K-D tree 数据结构
首先来一个问题:
给定平面上一个点集 E ,还有一个定点 V ,怎么在一群点中找出一个点 U,使得 V 与 U 的距离最近(欧几里得距离)?
当然,我们能够想到一种做法:枚举 E 中所有的点,找出它们中距离V 最近的点 U。
但是,假设现在有两个点集 E1 与 E2 ,对于 E2 中每一个点 Vi ,找出一个在E1 中的一个点 Ui,使得 Vi 到 Ui 的距离最短,这怎么做?还是枚举?
既然枚举的复杂度很高 ( O(n) 的复杂度 ),那有没有办法把复杂度降下来呢?答案是肯定的,引入一种数据结构:K-D tree
一、何为 K-D tree?
二叉树(有左儿子,右儿子的那种树形结构)
二、能解决哪些问题?
K-D tree 可以在 log(n) ( 最坏是 sqrt(n) )的时间复杂度内求出一个点集 E 中,距离一个定点 V 最近的点(最近邻查询),稍稍处理一下,我们还可以求出点集 E 中距离距离 V 最近的 k 个点(k邻近查询)
三、怎么利用 K-D tree 解决上面的问题?
将点集 E中的点按照某种规则建成一棵二叉树,查询的时候就在这颗建好的二叉树上面用 log(n) (最坏是 sqrt(n))的时间复杂度查询出距离最近的点
四、既然是二叉树,怎么建树?
这是最关键的地方,因为不管是 划分树 , 线段树 , 字典树 ,甚至是其他的数据结构或者算法(例如 KMP 之类的) ,之所以能够高效的处理问题,主要就是预处理的好。 K-D tree 之所以高效,就是因为建树很高明,高明之处体现在 “将点集 E中的点按照某种规则建成一棵二叉树” 的这种规则上
在讲这种规则之前,我们先来看看 K-D tree 这种数据结构为什么叫做 K-D tree
K:K邻近查询中的k
D:空间是D维空间(Demension)
tree:你可以理解为是二叉树,也可以单纯的看做是一颗 tree
好了, K 我们已经用到了,tree 我们也已经用到了,但是 D 呢?貌似这篇文章到现在为止还没有提到过 D 吧?
这种规则,就是针对空间的“维”的
既然要建树,那么树上的节点肯定要定义一些状态:
节点的状态:
分裂点(split_point)
分裂方式(split_method)
左儿子(left_son)
右儿子(right_son)
我们建树的规则就是节点的状态中的:分裂方式(split_method)
想必读者已经看见上面的关键字了:分裂点 分裂方式,为什么反复的出现分裂这两个字呢?难道建一颗 K-D tree 还要分裂什么,分裂空间?
对,K-D tree的建立就是分裂空间的过程!
怎么建树呢?
建树依据:
先计算当前区间 [ L , R ] 中(这里的区间是点的序号区间,而不是我们实际上的坐标区间),每个点的坐标的每一维度上的方差,取方差最大的那一维,设为 d,作为我们的分裂方式(split_method ),把区间中的点按照在 d 上的大小,从小到大排序,取中间的点 sorted_mid 作为当前节点记录的分裂点,然后,再以 [ L , sorted_mid-1 ] 为左子树建树 , 以 [sorted_mid+1 , R ] 为右子树建树,这样,当前节点的所有状态我们便确定下来了:
split_point= sorted_mid
split_method= d
left_son = [ L , sorted_mid-1 ]
right_son = [ sorted_mid+1 , R ]
为了便于理解,我先举个例子:
假设现在我们有平面上的点集 E ,其中有 5 个二维平面上的点 : (1,4)(5,8) (4,2) (7,9) (10,11)
它们在平面上的分布如图:

首先,我们对区间 [ 1 , 5 ] 建树:
先计算区间中所有点在第一维(也就是 x 坐标)上的方差:
平均值 : ave_1 =5.4
方差 : varance_1 =9.04
再计算区间中所有点在第二维(也就是 y 坐标)上的方差:
平均值:ave_2 =6.8
方差:varance_2 =10.96
明显看见,varance_2 > varance_1 ,那么我们在本次建树中,分裂方式 :split_method =2 , 再将所有的点按照 第 2 维 的大小从小到大排序,得到了新的点的一个排列:
(4,2) (1,4)(5,8) (7,9) (10,11)
取中间的点作为分裂点 sorted_mid =(5,8)作为根节点,再把区间 [ 1 , 2] 建成左子树 , [ 4 , 5] 建成右子树,此时,直线 : y = 8 将平面分裂成了两半,前面一半给左儿子,后面一半给了右儿子,如图:

建左子树 [1 , 3 ] 的时候可以发现,这时候是 第一维 的方差大 ,分裂方式就是1 ,把区间 [ 1, 2 ] 中的点按照 第一维 的大小,从小到大排序 ,取中间点(1,4) 根节点,再以区间 [ 2, 2] 建立右子树 得到节点 (4,2)

建右子树 [4 , 5 ] 的时候可以发现,这时还是 第一维 的方差大, 于是,我们便得到了这样的一颗二叉树 也就是 K-D tree,它把平面分成了如下的小平面,使得每个小平面中最多有一个点:
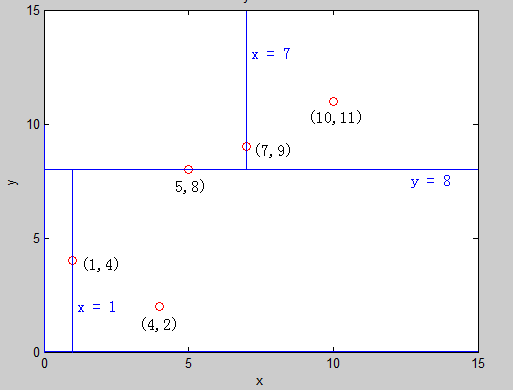
可以看见,我们实际上在建树的过程中,把整个平面分成了 4 个部分
树是建了,那么查询呢?
查询过程:
查询,其实相当于我们要将一个点“添加”到已经建好的 K-D tree 中,但并不是真的添加进去,只是找到他应该处于的子空间即可,所以查询就显得简单的毒攻了
每次在一个区间中查询的时候,先看这个区间的分裂方式是什么,也就是说,先看这个区间是按照哪一维来分裂的,这样如果这个点对应的那一维上面的值比根节点的小,就在根节点的左子树上进行查询操作,如果是大的话,就在右子树上进查询操作
每次回溯到了根节点(也就是说,对他的一个子树的查找已经完成了)的时候,判断一下,以该点为圆心,目前找到的最小距离为半径,看是否和分裂区间的那一维所构成的平面相交,要是相交的话,最近点可能还在另一个子树上,所以还要再查询另一个子树,同时,还要看能否用根节点到该点的距离来更新我们的最近距离。为什么是这样的,我们可以用一幅图来说明:

在查询到左儿子的时候,我们发现,现在最小的距离是 r = 10 ,当回溯到父亲节点的时候,我们发现,以目标点(10,1)为圆心,现在的最小距离 r = 10 为半径做圆,与分割平面 y = 8 相交,这时候,如果我们不在父亲节点的右儿子进行一次查找的话,就会漏掉 (10,9) 这个点,实际上,这个点才是距离目标点 (10,1) 最近的点
由于每次查询的时候可能会把左右两边的子树都查询完,所以,查询并不是简单的 log(n) 的,最坏的时候能够达到 sqrt(n)
好了,到此,K-D tree 就差不多了,写法上与很多值得优化的地方,至于怎么把最邻近查询变换到 K 邻近查询,我们用一个数组记录一个点是否可以用来更新最近距离即可,下面贴上 K-D tree 一个模板
#include <iostream>
#include <cstdio>
#include <cstring>
#include <cmath>
#include <algorithm>
#include <vector>
#include <string>
#include <queue>
#include <stack>
#define INT_INF 0x3fffffff
#define LL_INF 0x3fffffffffffffff
#define EPS 1e-12
#define MOD 1000000007
#define PI 3.141592653579798
#define N 60000
using namespace std;
typedef long long LL;
typedef unsigned long long ULL;
typedef double DB;
struct data
{
LL pos[10];
int id;
} T[N] , op , point;
int split[N],now,n,demension;
bool use[N];
LL ans,id;
DB var[10];
bool cmp(data a,data b)
{
return a.pos[split[now]]<b.pos[split[now]];
}
void build(int L,int R)
{
if(L>R) return;
int mid=(L+R)>>1;
//求出 每一维 上面的方差
for(int pos=0;pos<demension;pos++)
{
DB ave=var[pos]=0.0;
for(int i=L;i<=R;i++)
ave+=T[i].pos[pos];
ave/=(R-L+1);
for(int i=L;i<=R;i++)
var[pos]+=(T[i].pos[pos]-ave)*(T[i].pos[pos]-ave);
var[pos]/=(R-L+1);
}
//找到方差最大的那一维,用它来作为当前区间的 split_method
split[now=mid]=0;
for(int i=1;i<demension;i++)
if(var[split[mid]]<var[i]) split[mid]=i;
//对区间排排序,找到中间点
nth_element(T+L,T+mid,T+R+1,cmp);
build(L,mid-1);
build(mid+1,R);
}
void query(int L,int R)
{
if(L>R) return;
int mid=(L+R)>>1;
//求出目标点 op 到现在的根节点的距离
LL dis=0;
for(int i=0;i<demension;i++)
dis+=(op.pos[i]-T[mid].pos[i])*(op.pos[i]-T[mid].pos[i]);
//如果当前区间的根节点能够用来更新最近距离,并且 dis 小于已经求得的 ans
if(!use[T[mid].id] && dis<ans)
{
ans=dis; //更新最近距离
point=T[mid]; //更新取得最近距离下的点
id=T[mid].id; //更新取得最近距离的点的 id
}
//计算 op 到分裂平面的距离
LL radius=(op.pos[split[mid]]-T[mid].pos[split[mid]])*(op.pos[split[mid]]-T[mid].pos[split[mid]]);
//对子区间进行查询
if(op.pos[split[mid]]<T[mid].pos[split[mid]])
{
query(L,mid-1);
if(radius<=ans) query(mid+1,R);
}
else
{
query(mid+1,R);
if(radius<=ans) query(L,mid-1);
}
}
int main()
{
while(scanf("%d%d",&n,&demension)!=EOF)
{
//读入 n 个点
for(int i=1;i<=n;i++)
{
for(int j=0;j<demension;j++)
scanf("%I64d",&T[i].pos[j]);
T[i].id=i;
}
build(1,n); //建树
int m,q; scanf("%d",&q); // q 个询问
while(q--)
{
memset(use,0,sizeof(use));
for(int i=0;i<demension;i++)
scanf("%I64d",&op.pos[i]);
scanf("%d",&m);
printf("the closest %d points are:\n",m);
while(m--)
{
ans=(((LL)INT_INF)*INT_INF);
query(1,n);
for(int i=0;i<demension;i++)
{
printf("%I64d",point.pos[i]);
if(i==demension-1) printf("\n");
else printf(" ");
}
use[id]=1;
}
}
}
return 0;
}