java源码分析之TreeMap基础篇
常见的数据结构有数组、链表,还有一种结构也很常见,那就是树。前面介绍的集合类有基于数组的ArrayList,有基于链表的LinkedList,还有链表和数组结合的HashMap,今天介绍基于树的TreeMap。
TreeMap基于红黑树(点击查看树、红黑树相关内容)实现。查看“键”或“键值对”时,它们会被排序(次序由Comparable或Comparator决定)。TreeMap的特点在于,所得到的结果是经过排序的。TreeMap是唯一的带有subMap()方法的Map,它可以返回一个子树。
在介绍TreeMap前先介绍Comparable和Comparator接口。
Comparable接口:
1 public interface Comparable<T> { 2 public int compareTo(T o); 3 }
Comparable接口支持泛型,只有一个方法,该方法返回负数、零、正数分别表示当前对象“小于”、“等于”、“大于”传入对象o。
Comparamtor接口:
1 public interface Comparator<T> { 2 int compare(T o1, T o2); 3 boolean equals(Object obj); 4 }
compare(T o1,T o2)方法比较o1和o2两个对象,o1“大于”o2,返回正数,相等返回零,“小于”返回负数。
equals(Object obj)返回true的唯一情况是obj也是一个比较器(Comparator)并且比较结果和此比较器的结果的大小次序是一致的。即comp1.equals(comp2)意味着sgn(comp1.compare(o1, * o2))==sgn(comp2.compare(o1, o2))。
补充:符号sgn(expression)表示数学上的signum函数,该函数根据expression的值是负数、零或正数,分别返回-1、0或1。
小结一下,实现Comparable结构的类可以和其他对象进行比较,即实现Comparable可以进行比较的类。而实现Comparator接口的类是比较器,用于比较两个对象的大小。
下面正式分析TreeMap的源码。
既然TreeMap底层使用的是树结构,那么必然有表示节点的对象。下面先看TreeMap中表示节点的内部类Entry。
1 static final class Entry<K,V> implements Map.Entry<K,V> { 2 // 键值对的“键” 3 K key; 4 // 键值对的“值” 5 V value; 6 // 左孩子 7 Entry<K,V> left = null; 8 // 右孩子 9 Entry<K,V> right = null; 10 // 父节点 11 Entry<K,V> parent; 12 // 红黑树的节点表示颜色的属性 13 boolean color = BLACK; 14 /** 15 * 根据给定的键、值、父节点构造一个节点,颜色为默认的黑色 16 */ 17 Entry(K key, V value, Entry<K,V> parent) { 18 this.key = key; 19 this.value = value; 20 this.parent = parent; 21 } 22 // 获取节点的key 23 public K getKey() { 24 return key; 25 } 26 // 获取节点的value 27 public V getValue() { 28 return value; 29 } 30 /** 31 * 修改并返回当前节点的value 32 */ 33 public V setValue(V value) { 34 V oldValue = this.value; 35 this.value = value; 36 return oldValue; 37 } 38 // 判断节点相等的方法(两个节点为同一类型且key值和value值都相等时两个节点相等) 39 public boolean equals(Object o) { 40 if (!(o instanceof Map.Entry)) 41 return false; 42 Map.Entry<?,?> e = (Map.Entry<?,?>)o; 43 return valEquals(key,e.getKey()) && valEquals(value,e.getValue()); 44 } 45 // 节点的哈希值计算方法 46 public int hashCode() { 47 int keyHash = (key==null ? 0 : key.hashCode()); 48 int valueHash = (value==null ? 0 : value.hashCode()); 49 return keyHash ^ valueHash; 50 } 51 public String toString() { 52 return key + "=" + value; 53 } 54 }
上面的Entry类比较简单,实现了树节点的必要内容,提供了hashCode方法等。下面看TreeMap类的定义。
1 public class TreeMap<K,V> 2 extends AbstractMap<K,V> 3 implements NavigableMap<K,V>, Cloneable, java.io.Serializable
上面只有一个接口需要说明,那就是NavigableMap接口。
NavigableMap接口扩展的SortedMap,具有了针对给定搜索目标返回最接近匹配项的导航方法。方法lowerEntry、floorEntry、ceilingEntry和higherEntry分别返回与小于、小于等于、大于等于、大于给定键的键关联的Map.Entry对象,如果不存在这样的键,则返回null。类似地,方法lowerKey、floorKey、ceilingKey和higherKey只返回关联的键。所有这些方法是为查找条目而不是遍历条目而设计的(后面会逐个介绍这些方法)。
下面是TreeMap的属性:
1 // 用于保持顺序的比较器,如果为空的话使用自然顺保持Key的顺序 2 private final Comparator<? super K> comparator; 3 // 根节点 4 private transient Entry<K,V> root = null; 5 // 树中的节点数量 6 private transient int size = 0; 7 // 多次在集合类中提到了,用于举了结构行的改变次数 8 private transient int modCount = 0;
注释中已经给出了属性的解释,下面看TreeMap的构造方法。
1 // 构造方法一,默认的构造方法,comparator为空,即采用自然顺序维持TreeMap中节点的顺序 2 public TreeMap() { 3 comparator = null; 4 } 5 // 构造方法二,提供指定的比较器 6 public TreeMap(Comparator<? super K> comparator) { 7 this.comparator = comparator; 8 } 9 // 构造方法三,采用自然序维持TreeMap中节点的顺序,同时将传入的Map中的内容添加到TreeMap中 10 public TreeMap(Map<? extends K, ? extends V> m) { 11 comparator = null; 12 putAll(m); 13 } 14 /** 15 *构造方法四,接收SortedMap参数,根据SortedMap的比较器维持TreeMap中的节点顺序,* 同时通过buildFromSorted(int size, Iterator it, java.io.ObjectInputStream str, V defaultVal)方* 法将SortedMap中的内容添加到TreeMap中 16 */ 17 public TreeMap(SortedMap<K, ? extends V> m) { 18 comparator = m.comparator(); 19 try { 20 buildFromSorted(m.size(), m.entrySet().iterator(), null, null); 21 } catch (java.io.IOException cannotHappen) { 22 } catch (ClassNotFoundException cannotHappen) { 23 } 24 }
TreeMap提供了四个构造方法,已经在注释中给出说明。构造方法中涉及到的方法在下文中会有介绍。
下面从put/get方法开始,逐个分析TreeMap的方法。
put(K key, V value)
1 public V put(K key, V value) { 2 Entry<K,V> t = root; 3 if (t == null) { 4 //如果根节点为null,将传入的键值对构造成根节点(根节点没有父节点,所以传入的父节点为null) 5 root = new Entry<K,V>(key, value, null); 6 size = 1; 7 modCount++; 8 return null; 9 } 10 // 记录比较结果 11 int cmp; 12 Entry<K,V> parent; 13 // 分割比较器和可比较接口的处理 14 Comparator<? super K> cpr = comparator; 15 // 有比较器的处理 16 if (cpr != null) { 17 // do while实现在root为根节点移动寻找传入键值对需要插入的位置 18 do { 19 // 记录将要被掺入新的键值对将要节点(即新节点的父节点) 20 parent = t; 21 // 使用比较器比较父节点和插入键值对的key值的大小 22 cmp = cpr.compare(key, t.key); 23 // 插入的key较大 24 if (cmp < 0) 25 t = t.left; 26 // 插入的key较小 27 else if (cmp > 0) 28 t = t.right; 29 // key值相等,替换并返回t节点的value(put方法结束) 30 else 31 return t.setValue(value); 32 } while (t != null); 33 } 34 // 没有比较器的处理 35 else { 36 // key为null抛出NullPointerException异常 37 if (key == null) 38 throw new NullPointerException(); 39 Comparable<? super K> k = (Comparable<? super K>) key; 40 // 与if中的do while类似,只是比较的方式不同 41 do { 42 parent = t; 43 cmp = k.compareTo(t.key); 44 if (cmp < 0) 45 t = t.left; 46 else if (cmp > 0) 47 t = t.right; 48 else 49 return t.setValue(value); 50 } while (t != null); 51 } 52 // 没有找到key相同的节点才会有下面的操作 53 // 根据传入的键值对和找到的“父节点”创建新节点 54 Entry<K,V> e = new Entry<K,V>(key, value, parent); 55 // 根据最后一次的判断结果确认新节点是“父节点”的左孩子还是又孩子 56 if (cmp < 0) 57 parent.left = e; 58 else 59 parent.right = e; 60 // 对加入新节点的树进行调整 61 fixAfterInsertion(e); 62 // 记录size和modCount 63 size++; 64 modCount++; 65 // 因为是插入新节点,所以返回的是null 66 return null; 67 }
首先一点通性是TreeMap的put方法和其他Map的put方法一样,向Map中加入键值对,若原先“键(key)”已经存在则替换“值(value)”,并返回原先的值。
在put(K key,V value)方法的末尾调用了fixAfterInsertion(Entry<K,V> x)方法,这个方法负责在插入节点后调整树结构和着色,以满足红黑树的要求。
- 每一个节点或者着成红色,或者着成黑色。
- 根是黑色的。
- 如果一个节点是红色的,那么它的子节点必须是黑色的。
- 一个节点到一个null引用的每一条路径必须包含相同数量的黑色节点。
在看fixAfterInsertion(Entry<K,V> x)方法前先看一个红黑树的内容:红黑树不是严格的平衡二叉树,它并不严格的保证左右子树的高度差不超过1,但红黑树高度依然是平均log(n),且最坏情况高度不会超过2log(n),所以它算是平衡树。
下面看具体实现代码。
fixAfterInsertion(Entry<K,V> x)
1 private void fixAfterInsertion(Entry<K,V> x) { 2 // 插入节点默认为红色 3 x.color = RED; 4 // 循环条件是x不为空、不是根节点、父节点的颜色是红色(如果父节点不是红色,则没有连续的红色节点,不再调整) 5 while (x != null && x != root && x.parent.color == RED) { 6 // x节点的父节点p(记作p)是其父节点pp(p的父节点,记作pp)的左孩子(pp的左孩子) 7 if (parentOf(x) == leftOf(parentOf(parentOf(x)))) { 8 // 获取pp节点的右孩子r 9 Entry<K,V> y = rightOf(parentOf(parentOf(x))); 10 // pp右孩子的颜色是红色(colorOf(Entry e)方法在e为空时返回BLACK),不需要进行旋转操作(因为红黑树不是严格的平衡二叉树) 11 if (colorOf(y) == RED) { 12 // 将父节点设置为黑色 13 setColor(parentOf(x), BLACK); 14 // y节点,即r设置成黑色 15 setColor(y, BLACK); 16 // pp节点设置成红色 17 setColor(parentOf(parentOf(x)), RED); 18 // x“移动”到pp节点 19 x = parentOf(parentOf(x)); 20 } else {//父亲的兄弟是黑色的,这时需要进行旋转操作,根据是“内部”还是“外部”的情况决定是双旋转还是单旋转 21 // x节点是父节点的右孩子(因为上面已近确认p是pp的左孩子,所以这是一个“内部,左-右”插入的情况,需要进行双旋转处理) 22 if (x == rightOf(parentOf(x))) { 23 // x移动到它的父节点 24 x = parentOf(x); 25 // 左旋操作 26 rotateLeft(x); 27 } 28 // x的父节点设置成黑色 29 setColor(parentOf(x), BLACK); 30 // x的父节点的父节点设置成红色 31 setColor(parentOf(parentOf(x)), RED); 32 // 右旋操作 33 rotateRight(parentOf(parentOf(x))); 34 } 35 } else { 36 // 获取x的父节点(记作p)的父节点(记作pp)的左孩子 37 Entry<K,V> y = leftOf(parentOf(parentOf(x))); 38 // y节点是红色的 39 if (colorOf(y) == RED) { 40 // x的父节点,即p节点,设置成黑色 41 setColor(parentOf(x), BLACK); 42 // y节点设置成黑色 43 setColor(y, BLACK); 44 // pp节点设置成红色 45 setColor(parentOf(parentOf(x)), RED); 46 // x移动到pp节点 47 x = parentOf(parentOf(x)); 48 } else { 49 // x是父节点的左孩子(因为上面已近确认p是pp的右孩子,所以这是一个“内部,右-左”插入的情况,需要进行双旋转处理), 50 if (x == leftOf(parentOf(x))) { 51 // x移动到父节点 52 x = parentOf(x); 53 // 右旋操作 54 rotateRight(x); 55 } 56 // x的父节点设置成黑色 57 setColor(parentOf(x), BLACK); 58 // x的父节点的父节点设置成红色 59 setColor(parentOf(parentOf(x)), RED); 60 // 左旋操作 61 rotateLeft(parentOf(parentOf(x))); 62 } 63 } 64 } 65 // 根节点为黑色 66 root.color = BLACK; 67 }
fixAfterInsertion(Entry<K,V> x)方法涉及到了左旋和右旋的操作,下面是左旋的代码及示意图(右旋操作类似,就不给出代码和示意图了)。
1 // 左旋操作 2 private void rotateLeft(Entry<K,V> p) { 3 if (p != null) { 4 Entry<K,V> r = p.right; 5 p.right = r.left; 6 if (r.left != null) 7 r.left.parent = p; 8 r.parent = p.parent; 9 if (p.parent == null) 10 root = r; 11 else if (p.parent.left == p) 12 p.parent.left = r; 13 else 14 p.parent.right = r; 15 r.left = p; 16 p.parent = r; 17 } 18 }
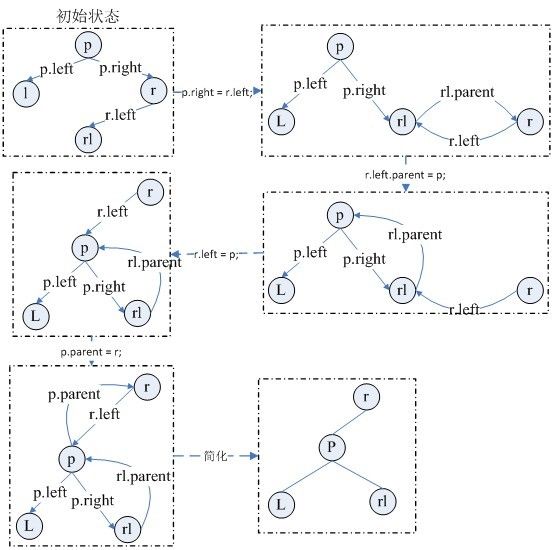
看完put操作,下面来看get操作相关的内容。
get(Object key)
1 public V get(Object key) { 2 Entry<K,V> p = getEntry(key); 3 return (p==null ? null : p.value); 4 }
get(Object key)通过key获取对应的value,它通过调用getEntry(Object key)获取节点,若节点为null则返回null,否则返回节点的value值。下面是getEntry(Object key)的内容,来看它是怎么寻找节点的。
getEntry(Object key)
1 final Entry<K,V> getEntry(Object key) { 2 // 如果有比较器,返回getEntryUsingComparator(Object key)的结果 3 if (comparator != null) 4 return getEntryUsingComparator(key); 5 // 查找的key为null,抛出NullPointerException 6 if (key == null) 7 throw new NullPointerException(); 8 // 如果没有比较器,而是实现了可比较接口 9 Comparable<? super K> k = (Comparable<? super K>) key; 10 // 获取根节点 11 Entry<K,V> p = root; 12 // 对树进行遍历查找节点 13 while (p != null) { 14 // 把key和当前节点的key进行比较 15 int cmp = k.compareTo(p.key); 16 // key小于当前节点的key 17 if (cmp < 0) 18 // p “移动”到左节点上 19 p = p.left; 20 // key大于当前节点的key 21 else if (cmp > 0) 22 // p “移动”到右节点上 23 p = p.right; 24 // key值相等则当前节点就是要找的节点 25 else 26 // 返回找到的节点 27 return p; 28 } 29 // 没找到则返回null 30 return null; 31 }
上面主要是处理实现了可比较接口的情况,而有比较器的情况在getEntryUsingComparator(Object key)中处理了,下面来看处理的代码。
getEntryUsingComparator(Object key)
1 final Entry<K,V> getEntryUsingComparator(Object key) { 2 K k = (K) key; 3 // 获取比较器 4 Comparator<? super K> cpr = comparator; 5 // 其实在调用此方法的get(Object key)中已经对比较器为null的情况进行判断,这里是防御性的判断 6 if (cpr != null) { 7 // 获取根节点 8 Entry<K,V> p = root; 9 // 遍历树 10 while (p != null) { 11 // 获取key和当前节点的key的比较结果 12 int cmp = cpr.compare(k, p.key); 13 // 查找的key值较小 14 if (cmp < 0) 15 // p“移动”到左孩子 16 p = p.left; 17 // 查找的key值较大 18 else if (cmp > 0) 19 // p“移动”到右节点 20 p = p.right; 21 // key值相等 22 else 23 // 返回找到的节点 24 return p; 25 } 26 } 27 // 没找到key值对应的节点,返回null 28 return null; 29 }
看完添加(put)和获取(get),下面来看删除(remove、clear)。
remove(Object key)
1 public V remove(Object key) { 2 // 通过getEntry(Object key)获取节点 getEntry(Object key)方法已经在上面介绍过了 3 Entry<K,V> p = getEntry(key); 4 // 指定key的节点不存在,返回null 5 if (p == null) 6 return null; 7 // 获取节点的value 8 V oldValue = p.value; 9 // 删除节点 10 deleteEntry(p); 11 // 返回节点的内容 12 return oldValue; 13 }
真正实现删除节点的内容在deleteEntry(Entry e)中,涉及到树结构的调整等。remove(Object key)只是获取要删除的节点并返回被删除节点的value。下面来看deleteEntry(Entry e)的内容。
deleteEntry(Entry e)
1 private void deleteEntry(Entry<K,V> p) { 2 // 记录树结构的修改次数 3 modCount++; 4 // 记录树中节点的个数 5 size--; 6 7 // p有左右两个孩子的情况 标记① 8 if (p.left != null && p.right != null) { 9 // 获取继承者节点(有两个孩子的情况下,继承者肯定是右孩子或右孩子的最左子孙) 10 Entry<K,V> s = successor (p); 11 // 使用继承者s替换要被删除的节点p,将继承者的key和value复制到p节点,之后将p指向继承者 12 p.key = s.key; 13 p.value = s.value; 14 p = s; 15 } 16 17 // Start fixup at replacement node, if it exists. 18 // 开始修复被移除节点处的树结构 19 // 如果p有左孩子,取左孩子,否则取右孩子 标记② 20 Entry<K,V> replacement = (p.left != null ? p.left : p.right); 21 if (replacement != null) { 22 // Link replacement to parent 23 replacement.parent = p.parent; 24 // p节点没有父节点,即p节点是根节点 25 if (p.parent == null) 26 // 将根节点替换为replacement节点 27 root = replacement; 28 // p是其父节点的左孩子 29 else if (p == p.parent.left) 30 // 将p的父节点的left引用指向replacement 31 // 这步操作实现了删除p的父节点到p节点的引用 32 p.parent.left = replacement; 33 else 34 // 如果p是其父节点的右孩子,将父节点的right引用指向replacement 35 p.parent.right = replacement; 36 // 解除p节点到其左右孩子和父节点的引用 37 p.left = p.right = p.parent = null; 38 if (p.color == BLACK) 39 // 在删除节点后修复红黑树的颜色分配 40 fixAfterDeletion(replacement); 41 } else if (p.parent == null) { 42 /* 进入这块代码则说明p节点就是根节点(这块比较难理解,如果标记①处p有左右孩子,则找到的继承节点s是p的一个祖先节点或右孩子或右孩子的最左子孙节点,他们要么有孩子节点,要么有父节点,所以如果进入这块代码,则说明标记①除的p节点没有左右两个孩子。没有左右孩子,则有没有孩子、有一个右孩子、有一个左孩子三种情况,三种情况中只有没有孩子的情况会使标记②的if判断不通过,所以p节点只能是没有孩子,加上这里的判断,p没有父节点,所以p是一个独立节点,也是树种的唯一节点……有点难理解,只能解释到这里了,读者只能结合注释慢慢体会了),所以将根节点设置为null即实现了对该节点的删除 */ 43 root = null; 44 } else { /* 标记②的if判断没有通过说明被删除节点没有孩子,或它有两个孩子但它的继承者没有孩子。如果是被删除节点没有孩子,说明p是个叶子节点,则不需要找继承者,直接删除该节点。如果是有两个孩子,那么继承者肯定是右孩子或右孩子的最左子孙 */ 45 if (p.color == BLACK) 46 // 调整树结构 47 fixAfterDeletion(p); 48 // 这个判断也一定会通过,因为p.parent如果不是null则在上面的else if块中已经被处理 49 if (p.parent != null) { 50 // p是一个左孩子 51 if (p == p.parent.left) 52 // 删除父节点对p的引用 53 p.parent.left = null; 54 else if (p == p.parent.right)// p是一个右孩子 55 // 删除父节点对p的引用 56 p.parent.right = null; 57 // 删除p节点对父节点的引用 58 p.parent = null; 59 } 60 } 61 }
deleteEntry(Entry e)方法中主要有两个方法调用需要分析:successor(Entry<K,V> t)和fixAfterDeletion(Entry<K,V> x)。
successor(Entry<K,V> t)返回指定节点的继承者。分三种情况处理,第一。t节点是个空节点:返回null;第二,t有右孩子:找到t的右孩子中的最左子孙节点,如果右孩子没有左孩子则返回右节点,否则返回找到的最左子孙节点;第三,t没有右孩子:沿着向上(向跟节点方向)找到第一个自身是一个左孩子的节点或根节点,返回找到的节点。下面是具体代码分析的注释。
1 static <K,V> TreeMap.Entry<K,V> successor(Entry<K,V> t) { 2 // 如果t本身是一个空节点,返回null 3 if (t == null) 4 return null; 5 // 如果t有右孩子,找到右孩子的最左子孙节点 6 else if (t.right != null) { 7 Entry<K,V> p = t.right; 8 // 获取p节点最左的子孙节点,如果存在的话 9 while (p.left != null) 10 p = p.left; 11 // 返回找到的继承节点 12 return p; 13 } else {//t不为null且没有右孩子 14 Entry<K,V> p = t.parent; 15 Entry<K,V> ch = t; 16 // // 沿着右孩子向上查找继承者,直到根节点或找到节点ch是其父节点的左孩子的节点 17 while (p != null && ch == p.right) { 18 ch = p; 19 p = p.parent; 20 } 21 return p; 22 } 23 }
与添加节点之后的修复类似的是,TreeMap 删除节点之后也需要进行类似的修复操作,通过这种修复来保证该排序二叉树依然满足红黑树特征。大家可以参考插入节点之后的修复来分析删除之后的修复。TreeMap 在删除之后的修复操作由 fixAfterDeletion(Entry<K,V> x) 方法提供,该方法源代码如下:
1 private void fixAfterDeletion(Entry<K,V> x) { 2 // 循环处理,条件为x不是root节点且是黑色的(因为红色不会对红黑树的性质造成破坏,所以不需要调整) 3 while (x != root && colorOf(x) == BLACK) { 4 // x是一个左孩子 5 if (x == leftOf(parentOf(x))) { 6 // 获取x的兄弟节点sib 7 Entry<K,V> sib = rightOf(parentOf(x)); 8 // sib是红色的 9 if (colorOf(sib) == RED) { 10 // 将sib设置为黑色 11 setColor(sib, BLACK); 12 // 将父节点设置成红色 13 setColor(parentOf(x), RED); 14 // 左旋父节点 15 rotateLeft(parentOf(x)); 16 // sib移动到旋转后x的父节点p的右孩子(参见左旋示意图,获取的节点是旋转前p的右孩子r的左孩子rl) 17 sib = rightOf(parentOf(x)); 18 } 19 // sib的两个孩子的颜色都是黑色(null返回黑色) 20 if (colorOf(leftOf(sib)) == BLACK && 21 colorOf(rightOf(sib)) == BLACK) { 22 // 将sib设置成红色 23 setColor(sib, RED); 24 // x移动到x的父节点 25 x = parentOf(x); 26 } else {// sib的左右孩子都是黑色的不成立 27 // sib的右孩子是黑色的 28 if (colorOf(rightOf(sib)) == BLACK) { 29 // 将sib的左孩子设置成黑色 30 setColor(leftOf(sib), BLACK); 31 // sib节点设置成红色 32 setColor(sib, RED); 33 // 右旋操作 34 rotateRight(sib); 35 // sib移动到旋转后x父节点的右孩子 36 sib = rightOf(parentOf(x)); 37 } 38 // sib设置成和x的父节点一样的颜色 39 setColor(sib, colorOf(parentOf(x))); 40 // x的父节点设置成黑色 41 setColor(parentOf(x), BLACK); 42 // sib的右孩子设置成黑色 43 setColor(rightOf(sib), BLACK); 44 // 左旋操作 45 rotateLeft(parentOf(x)); 46 // 设置调整完的条件:x = root跳出循环 47 x = root; 48 } 49 } else { // x是一个右孩子 50 // 获取x的兄弟节点 51 Entry<K,V> sib = leftOf(parentOf(x)); 52 // 如果sib是红色的 53 if (colorOf(sib) == RED) { 54 // 将sib设置为黑色 55 setColor(sib, BLACK); 56 // 将x的父节点设置成红色 57 setColor(parentOf(x), RED); 58 // 右旋 59 rotateRight(parentOf(x)); 60 // sib移动到旋转后x父节点的左孩子 61 sib = leftOf(parentOf(x)); 62 } 63 // sib的两个孩子的颜色都是黑色(null返回黑色) 64 if (colorOf(rightOf(sib)) == BLACK && 65 colorOf(leftOf(sib)) == BLACK) { 66 // sib设置为红色 67 setColor(sib, RED); 68 // x移动到x的父节点 69 x = parentOf(x); 70 } else { // sib的两个孩子的颜色都是黑色(null返回黑色)不成立 71 // sib的左孩子是黑色的,或者没有左孩子 72 if (colorOf(leftOf(sib)) == BLACK) { 73 // 将sib的右孩子设置成黑色 74 setColor(rightOf(sib), BLACK); 75 // sib节点设置成红色 76 setColor(sib, RED); 77 // 左旋 78 rotateLeft(sib); 79 // sib移动到x父节点的左孩子 80 sib = leftOf(parentOf(x)); 81 } 82 // sib设置成和x的父节点一个颜色 83 setColor(sib, colorOf(parentOf(x))); 84 // x的父节点设置成黑色 85 setColor(parentOf(x), BLACK); 86 // sib的左孩子设置成黑色 87 setColor(leftOf(sib), BLACK); 88 // 右旋 89 rotateRight(parentOf(x)); 90 // 设置跳出循环的标识 91 x = root; 92 } 93 } 94 } 95 // 将x设置为黑色 96 setColor(x, BLACK); 97 }
光看调整的代码,一大堆设置颜色,还有左旋和右旋,非常的抽象,下面是一个构造红黑树的视屏,包括了着色和旋转。
http://v.youku.com/v_show/id_XMjI3NjM0MTgw.html
clear()
1 public void clear() { 2 modCount++; 3 size = 0; 4 root = null; 5 }
clear()方法很简单,只是记录结构修改次数,将size修改为0,将root设置为null,这样就没法通过root访问树的其他节点,所以数的内容会被GC回收。
添加(修改)、获取、删除的原码都已经看了,下面看判断是否包含的方法。
containKey(Object key)
1 public boolean containsKey(Object key) { 2 return getEntry(key) != null; 3 }
这个方法判断获取key对应的节点是否为空,getEntry(Object key)方法已经在上面介绍过了。
contain(Object value)
1 public boolean containsValue(Object value) { 2 // 通过e = successor(e)实现对树的遍历 3 for (Entry<K,V> e = getFirstEntry(); e != null; e = successor(e)) 4 // 判断节点值是否和value相等 5 if (valEquals(value, e.value)) 6 return true; 7 // 默认返回false 8 return false; 9 }
contain(Object value)涉及到了getFirstEntry()方法和successor(Entry<K,V> e)。getFirstEntry()是获取第一个节点,successor(Entry<K,V> e)是获取节点e的继承者,在for循环中配合使用getFirstEntry()方法和successor(Entry<K,V> e)及e!=null是遍历树的一种方法。
下面介绍getFirstEntry()方法。
getFirstEntry()
1 final Entry<K,V> getFirstEntry() { 2 Entry<K,V> p = root; 3 if (p != null) 4 while (p.left != null) 5 p = p.left; 6 return p; 7 }
从名字上看是获取第一个节点,实际是获取的整棵树中“最左”的节点(第一个节点具体指哪一个节点和树的遍历次序有关,如果是先根遍历,则第一个节点是根节点)。又因为红黑树是排序的树,所以“最左”的节点也是值最小的节点。
上面是getFirstEntry()方法,下面介绍getLastEntry()方法。
getLastEntry()
1 final Entry<K,V> getLastEntry() { 2 Entry<K,V> p = root; 3 if (p != null) 4 while (p.right != null) 5 p = p.right; 6 return p; 7 }
getLastEntry()和getFirstEntry()对应,获取的是“最右”的节点。
TreeMap中提供了获取并移除最小和最大节点的两个方法:pollFirstEntry()和pollLastEntry()。
pollFirstEntry()
1 public Map.Entry<K,V> pollFirstEntry() { 2 Entry<K,V> p = getFirstEntry(); 3 Map.Entry<K,V> result = exportEntry(p); 4 if (p != null) 5 deleteEntry(p); 6 return result; 7 }
pollLastEntry()
1 public Map.Entry<K,V> pollLastEntry() { 2 Entry<K,V> p = getLastEntry(); 3 Map.Entry<K,V> result = exportEntry(p); 4 if (p != null) 5 deleteEntry(p); 6 return result; 7 }
pollFirstEntry()和pollLastEntry()分别通过getFirstEntry()和getLastEntry()获取节点,exportEntry(TreeMap.Entry<K,V> e)应该是保留这个对象用于在删除这个节点后返回。具体实现看下面的代码。
1 static <K,V> Map.Entry<K,V> exportEntry(TreeMap.Entry<K,V> e) { 2 return e == null? null : 3 new AbstractMap.SimpleImmutableEntry<K,V>(e); 4 }
返回了一个SimpleImmutableEntry对象,调用的构造方法如下:
1 public SimpleImmutableEntry(Entry<? extends K, ? extends V> entry) { 2 this.key = entry.getKey(); 3 this.value = entry.getValue(); 4 }
可以看到返回的节点内容只包含key和value。
下面看其他具体的获取键、值、键值对的方法。
1 public Map.Entry<K,V> ceilingEntry(K key) { 2 return exportEntry(getCeilingEntry(key)); 3 } 4 public K ceilingKey(K key) { 5 return keyOrNull(getCeilingEntry(key)); 6 }
上面这两个方法很简单,只是对exportEntry和keyOrNull的调用。keyOrNull根据传入的Entry是否为null,选择方法null或Entry的key。
1 // 获取最小的节点的key 2 public K firstKey() { 3 return key(getFirstEntry()); 4 } 5 // 获取最大节点的key 6 public K lastKey() { 7 return key(getLastEntry()); 8 } 9 // 获取最小的键值对 10 public Map.Entry<K,V> firstEntry() { 11 return exportEntry(getFirstEntry()); 12 } 13 // 获取最大的键值对 14 public Map.Entry<K,V> lastEntry() { 15 return exportEntry(getLastEntry()); 16 }
这几个方法涉及到的内容都在上面介绍过了,就不在说明了。
1 public Map.Entry<K,V> floorEntry(K key) { 2 return exportEntry(getFloorEntry(key)); 3 } 4 public K floorKey(K key) { 5 return keyOrNull(getFloorEntry(key)); 6 } 7 public Map.Entry<K,V> higherEntry(K key) { 8 return exportEntry(getHigherEntry(key)); 9 } 10 public K higherKey(K key) { 11 return keyOrNull(getHigherEntry(key)); 12 }
这几个获取key的Entry的方法都是对getFloorEntry和getHigherEntry的处理。下面介绍这两个方法。
getFloorEntry(K key)
1 final Entry<K,V> getFloorEntry(K key) { 2 // 获取根节点 3 Entry<K,V> p = root; 4 // 不是空树,最树进行遍历 5 while (p != null) { 6 int cmp = compare(key, p.key); 7 // key较大 8 if (cmp > 0) { 9 // 找到节点有右孩子,则继续向右孩子遍历 10 if (p.right != null) 11 p = p.right; 12 else// 没有右孩子,那么p节点就是树中比key值比传入key值小且最接近传入key的节点,就是要找的节点 13 return p; 14 } else if (cmp < 0) {// key值较小 15 // 有左孩子向左孩子遍历 16 if (p.left != null) { 17 p = p.left; 18 } else {// 没有左孩子,这个节点比key值大,返回内容是向上寻找到的根节点或比传入key值小的最后一个节点(这块比较难理解,仔细模拟寻找节点的过程就会明白) 19 Entry<K,V> parent = p.parent; 20 Entry<K,V> ch = p; 21 while (parent != null && ch == parent.left) { 22 ch = parent; 23 parent = parent.parent; 24 } 25 return parent; 26 } 27 } else // key值相等 28 return p; 29 } 30 return null; 31 }
getHigherEntry(K key)
1 final Entry<K,V> getHigherEntry(K key) { 2 Entry<K,V> p = root; 3 while (p != null) { 4 int cmp = compare(key, p.key); 5 if (cmp < 0) { 6 if (p.left != null) 7 p = p.left; 8 else 9 return p; 10 } else { 11 if (p.right != null) { 12 p = p.right; 13 } else { 14 Entry<K,V> parent = p.parent; 15 Entry<K,V> ch = p; 16 while (parent != null && ch == parent.right) { 17 ch = parent; 18 parent = parent.parent; 19 } 20 return parent; 21 } 22 } 23 } 24 return null; 25 }
getFloorEntry和getHigherEntry方法遍历和寻找节点的方法类似,区别在于getFloorEntry寻找的是小于等于,优先返回小于的节点,而getHigherEntry寻找的是严格大于的节点,不包括等于的情况。