学习笔记--bag of words(1)-kMeansCluster
2011.3.11
opencv2.2中有很多新方法的例子,里面的bagOfWords 例子给出了使用pascal voc库的详细例子。
2011.3.14
今天在看bag of words的例子,发现执行错误,featuredetector::create返回空
而且无法step in 这个函数,后来发现,返回空是因为自带的bag of words 程序生成的param。xml文件中的参数大小写有问题。
改正大小写后debug模式没问题。release模式则好像打不开param。xml文件。明天继续了。10点半咯。
(这个param。xml文件是在第一次运行时生成的,其实是我第一次输入参数大小写不正确造成的)
这个问题主要是因为不能step in造成的。15号重新编译了opencv,取代自带的dll文件,就可以step in,原因是自带的缺少了pdb文件。
2011.3.16
程序在运行中,是单线程的,已经24小时了。还没运行完。
(bag of words的论文,我看的是Visual Categorization with Bags of Keypoints)
bag of words方法大致分成如下的步骤:
1.角点,兴趣点检测
2.形成特征描述子 ,前面2个步骤,我觉得wiki里的内容就够看了。如果有sift的基础,前面2个步骤应该没问题。
3.聚簇分析,向量量子化,这里我看的是Visual Categorization with Bags of Keypoints中引用的pattern classification一书第10章603页开始。这一步应该是这个方法的精髓,大量的特征向量被自动归类,再以此构建图像的特征向量。用于训练后面的分类器训练。记得sift方法中是用最近邻匹配完成识别的。用神经网络,svm等分类器来训练和识别似乎更一般化。
4.训练分类器。
2011.3.20 opencv中的k-means cluster
pattern classification 中的例子如下
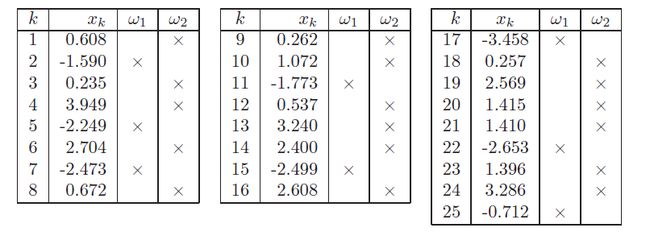
用opencv中的k-means 计算的结果如下:中心点的期望和书中略有差入
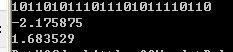
代码如下:,像我一样的初学者可以看看
//init数据
float fdata[25]={0.608,-1.590,0.235,3.949,-2.249,2.704,-2.473,0.672,0.262,1.072,-1.773,0.537,3.240,2.400,-2.499,2.608,-3.458,0.257,2.569,1.415,1.410,-2.653,1.396,3.286,-0.712};
cv::Mat data=cv::Mat(25,1,CV_32FC1,fdata);
int fbestLabels[25];
cv::Mat bestLabels=cv::Mat(25,1,CV_8UC1,fbestLabels);
int k=2;
cv::Mat centers;
cv::kmeans(data,k,bestLabels,cv::TermCriteria(CV_TERMCRIT_ITER+CV_TERMCRIT_EPS,10,0.01),3,cv::KMEANS_PP_CENTERS,¢ers);
for(int i=0;i<25;i++)
{
printf("%d",bestLabels.at<int>(i,0));
}
for(int i=0;i<k;i++)
{
printf("/n/r%f",centers.at<float>(i,0));
}
return 0;
cv::TermCriteria 可以指定循环次数和最小方差(eps不确定是方差),也可以两个都指定centers是k*1维的,包含了中心的的期望。
2011.3.22 pca
opencv中的例子用sift 描述子做cluster后,提交给BOWImgDescriptorExtractor::compute 方法计算图像的特征向量。
大致过程是
{
计算image的sift特征向量,匹配这些sift特征向量到某个cluster,
构建image中各类cluster的分布(广义hough变换?KL变换?)
以分布作为image的特征向量
归一化image特征向量,(除以图像中检测到的特征数)
}
这里的匹配sift特征向量到某个类
匹配的方法还是以knn为主,计算距离可以用欧式距离或hamming距离,另外lowe在中提到best-bin-first 方法,可以节约计算时间。
图像转换成表达图像的特征向量后,就提交分类器学习了。用svm或者其他方法。