用数据管理过程(3)——可预测级别的量化管理(麦当劳的管理方式)
摘要:
用数据说话,这是当前很流行的话题,本文将数据管理过程划分成4个层次,并阐述企业如何达到这四个层次。
1.初级量化管理:以数据“感知”项目的状况(相当于CMMI2级)
2.中级量化管理:通过经验值来管理项目(相当于CMMI3级)
3.高级量化管理:用PCB进行项目管理(相当于CMMI4级)
4.超级量化管理:持续优化的量化管理(相当于CMMI5级)
我将通过4篇文章为大家分享!
5.高级量化管理-可预测级
麦当劳的薯条不少人都吃过,味道很好,而且每家麦当劳的薯条味道很一致。麦当劳是如何做到的呢?我们分析一下生产过程,我们发现薯条从原材料开始,到后续加工,油炸的时间,薯条炸出来后多少分钟没有售出,就销毁,整个过程都有严格的控制,而且很多地方是量化控制,时间甚至精确到秒。严格的过程控制,保证了薯条能高质量地稳定地产出。全球的麦当劳,都用同一的严格过程来管理,所以保证了全球的麦当劳的食品都是高质量的而且是高度一致的。从另外一个角度说,只要麦当劳按照既定的过程来生产食物,就可以“预测”出最终食物的情况,麦当劳将对最终产品的质量非常有信心。
那么我们软件开发,是不是也希望能达到这样的效果呢?大家可以回答一下这个问题:如果项目的规模、采用的技术、人员的水平等因素都确定了,那么您是否可以很有信心去预测这个项目的最终结果呢?
如果按照中级量化管理的办法,还是比较难达到这个效果的,“可预测级”的量化管理应该是怎样的呢?
在回答这个问题之前,我们需要先搞清楚什么是“稳定”的过程,什么是“不稳定”的过程。我们以“煮饭”为例,说明什么是稳定的过程什么是不稳定的过程。
大家小的时候可能都野炊过,野炊煮出来的饭可能普遍都是不太好吃的,不是太硬就是太软。为什么煮出来的效果会差异这么大呢?仔细分析一下,我们发现很多因素会影响煮饭的最终质量,如:饭锅、火候、煮的时间、水量等。当我们用野炊的方式煮饭时,这些因素都不太好控制,所以出来饭的质量变化就会比较大了。
我们换一种方式来煮饭,用电饭煲煮饭,失手的几率是不是极大地降低了?为什么会这样呢?当我们用电饭煲的时候,饭锅、火候、时间等因素都被“固定”在理想范围了,所以最终出来的结果是比较稳定而且质量比较好。
再看看我们的软件开发过程,1级的企业做出来的软件,结果是很不稳定的,而4级的企业,能稳定地输出比较好的结果。4级的软件企业,只需要确定了项目的规模、性质、技术、人员技能等因素后,只要按照既定的过程来生产软件,那么就可以很有信心地“预测”这个项目的最终结果,这个“预测”是有很高的可信度的。而CMMI2、3级的企业,虽然也能预测项目的最终结果,但只能“大概”预测,4级企业的预测能准确估计出最终结果的范围,而且这个范围是量化的。
CMMI2、3级的企业,过程还不能说是稳定的,而4级的企业,过程一定是稳定的。同样,初级、中级量化管理,用数据管理的过程,也不能说是稳定的,而高级量化管理,用数据管理的过程,一定是稳定的。
用数据管理过程,要进入“高级”阶段,就必须了解统计过程控制(SPC)的学问,要了解什么是基线(Baseline),所谓的六西格玛管理,其实就是统计过程控制。
例:某公司每周对项目的CPI(成本指数,这是项目挣值管理中的一个重要概念,请参考相关资料)进行度量,分析项目的实际性能。

通过分析,发现CPI波动范围比较宽,从最低的10%到最高的210%,这样意味着最终项目的成本很可能会与预算相差1倍以上。作为管理者来说,这是不可以接受的,管理者希望最终的成本与预算相差在比较小的范围内。
为什么CPI会波动这么大呢?影响CPI波动的因素非常多,有估算、计划、过程、人的能力等等,如果要收窄波动,就需要在这些影响因素上下功夫,想办法减少这些影响因素的影响。经过改进后,项目的CPI情况如下:
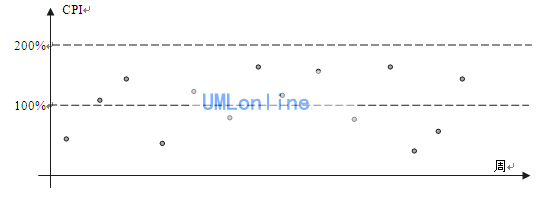
以上的做法是不是已经达到统计过程控制的层次呢?还不是,我们看看下图。

这个控制图,把整个项目过程分为四个阶段:需求阶段、设计阶段、编码阶段、测试阶段。每个阶段执行的过程不一样,工作的性质不一样,故绘制控制图的时候需要予以区分。对不同阶段的CPI数据点绘制XmR图,得出不同阶段的中值与上下限。用不同阶段的CPI的中值及上下限来监控项目的行为,项目管理的重点就是监控各数据点有没有超出上下限,对超出上下限的数据点,分析其原因并采取措施,使之回归到范围内。
所谓的统计过程控制是这样的一个过程:
1) 进行统计过程控制的过程是稳定的,影响该过程的各类因素,都被很好地控制在一定的范围内,故最终的结果也是在可控的范围内的并且是可预测的。
l 什么叫稳定?简单地说,就是在给定的条件下,产出的结果是在一定可接受的范围内的。如:只要项目性质和以前的项目差不多,项目的人员水平和以前的大体一致,执行的过程也和以前一致,那么该项目的结果应该是在可预测的可接受的范围内的。如果从统计学的角度,可以对数据点进行稳定性测试,判断其是否稳定(详细信息请参考SPC方面的书籍)。
2) 要对过程进行足够地细分,才能清晰地区分出各影响因素,使度量出来的数据点很容易识别是信号还是噪音。在进行数据分组的时候,保证数据之间的可比性是非常重要的,苹果只能跟苹果比,不能苹果跟香蕉比。很多做CMMI4级的企业,很容易犯这样的错误,没有很好地进行数据分组,进行数据分组的时候,要充分考虑项目的性质、人员的水平、所执行的过程等因素。数据分组是否合理的重要标准就是,是否能清晰区分出信号还是噪音。
l 什么是信号?信号可以说是“过程之音”,就是过程本身内在的特点所引起的正常波动,如项目的性质、技术、执行的过程、人员的水平等。信号反映了过程的正常的能力。
l 什么是噪音?噪音表明实际工作中出现了一些过程之外的特殊情况,如由没有具备项目管理技能的人来担当项目经理工作,而当前过程要求的是需要具备项目管理能力的人来负责的,这样过程执行效果肯定会与预计的效果发生比较大的偏差,从而超出上下限范围。信号体现了过程正在被正常执行,而噪音则反映出过程正在被偏离执行。
3) 数据点的偏差,是由公共原因(Common Cause)和可归属原因(Special Cause)共同作用下导致的。在控制限内的数据点的偏差,主要是由公共原因导致的,而超出上下限的偏差,则是由公共原因和可归属原因共同引起的。
l 什么是公共原因?公共原因是指过程本身特有的引起偏差的因素,如果人员的水平波动、项目性质的差异、执行过程的力度差异等,这些引起偏差的因素在本过程内已经被削弱,但不可能完全被消除,这些因素共同作用下,会引起数据点的正常波动。信号是由公共原因引起的。
l 什么是可归属原因?可归属原因是指出现了过程没有考虑或者违背了过程的情况,引入了新的引起波动的因素,如:没有安排好相应培训、没有按过程执行等。出现了可归属原因,将会加大数据点的波动,从而超出上下限范围。噪音是由公共原因和可归属原因共同作用引起的。
4) 通过统计学的办法计算出性能基线,如用XR图、XmR图。
5) 用性能基线进行项目管理,项目管理的重点是监控超出范围内的数据点,分析其原因,想办法排除可归属原因。消除可归属原因后,就可以消除由于可归属原因引起的波动,这样数据点就会重新回到上下限范围内。组织级应该有详细的进行可归属原因分析及问题解决的指导,项目经理根据该指导来排除可归属原因。
SPC的原理比较深奥,要深刻理解是不容易的。SPC在制造业等其它行业已经被广泛应用,其基本原理就是通过改造生产流水线,消除或者限制影响产品规格的因素,使产出的产品规格在一定的范围内并符合要求。
这个原理要用到软件生产,就没有那么简单了,影响软件质量的因素非常多,需要“功力深厚”的人分析各影响因素,并通过改造过程来消除或者削弱这些因素的影响。在这个层面上,用数据管理过程的“档次”已经提高了一大截,这时候数据管理的过程是稳定的过程,该过程的中值和上下限反映出该过程的能力。
这里我们引出一个新的问题,什么是有能力的过程?什么是没有能力的过程?什么是能力高的过程?什么是能力低的过程?
不稳定的过程,谈不上能力之说,稳定的过程才能谈能力。稳定的过程,可以通过不断地提高性能来提高能力,如收窄性能基线的上下限范围,使中值更接近理想的目标值等,这些都体现了能力的提高。
请看下一文……
作者:张传波
创新工场创业课堂讲师
软件研发管理资深顾问
CMMI首席专家
《火球——UML大战需求分析》作者
www.umlonline.org 创始人