一种复杂度为O(n)的排序算法:位操作应用之位排序
——位运算应用篇(3)
摘要
本篇仍然关注位操作的应用,通过前面的两篇文章(《非常给力:位运算求组合》,《简单、易懂:位运算之求集合的所有子集》),我们已经略见了位操作之强大威力。如果说那两篇文章中讲解的应用比较偏僻,那么本篇介绍的是位操作在广为人知的排序算法中的应用——位排序。本篇讲述了位排序的两种实现方法,在描述上尽量做到简单、通俗、易懂。
本篇内容并不新颖,如果您关注过大量数据处理或者看过各大牛X公司的面试系列或者读过《编程珠玑》,那么应该对位排序非常熟悉,即便是这样,本篇作者仍然希望你挤出一些你的宝贵时间来看完后面的内容,因为作者非常希望您能提一些意见,或者更正一些错误。
引例
在切入正题之前,我们来看一个引例:有一个数组,乱序存放了某个班级的所有学生的学号,已知该班级的学生数目不超过50人,并且学号范围是0到49(不一定连续,因为有些同学可能中途被开除了,作者本人就是导致当年那个大学班级的学号不连续的第一人,详情见《有感于“要像狗一样活下去”》),现在请你对这个数组排序,要求时间复杂度必须小于O(nlog2(n))。
上面的引例并不属于大量数据处理问题,不是用来做位排序的好例子,但是它却是个引子,因为其时间复杂度的特殊要求。后面我们将看到位排序实际上适合处理大量数据排序问题。
最初的尝试
一看到这样的题目,我们的大方向是明确的,那就是排序呗,于是我们开始尝试各种主流的排序算法,看看能否满足要求。最简单、最基础、也是最容易实现的冒泡排序、插入排序、选择排序时间复杂度为均O(n2),不满足要求。高级的排序算法如快速排序、堆排序、归并排序、希尔排序等时间复杂度为O(nlog2(n)),仍然达不到时间复杂度小于O(nlog2(n))的要求。事实上绝大多数数据结构教程上都说了最好的排序算法时间复杂度是O(nlog2(n))。没错,确实如此,因为它们讲解的是通用的排序算法,而这里的引例有几个特殊条件可供我们使用:
1、 待排序的元素的最大范围已知(从0到49)
2、 待排序的元素不重复,因为不存在两个学号相等的学生(非常隐蔽的、但是非常重要的条件)
3、 待排序数据基本充满整个数据范围(只有少数人会被开除)(这一点也是非常重要的,后面我会解释)
4、 小于O(nlog2(n))的时间复杂度(与其说这是可以利用的条件,还不如说这是孙悟空头上的紧箍咒)
既然常用的排序算法不能满足要求,那么我们就得想其他方法了。我们都知道算法的时间复杂度和空间复杂度是一对矛盾体,通常可以采取以空间换时间的方法来降低算法的时间复杂度。后面讲的函数(sort_1)是我大一时想出来的,当时是为了解决数据结构上的课后习题,还记得当初为自己的这个实现激动了许久。在给出程序之前,先说一下我当时的思路:1、用一个标记数组记录每一个数是否存在于待排序数组中,如果存在而标记1,否则标记0;2、扫描标记数组,并根据它重新填充原来的待排序数组。我的程序看起来是这样的
using namespace std;
#define NUMBER_RANGE 50
#define ARRAY_SIZE 10
int a[ARRAY_SIZE] ={1,13,3,42,7,23,5,37,26,10};
void sort_1(int a[],int N) //N是a中待排序元素个数
{
int i,j;
int* p = new int[NUMBER_RANGE]; //这里浪费了40*4=160byte
memset(p,0,NUMBER_RANGE*sizeof(int));
for (i = 0;i<N;i++)
{
p[a[i]] = 1;
}
for (i = 0,j=0;i<NUMBER_RANGE;i++)
{
if (p[i]==1)
{
a[j++] = i;
}
}
}
sort_1中定义了一个标记数组(int* p = newint[Range];)并包含了两个for循环,第一个循环循环N次,其作用是扫描待排序数组a中的每个元素,并把标记数组的相应元素赋值为1,见p[a[i]]=1;第二个for循环循环Range次(Range代表了该班级学生的学号范围),其作用是扫描刚才的标记数组,并且每扫描到一个1就把其对应的下标(等于某个学生的学号)存到原来的数组a中去,当这个for循环结束后,数组a就保存了排序后的学号。
上面的算法复杂度由两个for循环中的最大者决定,而Range大于等于N,因此其复杂度由第二个for循环决定的,因此其复杂度为O(Range)。由于前面的条件3可知:待排序数据基本充满整个数据范围,因此Range略大于N(程序中a数组大小为10,这是我为了少打字而偷懒了),故该算法的时间复杂度可认为是O(N)。我们为了达到降低时间复杂度的目的,却付出了Range*sizeof(int)个字节的空间(int* p =new int[Range];)可以说这个程序是功过参半,那么是否有必要减少内存空间的消耗呢?如果需要,又该如何做到减少内存的消耗呢?这将是本篇后面讨论的主题。
少耗内存的必要性
前面我给的引例只是对某个班级的学生的学号排序,因此其待排序的元素个数相对较少(最多50),然而假设要排序的对象是全中国人民的省份证号码呢?那将有13亿个数字,这还是非常保守之估计(相信还有很多“黑人”,在我家那里把没有户口是人称为黑人,通常是超生的孩子没有户口,因此也没有土地,我小的时候就属于“黑人”,由于没分到土地,每次吃饭都得挨说,当初因为超生了我,我爸差点失去了教师公职,后来爸要给我取名“伍超生”,要不是我妈阻拦,估计它就是我现在的名字了。那个时候很多超生的人其名字都跟超生有关,比如我家隔壁的孩子由于是超生而被罚款860元,因此它的小名就是八百六,幸好当年罚款金额不是250)。废话扯多了,如果待排序是中国人的身份证号码,那么上面的程序将改成:int* p = new int[1300000000];这究竟要耗多大的内存呢?笔算一下吧:1300000000*4 = 5200000000byte = 4960M = 4.8G。
O(N)的算法还有啥用?
既然前面那个O(N)的方法在待排序数据量巨大时,其消耗的内存也很巨大,那么它还有啥用?答案是它仍然非常有用,前提是我们能想法减少它消耗的内存。那么能否减少它消耗的内存呢?答案是肯定的,很快,我就想到了各种基本数据类型占用的内存不一样,一个int要耗4byte,而一个char只耗1byte,如果将上面的程序中的标识数组由int型改成char类型,其消耗的内存立马减少四分之三,对于对13亿中华儿女的省份证排序这样的问题,其消耗的内存由4.8G立马降到1.2G,这个改进是非常可观的,然而它仍然不能让我们满意,要知道人类的欲望是无限的。
基于位标识的排序:位排序
我们再次回到之前的引例,由于标识数组中的每个元素只需要标识其下标对应的值是否存在,因此它取值只能是两个:存在或不存在。而我们知道一个二进制位也对应了两种状态:0和1。如果我们能用一个二进制bit位来标识某个元素是否存在,那么对于13亿个数据来说,只需要13亿个比特,而13亿个bit约等于155M内存。这比使用char数组来作为标记又少耗用了八分之七的内存,并且155M内存是目前大多数PC能够承受的。我们将这种基于bit位标识的排序算法称为“位排序”或者“位图排序”,给它取个洋名:BitSort。
使用bitset来实现位排序
前面我的文章中提到过一个标准类:bitset,它是C++标准库提供的,你可以直接使用,它其实就是bit的集合,它提供许多许多接口让你能方便地对该集合中的bit进行操作(但是bitset没有迭代器,因此一般认为它不是容器)。关于bitset的更多知识,请看MSDN或者其他文档,这里我们只需要使用它的三个接口:创建bitset对象、给某个bit赋值和查询某一个bit的值。这里对这三个接口做一个简单介绍:
创建bitset对象:bitset提供了三个构造函数,我们只用最简单的一个,其形式是bitset<N> bits;它创建一个包含N个bit的bitset对象,并给每个bit初始化为0。关于另外两个构造函数请看MSDN
给某个bit赋值:set(size_tpos, bool val = true);
查询某个bit的值:bool test(size_t pos) const;
我们用bitset对之前引例中的程序进行改造后,它看起来是这样的:
#define NUMBER_RANGE 50
#define ARRAY_SIZE 10
int a[ARRAY_SIZE] ={1,13,3,42,7,23,5,37,26,10};
void sort_2(int a[],int N)//N是a中待排序元素个数
{
int i,j;
//int* p = new int[NUMBER_RANGE];
//memset(p,0,NUMBER_RANGE*sizeof(int));
bitset<NUMBER_RANGE> bits;
for (i = 0;i<N;i++)
{
//p[a[i]] = 1;
bits.set(a[i]);
}
for (i = 0,j=0;i<NUMBER_RANGE;i++)
{
if (bits.test(i)/*p[i]==1*/)
{
a[j++] = i;
}
}
}
在上面的sort_2函数中,我用bitset的相关接口取代了sort_1函数中被注释的部分,其他结构保持不变,其实现的结果跟sort_1一样,都是:
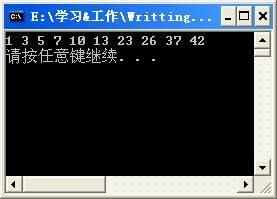
我说这个版本要优于之前的版本,原因是它吃的内存要少很多。上面程序中我定义的bitset对象bits包含50个bit(NUMBER_RANGE=50),我用cout<<sizeof(bits)测试过,其输出8,即它只吃了8byte的内存,或许你要问,8byte不是等于8*8=64bit么,这不等于50bit啊。这原因就是操作系统分配内存时以字节为单位,也就是说分配的内存必须是byte的整数倍,按照这个思路,似乎只需要7byte =56bit就够了,那为什么又是8byte呢,这又是因为标准库在实现bitset时以一个字为基本单位分配内存的(不是字节),也就是说分配的内存大小必定是4byte的整数倍。这里我们虽然浪费了十几个bit的空间,但是比起之前用int类型的数组或者char类型的数组来作为标记,这个程序节约了很多内存的(50个int数据消耗内存200byte,而50个char数据消耗内存50byte)。
使用bitset实现的位排序并不完美
上面利用bitset实现的位排序看起来十分完美,假如用它来对13亿中国人的身份证排序,它只需要消耗155M内存,比用int型数组的4.8G好许多倍。于是我兴冲冲地想要用上面那个版本的程序来完成对13亿人的身份证进行排序,然而我却吃了当头一棒。我的程序很简单,就是把上面的NUMBER_RANGE改成1300000000。当程序运行时却出现了如下异常:
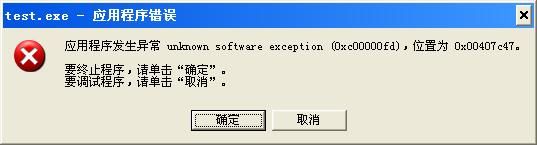
凭直觉我觉得是bitset<NUMBER_RANGE> bits;在作怪,我怀疑是由于分配内存失败而导致的,我查看了bitset的头文件发现其中申明的异常只有out_of_range,overflow_error,invalid_argument。凭直觉我觉得呢我能捕捉到overflow_error异常,然而遗憾的是我没有捕捉到,但是我可以肯定的是,当我把NUMBER_RANGE改小之后不会出现上面的异常。那么是bitset类的问题还是我的系统问题呢?我由测试了int*p= new char[1300000000/8];发现该内存分配成功,也就是说,我的系统动态地分配包含13亿个bit的数据是可以的。那出现上面的异常应该就是bitset类的问题了,但是为什么bitset无法创建一个包含bit数较多的对象,至今我没彻底弄清楚。既然bitset无法帮我们完成要对13亿人的身份证排序的功能,那么我们只好自己实现一个bitset了。
自写bitset类
接下来,我将自己实现一个类似bitset的类,当然它非常简单,它只做三件事:创建对象,给某个bit赋值和查询某个bit的状态,这个类看起来是这样的:(先代码,后说明)
#include "iostream"
using namespace std;
#define BITSPERCHAR 8 //每个字节占8bit
#define SHIFT 3 //用于移位,计算第pos个bit属于第几个字节,见set和test函数
#define MASK 0x07 //7,用于确定第pos个bit属于某个字节的第几个bit
template<unsigned N=0>
class SimpleBitSet
{
public:
SimpleBitSet()
{
bits = new char[N/BITSPERCHAR + 1];
memset(bits,0,N/BITSPERCHAR + 1);
}
SimpleBitSet<N>& set(unsigned pos,bool value = true)
{
if(value)
{
bits[pos>>SHIFT] |=(1<<(pos & MASK));
}
else
{
bits[pos>>SHIFT] &= ~(1<<(pos & MASK));
}
return *this;
}
bool test(unsigned pos)const
{
return (bits[pos>>SHIFT] & (1<<(pos & MASK))) ==0? false:true;
}
private:
char* bits;
};
说明:上面的模板类是参考了《编程珠玑》的源码而简单实现的。需要特别说明的是,私有数据成员bits数组定义成char类型的,我只所以这么做是考虑到平台移植性,因为如果定义成int的话,不同平台下可能分配的内存大小不一样,因为c/c++标准并没有规定一个int类型数据用多少bit来表示(大多数编译平台int都占32位,然后可能会是64位),但是c/c++标准规定任何平台下,char都占8位。
用自写bitset类完成排序
接下来,我用自己写的bitset类:重写sort_2函数,只需要把其中的bitset<NUMBER_RANGE>bits;改成SimpleBitSet<NUMBER_RANGE>bits;具体代码见下:
#define NUMBER_RANGE 50
#define ARRAY_SIZE 10
int a[ARRAY_SIZE] ={1,13,3,42,7,23,5,37,26,10};
void sort_3(int a[],int N) //N是a中待排序元素个数
{
int i,j;
//int* p = new int[NUMBER_RANGE];
//memset(p,0,NUMBER_RANGE*sizeof(int));
//bitset<NUMBER_RANGE> bits;
SimpleBitSet<NUMBER_RANGE> bits;
for (i = 0;i<N;i++)
{
//p[a[i]] = 1;
bits.set(a[i]);
}
for (i = 0,j=0;i<NUMBER_RANGE;i++)
{
if (bits.test(i)/*p[i]==1*/)
{
a[j++] = i;
}
}
}
分析
下表是我分别对sort_2(使用bitset)和sort_3(使用SimpleBitSet)函数进行测试的结果:
| 数据量 |
使用bitset |
使用SimpleBitSet |
| 100000 十万 |
0seconds |
0seconds |
| 1000000 百万 |
0.063seconds |
0.022seconds |
| 10000000 千万 |
0.672seconds |
0.235seconds |
| 100000000 一亿 |
异常 |
2.375seconds |
| 200000000 两亿 |
异常 |
4.797seconds |
| 300000000 三亿 |
异常 |
7.14seconds |
| 400000000 四亿 |
异常 |
9.579seconds |
通过上面的测试可以得出如下结论:
1、使用bitset和SimpleBitSet的排序的时间复杂度都为O(N),时间成线性增长
2、自己写的SimpleBitSet虽然功能简单,但是它效率比标准库的bitset类要高至少1倍!
3、自己写的SimpleBitSet能使用更大数据范围。
备注:上面的测试环境是:联想Y450,intel P7350 2.0GHz,2G内存,xp系统,Dev-C++4.9.9.0编译器。上面的测试数据不包含读写文件的时间。
总结
通过前面的描述,我们知道位排序的应用有一定的限制,首先要能确定待排序的数据范围,只有这样才知道要定义多少个bit来做标识;其次待排序数据不能有重复,因为用一个bit无法记录某个数据重复出现了多少次;最后待排序的数据尽量充满其数据范围,否则内存浪费太大(有时候可以通过数据处理来使得待排序数据聚集在某个区间内)。另外本文还得出另外一个经验:如果标准库提供的类无法满足我们的要求,那么可以自己仿造写一个,由于标准库考虑到通用性,其功能通常较多,实现较复杂,效率反而没有自己写的功能简单的类好使。