryi/∑y∈NSxy 其中 Sxy=sim(x,y)
Item-Item Collaborative Filtering
前面我们讨论的都是用户和用户之间的协同过滤,同样的,我们也可以使用Item-Item 的协同过滤。

Item-Item V.s. User-User
理论上两者应该推荐效果应该差不多,但是实际上并不同。实际中,item-Item的效果比user-user要好,因为Item要比用户简单得多。
- items belong to a small set of “genres”, users have varied tastes
- item similarity is more meaningful than user similarity
Implementing Collaborative Filtering 协同过滤的实现
复杂度
最耗时间的是寻找k个相似用户(Item)的过程。需要O(|U|),其中|U| = size of utility matrix 普通的预处理过程也很耗时。该怎么改进呢?
其实我们前面已经学过如何在高维数据中寻找near-neighbor ——LSH算法。
或者是聚类算法
以及马上要将的降维方法。
Pros/Cons of Collaborative Filtering

Hybrid Methods

Global Baseline Estimate
例如要预测Joe对电影The sixth sense的评分,而Joe并没有对任何与The six sense 类似的电影打过分,如果仍然使用Item-Item 协同过滤显然是不行的。
Global Baseline approach:

Combining Global Baseline with Collaborative Filtering

因此最终的评分是Global Baseline estimate和CF的线性和
总结:

Evaluating Recommender Systems
如何评价一个推荐系统的好坏呢。通常在utilities Matrix中选择一部分数据作为test data set测试集。然后用推荐系统的方法预测这部分的评分,一种较为简单的方法是将预测值和已知结果相比较,计算均方根误差从而判断系统的预测性能。

Problems with Error Measures
有时候过分关注预测误差值的大小往往会造成很多问题,如预测的多样性,以及所处的场景和预测结果的顺序等等问题。
而且在实际应用中我们只关心或者说只预测有较高评分的Item。RMSE might penalize a method that does well for high ratings and badly for others.
另一个方法是Precision at top k : 选择percentage of predictions in the user’s top k withheld ratings.
Ref:
…
https://class.coursera.org/mmds-003/lecture
http://blog.csdn.net/sherrylml