《数据结构与算法分析》随机化算法--跳跃表详解
前言:
随机化算法这一章,先介绍了如何产生随机数,不过这个产生的代码已经完全给出来了,我也没有什么编码的必要了,还有一个是素性测试,利用了费马定理,可惜我看了好多遍都没有完全看懂代码和定理的联系,暂且也不再这里介绍了,今天只说说跳跃表的实现。
我的github:
我实现的代码全部贴在我的github中,欢迎大家去参观。
https://github.com/YinWenAtBIT
介绍:
一、跳跃表:
一、定义:
Skip List是一种随机化的数据结构,基于并联的链表,其效率可比拟于二叉查找树(对于大多数操作需要O(log n)平均时间)。基本上,跳跃列表是对有序的链表增加上附加的前进链接,增加是以随机化的方式进行的,所以在列表中的查找可以快速的跳过部分列表(因此得名)。所有操作都以对数随机化的时间进行。Skip List可以很好解决有序链表查找特定值的困难。
二、跳跃表的存储方式:
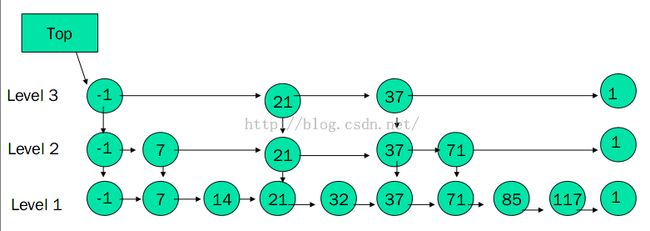
如上,跳跃表每个节点级别为k,代表其有k个指针,每个级别的指针指向相同级别的下一个节点。因此,链表头部需要有一个拥有最大级别的节点。
其他部分实现与普通链表相同,就不在详细叙述。
三、编码实现:
首先是如何选择级别,由于每升高一级,出现概率下降一半,我们需要通过随机的方式模拟这样的选择:
//随机产生层数
int randomLevel()
{
int k=1;
while (rand()%2)
k++;
k=(k<MAX_LEVEL)?k:MAX_LEVEL;
return k;
} 第二个难题,就是如何定义节点,如果定义节点中有最多数量的指针,但是放着不用,岂不是浪费内存吗,如果只有一个,那出现高级别的节点怎么办?这个问题我最初没有一点头绪,直到看了别人的代码,用一个结构体指针,指向一个大于结构体所需的内存空间来实现。后来才想起来,《UNIX网络编程》中同样利用过这个特性。
//节点
typedef struct nodeStructure
{
int key;
int value;
struct nodeStructure *forward[1];
}nodeStructure;
//创建节点
nodeStructure* createNode(int level,int key,int value)
{
nodeStructure *ns=(nodeStructure *)malloc(sizeof(nodeStructure)+level*sizeof(nodeStructure*));
ns->key=key;
ns->value=value;
return ns;
} 节点中只定义了一个指针,并且是使用数组的方式定义的,这样,当出现k级别的时候,使用下标forward[k]来访问指针的时候,会自动在forword[1]上加上偏移量,由于这一块空间我们已经开辟了,所以并不会导致指向了未定义的地址。
再就是添加和删除代码,只需要进行逐级的删除与插入即可。
插入:
bool insert(skiplist *sl,int key,int value)
{
nodeStructure **update = (nodeStructure **)calloc(MAX_LEVEL,sizeof(nodeStructure*));
search(sl, key, update);
//不能插入相同的key
if(update[0] && update[0]->forward[0] &&update[0]->forward[0]->key == key)
{
free(update);
return false;
}
//产生一个随机层数K
//新建一个待插入节点q
//一层一层插入
int k=randomLevel();
//更新跳表的level
if(k>(sl->level))
{
for(int i=sl->level; i < k; i++){
update[i] = sl->header;
}
sl->level=k;
}
nodeStructure * q=createNode(k,key,value);
//逐层更新节点的指针,和普通列表插入一样
for(int i=0;i<k;i++)
{
q->forward[i]=update[i]->forward[i];
update[i]->forward[i]=q;
}
free(update);
return true;
} 删除:
//删除指定的key
bool deleteSL(skiplist *sl,int key)
{
nodeStructure **update = (nodeStructure **)calloc(MAX_LEVEL,sizeof(nodeStructure*));
//寻找节点
search(sl, key, update);
nodeStructure *target;
if(update[0])
target = update[0]->forward[0];
else
{
free(update);
return false;
}
if(target && target->key == key)
{
//逐层删除,和普通列表删除一样
for(int i=0; i<sl->level; i++){
if(update[i]->forward[i]==target){
update[i]->forward[i]=target->forward[i];
}
}
free(target);
//如果删除的是最大层的节点,那么需要重新维护跳表的
for(int i=sl->level - 1; i >= 0; i--){
if(sl->header->forward[i]==NULL){
sl->level--;
}
}
free(update);
return true;
}
else
{
free(update);
return false;
}
} 测试结果:
总结:
跳跃表实现的难题,主要还是如何开辟节点空间的问题,这个我是通过查看别人的博客学习到的,学习到了之后,发现自己还是不够活学活用,这点毕竟已经在UNP这本书上看到过了,只能说学习的不够深入,对于计算机原理也是一知半解。另外,整个代码时在别人的代码基础上修改的,我一味地最求设计模式,结果导致有一部分反而变得复杂了,最后调试反而花了很大的功夫。以后看来什么时候粘代码,什么时候提取出函数,还得好好的考虑。