Web版RSS阅读器(二)——使用dTree树形加载rss订阅分组列表
在上一边博客《Web版RSS阅读器(一)——dom4j读取xml(opml)文件》中已经讲过如何读取rss订阅文件了。这次就把订阅的文件读取到页面上,使用树形结构进行加载显示。
| 不打算使用特殊的控件进行树型显示,也不想自己写了,想省劲些,就在 网上找了一个js树形脚本——dTree。dTree是一个易于使用的JavaScript树形 菜单控件。支持无限分级,可以在同一个页面中放置多个dTree,可以为每个 节点指定不同的图标。 主页:http://destroydrop.com/javascripts/tree/default.html 下载:http://destroydrop.com/javascripts/tree/dtree.zip 示例:http://destroydrop.com/javascripts/tree/v1/ |
|
我使用的是mvc2来实现加载rss分组列表的。mvc2的流程如下:

由于这次是使用jsp来显示,所以把rss文件夹转移到WebRoot文件夹下了。对原来的【ReadXML.java】做了部分修改,重新贴出来。
package com.tgb.rssreader.manager;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import com.tgb.rssreader.bean.RssBean;
import com.tgb.rssreader.bean.RssConfigBean;
import com.tgb.rssreader.bean.RssTeamBean;
/**
* 读取xml文件
* @author Longxuan
*
*/
public class ReadXML {
// rss分组订阅列表
private List<RssTeamBean> rssTeamBeanList = new ArrayList<RssTeamBean>();
/**
* 读取rss文件列表
* @param directory
*/
public void ReadRssTeam(String directory) {
// rss文件列表配置信息实体
RssConfigMgr rssConfigMgr = new RssConfigMgr();
List<RssConfigBean> list = rssConfigMgr.getRssConfig();
String errText = "";// 记录错误信息
// 循环读取rss文件列表
for (RssConfigBean rssConfig : list) {
// System.out.println(rssConfig.getName() + "----" +
// rssConfig.getPath());
try {
// 读取rss文件内容
//ReadRss(System.getProperty("user.dir")+ rssConfig.getPath());
ReadRss(directory + rssConfig.getPath());
} catch (Exception e) {
errText += e.getMessage();
}
}
//如果有异常信息,则汇总后抛出
if(!"".equals(errText)){
throw new RuntimeException(errText);
}
}
/**
* 读取ompl文件
*
* @param filePath
*/
private void ReadRss(String filePath) {
File file = new File(filePath);
if (!file.exists()) {
// System.out.println("找不到【" + filePath + "】文件");
// return;
throw new RuntimeException("找不到【" + filePath + "】文件");
}
try {
// 读取并解析XML文档
// SAXReader就是一个管道,用一个流的方式,把xml文件读出来
SAXReader reader = new SAXReader();
FileInputStream fis = new FileInputStream(file);
// 下面的是通过解析xml字符串的
Document doc = reader.read(fis);
// 获取根节点
Element rootElt = doc.getRootElement(); // 获取根节点
// System.out.println("根节点:" + rootElt.getName()); // 拿到根节点的名称
// 获取head/title节点
Element titleElt = (Element) rootElt.selectSingleNode("head/title");// 获取head节点下的子节点title
// 获取分组名称
String title = titleElt.getTextTrim();
// 获取body节点
Element bodyElt = (Element) rootElt.selectSingleNode("body");
// 获取body下的第一个outline节点
Element outlineElt = (Element) bodyElt.selectSingleNode("outline");
// 判断该outlineElt节点的属性数量,>2说明是详细博客订阅信息,否则则是分组信息。
if (outlineElt.attributes().size() > 2) { // 详细博客订阅信息
// 实例化 RSS分组实体
RssTeamBean rssTeamBean = new RssTeamBean();
// 获取body节点下的outline节点
Iterator<?> iter = bodyElt.elementIterator("outline");
// 输出分组名称
// System.out.println("分组名称:" + title);
// 记录分组名称
rssTeamBean.setTitle(title);
rssTeamBean.setText(title);
// 实例化订阅列表
List<RssBean> rssBeanList = new ArrayList<RssBean>();
// 获取详细博客订阅信息
ReadBlogsInfo(iter, rssBeanList);
// 设置订阅列表到分组中
rssTeamBean.setRssBeanList(rssBeanList);
// 添加分组到rss分组订阅列表
rssTeamBeanList.add(rssTeamBean);
} else { // 分组信息
// 获取body节点下的outline节点
Iterator<?> iter = bodyElt.elementIterator("outline");
while (iter.hasNext()) {
// 读取outline节点下的所有outline信息,每条信息都是一条订阅记录
Element TeamElt = (Element) iter.next();
// 实例化 RSS分组实体
RssTeamBean rssTeamBean = new RssTeamBean();
// 重新获取分组名称
title = TeamElt.attributeValue("title");
String text = TeamElt.attributeValue("text");
// System.out.println("分组title:" + title + " text:" +
// text);
// 记录分组名称和显示名称
rssTeamBean.setTitle(title);
rssTeamBean.setText(text);
// 实例化订阅列表
List<RssBean> rssBeanList = new ArrayList<RssBean>();
// 获取body节点下的outline节点
Iterator<?> iterRss = TeamElt.elementIterator("outline");
// 获取详细博客订阅信息
ReadBlogsInfo(iterRss, rssBeanList);
// 设置订阅列表到分组中
rssTeamBean.setRssBeanList(rssBeanList);
// 添加分组到rss分组订阅列表
rssTeamBeanList.add(rssTeamBean);
}
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/**
* 读取当前组博客订阅信息
*
* @param iter
* 当前节点的子节点迭代器
* @param rssBeanList
* 订阅列表
*/
private void ReadBlogsInfo(Iterator<?> iter, List<RssBean> rssBeanList) {
// 遍历所有outline节点,每个节点都是一条订阅信息
while (iter.hasNext()) {
RssBean rssBean = new RssBean();
Element outlineElt = (Element) iter.next();
String htmlUrl = outlineElt.attributeValue("htmlUrl"); // 拿到当前节点的htmlUrl属性值
String xmlUrl = outlineElt.attributeValue("xmlUrl"); // 拿到当前节点的xmlUrl属性值
String version = outlineElt.attributeValue("version"); // 拿到当前节点的version属性值
String type = outlineElt.attributeValue("type"); // 拿到当前节点的type属性值
String outlineTitle = outlineElt.attributeValue("title"); // 拿到当前节点的title属性值
String outlineText = outlineElt.attributeValue("text"); // 拿到当前节点的text属性值
rssBean.setHtmlUrl(htmlUrl);
rssBean.setXmlUrl(xmlUrl);
rssBean.setVersion(version);
rssBean.setType(type);
rssBean.setTitle(outlineTitle);
rssBean.setText(outlineText);
rssBean.setText(outlineText);
// 将每条订阅信息,存放到订阅列表中
rssBeanList.add(rssBean);
}
}
/**
* 获取Rss分组订阅列表
*
* @return
*/
public List<RssTeamBean> getRssTemBeanList() {
return rssTeamBeanList;
}
}
正题终于开始了:在src中新建包com.tgb.rssreader.web,添加RssTeamServlet,继承HttpServlet,实现doGet和doPost方法。它主要是用来调用com.tgb.rssreader.manager包下的ReadXML 类,以获取到分组信息,然后将其转发给left.jsp。源代码如下:
package com.tgb.rssreader.web;
import java.io.IOException;
import java.util.List;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import com.tgb.rssreader.bean.RssTeamBean;
import com.tgb.rssreader.manager.ReadXML;
/**
* 加载Rss分组
* @author Longxuan
*
*/
@SuppressWarnings("serial")
public class RssTeamServlet extends HttpServlet {
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
//获取web项目的根目录的实际目录
String path = this.getServletConfig().getServletContext().getRealPath("/");
ReadXML readXML = new ReadXML();
//读取目录下的rss文件夹中的所有opml文件
//将所有分组信息保存在一个List<RssTeamBean>中,
//将每个分组下的所有订阅信息,保存在该RssTeamBean中的一个List<RssBean>中
readXML.ReadRssTeam(path);
//获取装有所有分组信息的列表
List<RssTeamBean> rssTemBeanList = readXML.getRssTemBeanList();
//将所有分组信息保存在request的属性rssTemBeanList中
request.setAttribute("rssTemBeanList", rssTemBeanList);
//转发request
request.getRequestDispatcher("/left.jsp").forward(request, response);
}
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doPost(request, response);
}
}
最后一步就是在界面上动工了。界面是自己先简单的做了个html的模版,已上传至百度网盘。布局使用frameset分割成3列,树形结构的Rss分组信息左侧,即left.jsp。中间的为某个rss订阅地址的文章列表,名为middle.jsp,右侧则是显示文章的地方,名为content.jsp。
现在先做成这样一个效果:左侧的left.jsp页,使用dTree的树形结构加载rss分组信息。点击一个订阅信息节点,在右侧显示出来对应的订阅内容。修改的是left.jsp,贴出源码:
<%@ page language="java" contentType="text/html; charset=GB18030"
pageEncoding="GB18030"%>
<%@ page import="com.tgb.rssreader.bean.*" %>
<%@ page import="java.util.*" %>
<%
String path = request.getContextPath();
String basePath = request.getScheme() + "://" + request.getServerName() + ":" + request.getServerPort()+path+"/";
%>
<html>
<head>
<base href="<%=basePath %>" />
<link rel="stylesheet" href="style/main.css">
<link rel="StyleSheet" href="style/dtree.css" type="text/css" />
<script type="text/javascript" src="js/dtree.js"></script>
</head>
<body>
<div id="leftMenu" style="overflow-y:auto; overflow-x:auto;">
<script type="text/javascript">
<!--
<!-- add(id, pid, name, url, title, target, icon, iconOpen, open);
//9个参数说明: id,pid,显示名称,打开的url,提示信息,目标框架,闭合时的图标,展开时的图标,是否展开(open || false)
-->
d = new dTree('d');
d.add(0,-1,'博客分组','','','','','img/blog.png');
<%
int i = 0;//当前分组的节点索引值
int c = 0;//节点总数
//获取所有分组信息
List<RssTeamBean> rssTemBeanList = (List)request.getAttribute("rssTemBeanList");
//遍历所有分组信息
for (RssTeamBean rssTeamBean:rssTemBeanList) {
c = c+1;//总个数加1
%>
//添加组节点
d.add(<%=c%>,0,'<%=rssTeamBean.getTitle()%>','','','','img/open.png','img/close.png');
<%
i=c;//设定当前节点为分组节点索引值
//遍历分组下的所有订阅信息
for (RssBean rssBean : rssTeamBean.getRssBeanList()) {
c = c+1;//总个数加1
%>
//添加订阅信息节点
d.add(<%=c%>,<%=i%>,'<%=rssBean.getTitle()%>','<%=rssBean.getXmlUrl()%>','<%=rssBean.getText()%>','contenthtml');
<%
}
}
%>
//在界面上显示树形结构
document.write(d);
//-->
</script>
</div>
</body>
</html>
暂时的效果图如下:
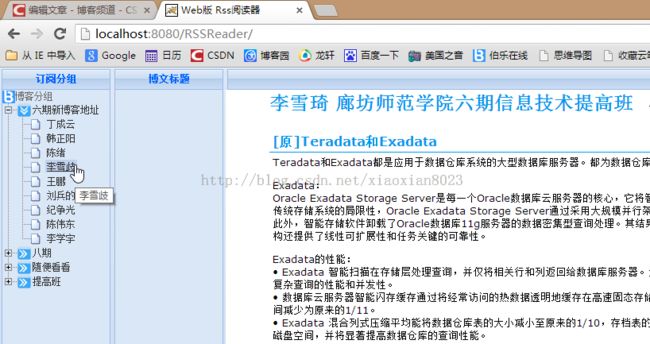
至此,读取rss分组已经完成了。接下来的博文中,会给大家解说一下rss版本以及解析在线的rss订阅。敬请期待。