以NATS为主线的CloudFoundry原理
本文将试图以CloudFoundry中的消息组件NATS为主要线索,以在CF中广泛使用的并发和网络编程框架EventMachine为侧重,来串联整个CF主线功能的工作原理,力求能用简单直接的方式描述出较多的架构细节和系统设计。
需要准备的知识:
EventMachine(EM)的基础知识和使用方法,可以参考不久前的介绍:Research on EventMachine
关于NATS源码级别的介绍,可以参考我们之前的这篇文章:Research on NATS
一、以NATS为线索部署CloudFoundry的更多细节
我们之前曾写过一系列的基于dev_setup的安装与部署文章:
Part 1、单节点安装:
http://blog.csdn.net/resouer/article/details/7939952
Part 2、基于Iaas进行多节点部署:
http://blog.csdn.net/resouer/article/details/8010756
在上述文章的描述中,我们其实已经可以看到NATS在我们部署CF时所扮演的关键角色。没错,是否跟NATS沟通顺畅,也是我们检验各个组件正常工作的重要标准之一。所以,我们在这里着重解决两个问题:
1、如何以模板为基础安装CF集群?
2、如何为这个集群实现LB和Custom Domain?
回忆一下我们之前的工作步骤:
- 先按照Step A安装单节点CF的VM
- 使用该VM做模板,克隆出所需数目的VM
- 用NATS把每一个安装了完整CF的VM连接起来
- 进行一些其他配置
- 分别启动所需的组件
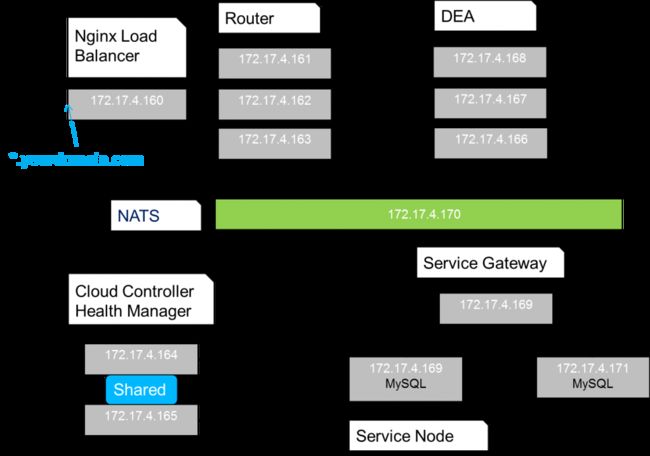
好了,在上面文章的基础上,我们这次提供一个更加清晰的部署策略:(后面的版本组件会不断增加,但是这里的思想是确定的)
Nginx Load Balancer:使用Nginx为Router做负载均衡,绑定LB到*yourdomain.com
Router:作为LB的server,3个节点
Cloud Controller:2个节点,共享文件系统和配置数据库
Health Manager:与CC共用2节点
DEA:3个节点,数量根据应用不同而不同,一般根据资源需求动态添加
Service Gateway:1个节点,不支持集群,一种服务需要一个Gateway
Service Node:2个节点,根据需求可动态添加,一般一种服务1~2个节点
NATS:轻量级不支持集群,只能在单节点上
其他:服务工具类组件,打包组件,用户控制组件各1-2节点(图中未画出,具体类似于service_lifecycle的各个节点)
接下我们需要到这些节点中做下面的简单工作:
1、login到每个VM中,比如CloudController
2、找到./devbox/config/cloud_controller.yml中nats://nats:[email protected]:4222
3、修改该IP为NATS的IP,
4、对其它的node做这项工作,然后启动该节点上需要的那几个组件即可(../vcap_dev start xxx xxx ...)
然后是一些额外的配置工作,包括:
1、配置CC的external_url,以及CC和HM的共享文件和数据库(参见Part 2里的说明以及 Step 5. Other things TODO部分)
2、多个service node的编号
3、单独启动nats节点上的nats-server服务
4、Custom Domain、Muti-router与Nginx LB的配置
需要重点补充下4 的操作。在Part 2 里我们提到过:在你的IaaS层的网络功能里把*.yourdomain.com绑定到这个LB上。这样所有对该URL的访问会首先经过该LB(当然该LB也可以是个Nginx集群)。
而在前面的额外配置中,api.yourdomain.com已经分配给CC了。其实CloudFoundry之所以能解析api.yourdomain.com到你的CC,靠的是Router的路由功能,这在后面的原理部分会详细说明。
所以,当你执行vmc targert api.yourdomain.com时,你的request实际上是这样转发的:
vmc target api.yourdomain.com -> LB -> LB选择某一个Router -> Router选择某一个CloudController
二、以NATS和EM为主线的CloudFoundry源码导读
1、NATS
这里我们关注的问题有两个:
1、NATS客户端的生命周期与组件的运行关系如何?
2、NATS是否负责处理CF中所有管理类消息的中转?
首先强烈学习官方的README:https://github.com/derekcollison/nats
阅读源码的话,请重点关注server,connection,sublist这几个部分,动手实验的时候使用nats-server -c "your_config_file"来用自己新写的配置文件启动nats server。具体的参数表在这里:
https://github.com/derekcollison/nats/blob/master/lib/nats/server/options.rb#L10
NATS作为CF的神经网络,负责者组件之间的通讯和交互工作:
这种策略下,发布者与订阅者不需要相互知道,只要按照订阅的主题进行发布,订阅者就能收到消息。
每个CF组件的启动,很多都需要启动EventMachine和NAST,并在NATS启动过程中做下面几个事情:
EM.epoll # EM默认使用select系统调用,所以这里往往使用处理能力更高的epoll调用
EM.run do
...
NATS.start(:uri => @config['mbus']) do
configure_timers # 设置基于EM的定时器
register_as_component # 向VCAP::Component注册本组件的信息以便监控本组件信息
subscribe_to_messages # 设定订阅列表
end
...
end
其实,并不是所有的消息传递都是有NATS来做的,NATS在CF中起作用的场景应该是这样描述:
Publisher并不知道也没有必要关心Subscriber的存在和数量,同样后者对前者的存在也无需关心,更重要的是Pub和Sub的工作机制应该是基于“事件“和”响应“的。
所以,对于有一些需要在知晓对方信息的基础上建立通信的场合,CloudFoundry中会采用HttpSever的方式来响应request,比如用户经由Router访问到应用instance,以及Service Gateway与CloudController之间的关系。下面的图示向您展示了这种不同的信息传递方式在CF中的使用场合:

在上图中我们可以清晰地看到,只有蓝色线画出的场景(当然图中给出的只是比较典型的几个场景)才是NATS的主要用武之地。不过,NATS以及EM为我们提供的并不只只是消息的传递,而是基于消息和事件驱动的编程方式以及松耦合和自治式的组件结构。
NATS的通信机制基于EM所提供的TCP连接功能。每次会话起始于NATS客户端发起请求与服务器端建立连接,然后NATS服务器端回复一条自己的INFO信息作为响应,这样简单的过程之后NATS就已经可以工作了。
NATS的消息协议非常简单:所有的消息都由一个操作指令开头,然后各个参数以空格分开跟在操作指令之后。比如,NATS发布消息的一条完整指令为:PUB <TOPIC> <REPLY_TO><MSG_SIZE>,当服务器端收到这条指令之后它会转到“等待数据”的状态,并等待客户发出一条包含消息内容的指令:PUB <PAYLOAD>,然后服务器端收到客户端发来的消息内容:payload。这样publish的工作就完成了。同理,NATS订阅消息的过程也是类似的。我们在这里给出一次订阅和发布交互中TCP数据流的顺序图:
我们可以看到这次sub-pub的交互过程如下:
1. 双方的连接成功建立之后(CONNECT操作成功得到响应之后),客户端首先订阅了主题为foo的消息,SID为1。
2. 服务器端会记录下这主题和SID并响应+OK。
3. 客户端发布了一个主题为foo的消息,长度为12,然后紧接着发来了消息数据“Hello World!”。
4. 服务器端通过主题匹配找到该主题订阅者的SID是1,于是服务器端把这个消息的主题foo,SID值1,还有消息本身携带的数据“Hello World!”一起返回给客户端。
客户端根据SID =1从自己维护的订阅者列表里找到对应的订阅者,然后把服务器端返回来的数据交给订阅者去使用,一次对PUB操作的响应也就完成了。NATS服务器端负责进行主题匹配的数据结构被称作Sublist,关于这部分数据结构的存储可以参考前面有关NATS原理的文章。
2、Router
Router作为CF的请求访问分配与转发门户,主要承担着以下四种任务:
- 处理所有来访的HTTP流量
- 将对URL的访问路由至具体的实例或CF组件
- 应用实例之间分发流量实现均衡负载
- 从DEAs获得信息并实时更新路由表
我们这里重点关注的问题是:
1、Router究竟是如何实现了某个域名与IP的绑定功能?
2、Router选择instance的策略是怎样的?
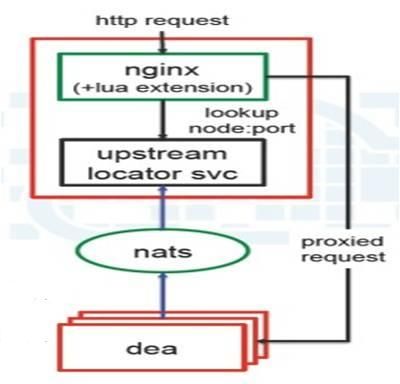
上图展示了Router的工作流程,它的原理其实很容易描述:
- 组件和应用实例均被注册到某个ULR上
- Nginx通过lua脚本把lookup请求发送给一个由ruby代码建立的http server
- Server根据URL查询注册信息,选择某一具体的ip:port,转发请求
- Session Sticky:将被转发给上次访问的应用实例
所以这里Router订阅的消息无外乎两种:register和unregister
def setup_listeners
NATS.subscribe('router.register') { |msg|
msg_hash = Yajl::Parser.parse(msg, :symbolize_keys => true)
return unless uris = msg_hash[:uris]
uris.each { |uri| register_droplet(uri, msg_hash[:host], msg_hash[:port],
msg_hash[:tags], msg_hash[:app]) }
}
NATS.subscribe('router.unregister') { |msg|
msg_hash = Yajl::Parser.parse(msg, :symbolize_keys => true)
return unless uris = msg_hash[:uris]
uris.each { |uri| unregister_droplet(uri, msg_hash[:host], msg_hash[:port]) }
}
end
而它们对应的回调函数在这里: https://github.com/cloudfoundry/router/blob/master/lib/router/router.rb#L171 代码段中可以看到:
log.info "Registering #{url} at#{host}:#{port}"
这就是我们很熟悉的Router启动时打印出的一系列的register log
Router中app的信息是需要不断轮询着的,所以会有一个check_registered_urls定时被执行。值得注意的是,在此期间会有这样的判断:
to_drop << droplet if ((start - droplet[:timestamp]) > MAX_AGE_STALE)
然后符合该条件的instance会被unregister掉。这里的“陈旧instance“是通过时间戳来判断的,默认2min内没有被更新时间戳的instance会被抛弃,而负责更新instance时间戳的工作由DEA负责。
在Router的这个部分中有一处EM与NATS的非常典型的用法:
def setup_sweepers
@rps_timestamp = Time.now
@current_num_requests = 0
EM.add_periodic_timer(RPS_SWEEPER) { calc_rps }
EM.add_periodic_timer(CHECK_SWEEPER) {
check_registered_urls
}
if @enable_nonprod_apps
EM.add_periodic_timer(@flush_apps_interval) do
flush_active_apps
end
end
end
而在flush_active_apps这个方法中,我们看到了EM的一种使用模式:先使用defer将任务放到线程池中进行处理,但是在执行期间,又需要在主线程中通过NATS发布消息,于是使用到了next_tick回到Reactor周期中来执行:
def flush_active_apps
... ...
EM.defer do
msg = Yajl::Encoder.encode(@flushing_apps.to_a)
zmsg = Zlib::Deflate.deflate(msg)
log.info("Flushing active apps, app size: #{@flushing_apps.size}, msg size: #{zmsg.size}")
EM.next_tick { NATS.publish('router.active_apps', zmsg) }
@flushing = false
end
Router的另一个核心部分就是router/ lib/router/router_uls_server.rb,这个文件为Router建立起了负责处理来访URL的一个基于sinatra的HTTPserver (图中的upstream locator svc)。
见:https://github.com/cloudfoundry/router/blob/master/lib/router/router_uls_server.rb#L10
这部分的可读性非常强:
Router首先解析该request body
# Parse request body
uls_req = JSON.parse(body, :symbolize_keys => true)
raise ParserError if uls_req.nil? || !uls_req.is_a?(Hash)
stats, url = uls_req[ULS_STATS_UPDATE], uls_req[ULS_HOST_QUERY]
sticky = uls_req[ULS_STICKY_SESSION]
如果访问类型是URL的话,直接在这个server上查询URL的注册信息:
# Lookup a droplet
unless droplets = Router.lookup_droplet(url)
Router.log.debug "No droplet registered for #{url}"
raise Sinatra::NotFound
end
然后做判断:如果来访的request是带session的,那么直接路由到上一次访问的instance中:
droplet = check_original_droplet(droplets, host, port)
否则的话,从刚刚lookup到的droplet中随机选择一个。最后组装一个response以便client端获取正确的响应:
uls_response = {
ULS_STICKY_SESSION => new_sticky,
ULS_BACKEND_ADDR => "#{droplet[:host]}:#{droplet[:port]}",
ULS_REQUEST_TAGS => uls_req_tags,
ULS_ROUTER_IP => Router.inet,
ULS_APP_ID => droplet[:app] || 0,
}
这样,你的request 就被转发到目的地了。
需要注意的是:对于Router而言,组件和instance都是一样的,所以在register时,CloudController,uaa,service_broker等组件都会被注册到Router中。比如api.vcap.me其实就是注册到了CC的ip:port上。这样,你的管理类型指令也是由Router进行转发的。
最后有一些问题要说明,这种结构下Router本身需要启动一个HTTPserver :client -> [ nginx -> lua ->http server ] -> CF。这其实是两次转发,更好的设计是不必再次经过一次server就能够被路由出去。
3、CloudController
- 用户控制
- 与stager模块一起对应用进行打包上传和预处理
- 应用和服务的生命周期管理
- 应用运行资源管理
- 通过RESTfulAPI来进行交互
CC就是api.vcap.me对应的节点,是整个集群的管理中枢。CC是一个典型的ROR项目,所以熟悉下ROR的目录结构对于这部分的研究是很有帮助的,这里是篇极好的guide: http://ihower.tw/rails3/firststep.html
在../config/routes.rb里定义了客户端(比如vmc)与CF进行交互的API。熟悉ROR的话,我们就可以在/app目录下很快的定位到对于的controller。
与应有有关具体的业务逻辑由app_manager类负责,这一部分也是最值得钻研的部分,比如启动应用的start_instance(message, index),寻找DEA的find_dea_for(message)方法等等。而从NATS的角度来看,CC 功能可以这么描述:
根据用户发来的指令,组装所需的信息(MSG),然后使用NATS.publish广播出去,这样订阅了对应主题的组件就能够按照指令的意图完成后续操作。这个例子在一开始NATS的部分就已经提到了。由于在接下来我们会不断涉及到CC的实际工作,所以这里不做单独分析。
4、Stager

CC的一个重要作用就是与Stager合作,制作droplets,并它们部署到合适的DEA运行起来。Stager就是用来接管制作droplets的组件。这里我们关注问题是:
1、打包的过程具体是在所什么?
2、CF到底如何为我们的APP提供运行容器呢?
应用之所以能够运行起来,以java web为例子,用户端上传的只是可执行文件以及外部依赖(war包)而已,而这些可执行文件需要放在容器中才能运行的。所以在staging的过程中,很重要的一点就是制作一个bits+server组成的“可运行起来的Droplet”。CloudFoundry提供的embeded server 是Tomcat。
Stager其实只是一个入口,它通过图示的方式调用staging plugin来执行打包操作,这样的设计方便开发者对CF进行扩展以支持其他的runtime,所以staging plugin也被单独抽象成了gem包。
java_web的plugin主要做两个事情:
1、将war包解压出来后放到Tomcat的ROOT目录下,这样将来直接执行./bin/catalina.sh run就能运行起来这个server并使应用能被访问到
2、配置Tomcat的catalina_opts,使得该Tomcat能够使用到DEA中的runtime。
另外,如果我们看下这个Tomcat的配置文件模板:https://github.com/cloudfoundry/vcap-staging/blob/master/lib/vcap/staging/plugin/java_web/resources/generate_server_xml,我们会发现shutdown的端口被设为dsable:
<Server port="-1">
这是因为CF中的应用访问端口是分配出来的,指定shutdown端口反而会kill掉正常的CF进程。
关于CF中server到底要做哪些修改才能正常运行,推荐阅读 http://cnblog.cloudfoundry.com/?p=382
这篇文章使用standalone方式支持Tomcat7就是模拟staging的工作,把tomcat7+app作为一个整体部署到CF上运行起来的实例。所以在CF中如何支持jetty,weblogic等容器的方法,相信大家也略知一二了。
5、DEA
NOTE:我们这里的DEA略有过时,这个版本还没有warden,不过新版的stable的dea_ng应该已经在github上了。另外,DEA中使用fiber(ruby的一种非抢占式多线程模型)来处理比如下载打包之类的耗时操作,这与其他组件有所不同。
这里我们关注的问题包括:
1、应用到底是如何启动的?
2、执行push的时候,CF如何从几个DEA之间做出选择?
3、DEA怎样获得droplets文件来运行?
4、应用的监控是怎样的?
大家都知道DEA是应用运行的主场,也是整个PaaS中与应用关系最密切的部分,所以我们不妨先通过一个场景来描述其工作方式:
- 当我们启动一个app instance的时候,DEA节点会从指定位置下载一个Droplet的副本启动起来
- 如果我们扩展该app到10个instances,那这个Droplet就被会复制十份
- CF通过NATS来“发现”DEA,DEA根据自己的“能力”来立即或推迟响应请求,instance会被下载到最先响应的DEA上启动
- 启动后的instance会被分配PID和响应端口,它会将自己的IP+Port信息注册到Router中对应的URL下
- DEA负责把应用实例的运行状态定时报告给HealthManager
整个过程如下图所示:

前面已经提到过,DEA start的时候,在../lib/dea/agent.rb除了初始化各个变量外,还会订阅一系列的消息,最后在向其他组件广播自己启动的消息:
# Setup our listeners..
NATS.subscribe('dea.status') { |msg, reply| process_dea_status(msg, reply) }
NATS.subscribe('droplet.status') { |msg, reply| process_droplet_status(msg, reply) }
NATS.subscribe('dea.discover') { |msg, reply| process_dea_discover(msg, reply) }
NATS.subscribe('dea.find.droplet') { |msg, reply| process_dea_find_droplet(msg, reply) }
NATS.subscribe('dea.update') { |msg| process_dea_update(msg) }
NATS.subscribe('dea.stop') { |msg| process_dea_stop(msg) }
NATS.subscribe("dea.#{uuid}.start") { |msg| process_dea_start(msg) }
NATS.subscribe('router.start') { |msg| process_router_start(msg) }
NATS.subscribe('healthmanager.start') { |msg| process_healthmanager_start(msg) }
NATS.subscribe('dea.locate') { |msg| process_dea_locate(msg) }
# Recover existing application state.
recover_existing_droplets
delete_untracked_instance_dirs
EM.add_periodic_timer(@heartbeat_interval) { send_heartbeat }
EM.add_periodic_timer(@advertise_interval) { send_advertise }
EM.add_timer(MONITOR_INTERVAL) { monitor_apps }
EM.add_periodic_timer(CRASHES_REAPER_INTERVAL) { crashes_reaper }
EM.add_periodic_timer(VARZ_UPDATE_INTERVAL) { snapshot_varz }
EM.add_periodic_timer(DROPLET_FS_PERCENT_USED_UPDATE_INTERVAL) { update_droplet_fs_usage }
NATS.publish('dea.start', @hello_message_json)
send_advertise
这里很多的订阅是带有reply的,这意味着回调方法执行结束后需要使用 NATS.publish(reply, response.to_json) 来返回处理结果。
所以,我们在这一部分按照NATS为主线进行研究是再适合不过的了。
send_heartbeat方法是DEA向HM发送心跳的部分,这个heartbeat是HM监视DEA中instance状态的重要部分,至于HM收到这个心跳之后做什么我们在HM的部分说。
大多数方法都能直接从名字和逻辑中判断个差不多,这里我们单独看几个有意思的地方:
1、process_dea_discover(message, reply)
......
# Pull resource limits and make sure we can accomodate
limits = message_json['limits']
mem_needed = limits['mem']
droplet_id = message_json['droplet'].to_i
if (@reserved_mem + mem_needed > @max_memory)
@logger.debug('Ignoring request, not enough resources.')
return
end
delay = calculate_help_taint(droplet_id)
delay = ([delay, TAINT_MAX_DELAY].min)/1000.0
EM.add_timer(delay) { NATS.publish(reply, @hello_message_json) }
... ...
我们可以看到DEA是如何响应“发现DEA”的:在前面check过空间,runtime等支持后,DEA首先判断DEA的内存是否足够,然后调用calculate_help_taint来计算一个延迟,最后使用根据这个延迟时间来做出响应。而这个计算延迟的部分就更清晰了:
def calculate_help_taint(droplet_id)
# Calculate taint based on droplet already running here, then memory and cpu usage, etc.
taint_ms = 0
already_running = @droplets[droplet_id]
taint_ms += (already_running.size * TAINT_MS_PER_APP) if already_running
mem_percent = @reserved_mem / @max_memory.to_f
taint_ms += (mem_percent * TAINT_MS_FOR_MEM)
# TODO, add in CPU as a component..
taint_ms
end
计算延迟考虑了两个因素:
1、该DEA上对应droplet已经启动的instance数量 2、该DEA上的资源使用情况。然后两者求和作为延时值。
这里还没有warden,所以这个mem百分比可能会出现超出limit的情况。
由于订阅了xxx.start这样的消息Router启动后DEA向Router注册自己持有的instance,给HM发送heartbeat的过程也是类似的:
def process_router_start(message)
return if @shutting_down
@logger.debug("DEA received router start message: #{message}")
@droplets.each_value do |instances|
instances.each_value do |instance|
register_instance_with_router(instance) if instance[:state] == :RUNNING
end
end
end
在register_instance_with_router,DEA把instance的信息封装成msg_json,然后NATS.publish('router.register', msg),由Router负责处理。
2、从CC处下载droplet并在DEA建立本地可执行目录的方法:def stage_app_dir(bits_file, bits_uri, sha1, tgz_file, instance_dir, runtime)
在这个方法的一开始就对这个过程的思路做了说明:
... ...
# See if we have bits first..
# What we do here, in order of preference..
# 1. Check our own staged directory.
# 2. Check shared directory from CloudController that could be mounted (bits_file)
# 3. Pull from http if needed.
... ...
DEA首先判断本地是否已经有了应用的可执行目录和所需的文件,如果已经存在,直接使用就好了
if File.exist?(tgz_file)
@logger.debug('Found staged bits in local cache.')
如果不存在,首先判断DEA与CC之间建立了共享文件系统的话,我们直接使用文件操作从CC的/var/vcap/shared/下把这些文件cp过来(需支持FUSE)
else
# If we have a shared volume from the CloudController we can see the bits
# directly, just link into our staged version.
if File.exist?(bits_file) and not @force_http_sharing
@logger.debug("Sharing cloud controller's staging directories")
start = Time.now
FileUtils.cp(bits_file, tgz_file)
@logger.debug("Took #{Time.now - start} to copy from shared directory")
DEA和CC这部分文件共享在通常情况下是需要手动配置的。简单地说,就是建立一个NFS server和共享目录,然后把CC和DEA都mount这个目录。当然,我们可以使用其他支持FUSE的文件系统来实现HP/HA,毕竟这部分用户应用的存储是十分重要的。
如果共享文件系统没有建立,那我们还有最后一种方式:直接通过HTTP方式下载droplet。
download_app_bits(bits_uri, sha1, tgz_file)
这个方法会通过EM向下载URL发送HttpRequest,并以流的方式把文件解压写入到DEA本地的目录中。
droplet下载并解压后,删除原来的压缩文件,然后还要绑定runtime才能运行:
def bind_local_runtime(instance_dir, runtime_name)
... ...
startup_contents = File.read(startup)
new_startup = startup_contents.gsub!('%VCAP_LOCAL_RUNTIME%', runtime['executable'])
return unless new_startup
FileUtils.chmod(0600, startup)
File.open(startup, 'w') { |f| f.write(new_startup) }
FileUtils.chmod(0500, startup)
end
上面方法会将VCAP_LOCAL_RUNTIME变量被替换成当前DEA runtime的可执行文件路径(比如这种:../cloudfoundry/.deployments/devbox/deploy/rubies/ruby-1.9.2-p180/bin/ruby)。从某种意义上来说,应用之间共享runtime在CF中是不可避免的;但从另一方面讲,这种对运行环境轻量级的封装不需要用户调用特定的API或导入外部依赖,其实是最大的优点。
上述stage_app_dir的执行过程实际上交给一个fiber(协程)完成的。当stage_app_dir方法发现使用bits_uri下载droplet的工作是在进行中的(说明有其它DEA在download同一个droplet),它会通过Fiber.yield就可以挂起当前的下载直到被resume。同样,在stage_app_dir里负责下载方法download_app_bits中也是如此:
... ...
f = Fiber.current
@downloads_pending[sha1] = []
http = EventMachine::HttpRequest.new(bits_uri).get
... ...
http.callback {
file.close
FileUtils.mv(pending_tgz_file, tgz_file)
f.resume
}
Fiber.yield
... ..
当下载的请求发出后,先挂起当前调用自己的Fiber,当请求获得响应后在回调方法中完成剩余的文件操作并resume这个Fiber。
3、最后一个提到的方法是monitor_apps,尽管没有warden的情况下资源监控的作用并不大,但鉴于这一点是我们必然会涉及的部分,还是稍作说明。
实际上负责搜集instance资源信息的是这个方法:monitor_apps_helper,而每个instance对应的进程资源则直接使用`ps axo pid=,ppid=,pcpu=,rss=,user=`来获得。
metrics.each do |key, value|
metric = value[instance[key]] ||= {:used_memory => 0, :reserved_memory => 0,
:used_disk => 0, :used_cpu => 0}
metric[:used_memory] += mem
metric[:reserved_memory] += instance[:mem_quota] / 1024
metric[:used_disk] += disk
metric[:used_cpu] += cpu
end
... ...
VCAP::Component.varz[:running_apps] = running_apps
VCAP::Component.varz[:frameworks] = metrics[:framework]
VCAP::Component.varz[:runtimes] = metrics[:runtime]
而资源的使用会被保存到metric这个数据结构中,最后所有的监控信息都被注册到VCAP::Component.varz下。至于如何在客户端访问这个../varz变量,cherry_sun之前已经有文章做出了说明。
DEA这一部分的解读其实略过了一个很重要的内容:droplet和instance的状态转化——这对监控来说是一个非常重要的部分,今后补上。
6、HealthManager
HM的功能和作用比较单一,而我们继续以NATS作为线索可以看到HM订阅的消息如下:
NATS.subscribe('dea.heartbeat') do |message|
@logger.debug("heartbeat: #{message}")
process_heartbeat_message(message) # 处理DEA发来的心跳
end
NATS.subscribe('droplet.exited') do |message|
@logger.debug("droplet.exited: #{message}")
process_exited_message(message) # 处理DEA关闭instance后的消息
end
NATS.subscribe('droplet.updated') do |message|
@logger.debug("droplet.updated: #{message}")
process_updated_message(message) # 处理更新DEA instance的消息
end
NATS.subscribe('healthmanager.status') do |message, reply|
@logger.debug("healthmanager.status: #{message}")
process_status_message(message, reply) # 处理查询HM status的消息
end
NATS.subscribe('healthmanager.health') do |message, reply|
@logger.debug("healthmanager.health: #{message}")
process_health_message(message, reply) # 处理查询HM health的消息
end
另外HM会定时执行analyze_all_apps来分析应用和instance的状态,该方法中使用了EM.next_tick来更有效率地执行这个分析过程,防止主进程阻塞在这里(参见前面EM扫盲的EM#next_tick部分)。在分析完成之后,应用的信息和状态会被注册到VCAP::Component.varz中。
在分析APP的方法中,HM需要关注的是droplet的状态和instance的状态。
如果发现instance的状态为down,而对应droplet的状态确是started,那HM会认为此instance需要restart,这时该instance的id会被记录到missing_indices中,然后HM调用start_instances(app_id, missing_indices)来启动对应droplet的一个instance。
当然,启动instance的工作是由CC来做的,所以HM只需要组装好start_msg,然后使用NATS来publish一个专门的消息:
@logger.info("Requesting the start of missing instances: #{start_message}")
NATS.publish('cloudcontrollers.hm.requests', start_message.to_json)
这样,订阅了改主题消息的CC就会根据传来的msg启动一个新的instance。
7、Service
NOTE:Service部分代码更新很多,这里不能全照顾到。Service部分作为CloudFoundry里一个具有相当规模且较为独立的组成部分,我们Lab会有单独的篇幅来专门讲述。所以我们这里尽量High-level一些
这里我们的问题有:
1、我们为什么能访问到CF帮我们建立的数据库等服务?
2、CF建立数据库等服务的机制是怎样的?
3、Gateway与Node的关系是什么样的?
Service部分在CF中涵盖的种类非常多,所以CF把Gateway和Node中的公共代码抽象成了一个gem,即vcap-service-base,然后各种service自己通过重写指定的方法来实现具体的细节。这样,不同种类的service可以有统一的接口来遵循,使得诸如添加自定义service这样的工作才有章可循。
在这一部分,Service Gateway - CC - Service Node这条线上NATS实际上并不是信息传递的最主要方式。下图说明了Service部分组件间的联系:

我们只提一些重要的细节:
在ServiceGateway启动之后,首先应该让CloudController知晓自己的存在,所以在asynchronous_service_gateway.rb中需要向CC发送heartbeat
心跳的作用是向CC发送一个注册请求,实际上是一个create(POST)请求,而这个请求的目的URL是:
@offering_uri = "#{@cld_ctrl_uri}/services/v1/offerings"cld_ctrl_url就是CC的URL,即我们熟知的api.vcap.me。最后,gateway会查看CC的响应是不是200。
对照CC的routers.rb文件,我们可以知道在接收到上述请求后CC的工作实际上是向数据库中插入一条(如果没有的话)这个gateway的信息,这样注册就生效了。
好了,剩余的CC与Service Gateway的交互工作也都是通过这条handler途径来进行的,您可以参考我们的这篇文章深入学习:Cloud Foundry Service Gateway源码分析
现在回到我们基于NATS的gateway与service node的交互过程上来。
以NATS为主线,我们首先看一下Service Node的公共部分.../vcap-service-base/lib/base/node.rb的订阅,非常简单:
%w[provision unprovision bind unbind restore disable_instance
enable_instance import_instance update_instance cleanupnfs_instance purge_orphan
].each do |op|
eval %[@node_nats.subscribe("#{service_name}.#{op}.#{@node_id}") { |msg, reply| EM.defer{ on_#{op}(msg, reply) } }]
end
%w[discover check_orphan].each do |op|
eval %[@node_nats.subscribe("#{service_name}.#{op}") { |msg, reply| EM.defer{ on_#{op}(msg, reply) } }]
end
第一个订阅需要node_id参数,订阅主题是在本node上进行的操作。而第二个订阅则只针对discover操作和check_orphan操作,这两个操作都是针对所有node的,所以没有id的区别。
按照老规矩,每个Service Node节点在启动后,都要使用NATS向外publish自己的信息。以MySQL为例,它需要发布的信息包括自己的id,支持的版本,service plan,还有这个node的capacity等。当然在Service Gateway中一定订阅了它需要的消息(文件位置:.../vcap-service-base/lib/base/provisioner.rb):
%w[announce node_handles handles update_service_handle].each do |op|
eval %[@node_nats.subscribe("#{service_name}.#{op}") { |msg, reply| on_#{op}(msg, reply) }]
end
好了,现在provisioner的作用应该能了解了:如果说前面asynchronous_service_gateway.rb是Gateway与CC进行交互的部分,那么Provisioner就是Gateway与Service Node交互的部分了。这里的设计分层很清楚。
这样通过announce操作,ServiceGateway就能记录下所有Service Node的有用信息了。
说完了sending announcement,我们现在简单回顾下create service操作到底是怎么执行的:
- CC把一个provsion request交给Service Gateway
- Gateway调用provisioner#provision_service(req) 来执行整个provision操作
所以provisioner#provision_service(request, prov_handle=nil, &blk)方法就是创建service实例的核心部分:
首先,我们要从目前维护的nodes列表里挑选best_node
然后在这个node上执行provsion操作,这里才是我们关注的重点,请看这个方法:
subscription =
@node_nats.request("#{service_name}.provision.#{best_node}", prov_req.encode) do |msg|
... ...
end
在这一段方法中,prov_req 是我们刚刚新建出来的 ProvisionRequest对象,它被通过NATS#request方法交给best_node,而当这个node完成了provision操作之后,返回的reply就传递给request代码段的msg参数进行解析,并在最后把成功provsion生成的credentials等一些列服务相关的信息会打印出来。
这一定要注意的是NATS的通信是异步操作,我们千万不能先NATS#request然后在接下来的代码里再使用返回来的msg。所有的工作都应该在do ... end这一部分回调的代码段里执行完。
那么Service Node究竟做了哪些操作完成了provision呢?
在公共的.../vcap-service-base/lib/base/node.rb中,我们会看到on_provision(msg, reply)方法主要的工作,其实就是负责在service node上生成出credencial信息出来,包括数据库名,用户名,密码等,同时修改该node的capacity等信息,最后把这些信息都返回给gateway的provisioner。
当然具体的操作会根据数据库不同而不同,这也是除了上面公共部分之外各个Service Node需要自己实现的provision方法,以MySQL为例,在../vcap/services/mysql/lib/mysql_service.rb中,我们可以看到其中的provision方法:
1、生成上述的credencial信息
2、按照生成的database name在这个service node上创建数据库
3、返回上述信息
前面的create-service操作为我们创建了数据库,同时也生成了user,password信息,而bind-service操作实际上就是在之前创建的数据库中为我们之前生成的用户分配权限:
"GRANT ALL ON #{name}.* to #{user}@'%' IDENTIFIED BY '#{password}' WITH MAX_USER_CONNECTIONS #{@max_user_conns}"
这样子持有这些credencial信息的应用实例就可以像普通的应用那样访问这个数据库了。
三、总结
基于NATS和EventMachine的CloudFoundry原理分析就写到这里,文章的作用一方面是补充之前的CF部署细节,另一方面也是为了作为CF源码导读供Lab使用。由于CF代码更新非常快,我们这篇文章的内容实际上已经过时很多了。我们会在接下来的时间里有计划地开展新的工作,包括CC_ng,DEA_ng,warden,HMv2的研究,以及基于BOSH的大规模部署等等。