CRC32算法冲突概率测试和分析
最近因为某个业务需要用到CRC32算法,但业务又不能容忍重复的数值出现,于是自然就想了解一下CRC32算法的冲突概率(或者叫碰撞概率)。
本以为这种问题应该很多人分析过,结果找来找去就只看到一大堆数学公式,我这种数学盲完全看不懂。
好不容易找到一张图,但看得云里雾里(原图链接:http://preshing.com/20110504/hash-collision-probabilities/ ):
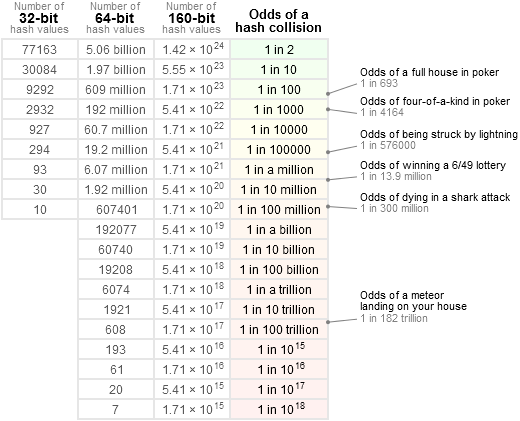
既然网上的不靠谱,那就自己来验证吧,写个php脚本很简单,我的第1次验证模型是这样的:
取1个整型值作为初始值,然后递增1000W次,每次计算crc32的值,输出到文件,再使用sort crc32.result | uniq -c -d > crc32-collision.txt 来输出冲突的结果
结果出来,我大吃一惊:1000W没有1个冲突!大大出乎意料,于是尝试2000W,还是没有冲突!! 于是尝试 1亿,这回有冲突了,冲突数大约是240W个!!
虽然我没有看懂crc32算法的原理,但隐约觉得这个冲突率不符合实际,于是继续寻找,终于功夫不负有心人,找到一个详细和完整的测试报告(http://www.backplane.com/matt/crc64.html):
CRC16 - CRC64 test results on 18.2M dataset
结果摘要如下:
Summary, 18.2 million sample test dataset, number of collisions. output.16 Count 18134464/18200000 output.17 Count 18068928/18200000 output.18 Count 17937856/18200000 output.19 Count 17675712/18200000 output.20 Count 17151424/18200000 output.21 Count 16103198/18200000 output.22 Count 14061250/18200000 output.23 Count 10770169/18200000 output.24 Count 7092360/18200000 output.25 Count 4153742/18200000 output.26 Count 2259269/18200000 output.27 Count 1179721/18200000 output.28 Count 603421/18200000 output.29 Count 305089/18200000 output.30 Count 153722/18200000 output.31 Count 77254/18200000 output.32 Count 38638/18200000 output.33 Count 19232/18200000 output.34 Count 9652/18200000 output.35 Count 4914/18200000 output.36 Count 2343/18200000 output.37 Count 1204/18200000 output.38 Count 637/18200000 output.39 Count 302/18200000 output.40 Count 152/18200000 output.41 Count 75/18200000 output.42 Count 52/18200000 output.43 Count 21/18200000 output.44 Count 13/18200000 output.45 Count 7/18200000 output.46 Count 1/18200000 (below noise floor) output.47 Count 1/18200000 (below noise floor) output.48 Count 1/18200000 (below noise floor) output.49 Count 0/18200000 (below noise floor) output.50 Count 0/18200000 (... all remaining entries below noise output.51 Count 0/18200000 floor) output.52 Count 0/18200000 output.53 Count 0/18200000 output.54 Count 0/18200000 output.55 Count 0/18200000 output.56 Count 0/18200000 output.57 Count 0/18200000 output.58 Count 0/18200000 output.59 Count 0/18200000 output.60 Count 0/18200000 output.61 Count 0/18200000 output.62 Count 0/18200000 output.63 Count 0/18200000 output.64 Count 0/18200000
这个测试报告非常详细,基本上解决了我们的疑问,从这个报告可以看到,1820W数据,冲突数量是38638个,这个比较符合我的理解和预期。
但问题还是没有解决:为什么我的测试结果那么好?
由于CRC32算法是通用的,因此也就不存在不同语言实现机制不同的问题,于是我把目光转向了测试模型,问题果然在这里。
我的测试模型:crc32(i++),这个计算模型输入进去的原值只是某个范围内连续的数据,并不是完全随机的.
于是我稍微修改一下:crc32(md5(i++)),这样就保证输入的原值是完全随机的。
重新测试,结果出来了,和上面那个完整测试报告的结果完全一样!!
归纳总结一下:
1)CRC32在完全随机的输入情况下,冲突概率还是比较高的,特别是到了1亿的数据量后,冲突概率会更高
2)CRC32在输入某个连续段的数据情况下,冲突概率反而很低,这是因为两个冲突的原值理论上应该是相隔很远,只输入某段数据的情况下,这个段里面冲突的原值会很少
转载请注明出处:http://blog.csdn.net/yunhua_lee/article/details/42775039