linux-系统监控命令
http://blog.jobbole.com/15430/
1,监控进程
1.1 命令top:动态查看进程情况【常用】
top 命令显示当前的活动进程,默认它是按消耗 CPU 的厉害程度进行排序,每5秒钟刷新一次列表,你也可以选择不同的排序方式,例如 m 是按内存占用方式进行排序的快捷键。
top - 11:09:36 up 349 days, 18:42, 12 users, load average: 0.07, 0.11, 0.21
Tasks: 166 total, 1 running, 165 sleeping, 0 stopped, 0 zombie
Cpu(s): 1.2%us, 0.4%sy, 0.0%ni, 97.9%id, 0.2%wa, 0.0%hi, 0.3%si, 0.0%st
Mem: 32947976k total, 32649576k used, 298400k free, 483656k buffers
Swap: 2104504k total, 1349936k used, 754568k free, 24875996k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 16 0 784 72 40 S 0 0.0 0:31.68 init
2 root RT 0 0 0 0 S 0 0.0 0:36.92 migration/0
3 root 34 19 0 0 0 S 0 0.0 0:00.92 ksoftirqd/0
4 root RT 0 0 0 0 S 0 0.0 0:39.63 migration/1
1.1.1 top命令显示各列的含义
1,top 界面分为两个部分,光标上面部份显示关于系统整体性能,光标下面部份显示各进程信息。光标所在处是用来输入操作命令的。
2,统计信息区前五行是系统整体的统计信息。
第一行是任务队列信息,同 uptime 命令的执行结果。
| 11:09:36 | 当前时间 |
| up 349 days | 系统运行时间,格式为时:分 |
| 12 users | 当前登录用户数 |
| load average: 0.07, 0.11, 0.21 | 系统负载,即任务队列的平均长度。 三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。 load avarage <3 系统良好,大于5 则有严重的性能问题。 注意,这个值还应当除以CPU数目。 |
| 166 total | 进程总数 |
| 1 running | 正在运行的进程数 |
| 165 sleeping | 睡眠的进程数 |
| 0 stopped | 停止的进程数 |
| 0 zombie | 僵尸进程数 |
第三行为CPU信息。当有多个CPU时,这些内容可能会超过两行。
| 1.2%us | 用户空间占用CPU百分比 |
| 0.4%sy | 内核空间占用CPU百分比 |
| 0.0%ni | 用户进程空间内改变过优先级的进程占用CPU百分比 |
| 97.9%id | 空闲CPU百分比 |
| 0.2%wa | 等待I/O的CPU时间百分比 |
| 0.0%hi | CPU硬中断时间百分比 |
| 0.3%si | CPU软中断时间百分比 |
| 0.0%st |
| 32947976k total | 物理内存总量 |
| 32649576k used | 使用的物理内存总量 |
| 298400k free | 空闲内存总量 |
| 483656k buffers | 用作内核缓存的内存量 |
| 2104504k total | 交换区总量 |
| 1349936k used | 使用的交换区总量 |
| 754568k free | 空闲交换区总量 |
| 24875996k cached | 缓冲的交换区总量 |
3,进程信息区
| 序号 | 列名 | 含义 |
| a | PID | 进程id |
| b | PPID | 父进程id |
| c | RUSER | Real user name |
| d | UID | 进程所有者的用户id |
| e | USER | 进程所有者的用户名 |
| f | GROUP | 进程所有者的组名 |
| g | TTY | 启动进程的终端名。不是从终端启动的进程则显示为 ? |
| h | PR | 优先级 |
| i | NI | nice值。负值表示高优先级,正值表示低优先级 |
| j | P | 最后使用的CPU,仅在多CPU环境下有意义 |
| k | %CPU | 上次更新到现在的CPU时间占用百分比 |
| l | TIME | 进程使用的CPU时间总计,单位秒 |
| m | TIME+ | 进程使用的CPU时间总计,单位1/100秒 |
| n | %MEM | 进程使用的物理内存百分比 |
| o | VIRT | 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES |
| p | SWAP | 程使用的虚拟内存中,被换出的大小,单位kb。 |
| q | RES | 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA |
| r | CODE | 可执行代码占用的物理内存大小,单位kb |
| s | DATA | 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb |
| t | SHR | 共享内存大小,单位kb |
| u | nFLT | 页面错误次数 |
| v | nDRT | 最后一次写入到现在,被修改过的页面数。 |
| w | S | 进程状态: D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程 |
| x | COMMAND | 命令名/命令行 |
| y | WCHAN | 若该进程在睡眠,则显示睡眠中的系统函数名 |
| z | Flags | 任务标志,参考 sched.h |
1.1.2 常用命令格式
#通过指定监控进程ID来仅仅监控某个进程的状态 top -p pid #显示整个命令行而不只是显示命令名 top -c #设置为5秒刷新一次(默认) top -d 5
1.1.3 二次命令格式
k :终止一个进程。系统将提示用户输入需要终止的进程PID,以及需要发送给该进程什么样的信号。一般的终止进程可以使用15信号;如果不能正常结束那就使用信号9强制结束该进程。默认值是信号15。在安全模式中此命令被屏蔽。
i:忽略闲置和僵死进程。这是一个开关式命令。
q: 退出程序。
r: renice重新安排一个进程的优先级别。系统提示用户输入需要改变的进程PID以及需要设置的进程优先级值。输入一个正值将使优先级降低,反之则可以使该进程拥有更高的优先权。默认值是10。
S:切换到累计模式。
s : 改变两次刷新之间的延迟时间。系统将提示用户输入新的时间,单位为s。如果有小数,就换算成ms。输入0值则系统将不断刷新,默认值是5 s。需要注意的是如果设置太小的时间,很可能会引起不断刷新,从而根本来不及看清显示的情况,而且系统负载也会大大增加。
f或者F :从当前显示中添加或者删除项目。
o或者O :改变显示项目的顺序。
l: 切换显示平均负载和启动时间信息。即显示隐藏第一行
m: 切换显示内存信息。即显示影藏内存行
t :切换显示进程和CPU状态信息。即显示影藏CPU行
c:切换显示命令名称和完整命令行。 显示完整的命令。 这个功能很有用。
M : 根据驻留内存大小进行排序。
P:根据CPU使用百分比大小进行排序(默认)。
T: 根据时间/累计时间进行排序。
W: 将当前设置写入~/.toprc文件中。这是写top配置文件的推荐方法。
1.2 命令sar:系统监控
1.2.1 命令格式
sar [options] [-A] [-o file] t [n]options 为命令行选项:
-A:所有报告的总和。
-u:CPU利用率
-v:进程、I节点、文件和锁表状态。
-d:硬盘使用报告。
-r:没有使用的内存页面和硬盘块。
-g:串口I/O的情况。
-b:缓冲区使用情况。
-a:文件读写情况。
-c:系统调用情况。
-R:进程的活动情况。
-y:终端设备活动情况。
-w:系统交换活动。
1.2.1 命令实例
#sar -u -o filename 1 5 Linux 2.6.16.60-0.21-xxx64-110923 (xxx64) 06/26/2013 10:30:28 AM CPU %user %nice %system %iowait %idle 10:30:29 AM all 0.75 0.00 0.25 0.00 99.00 10:30:30 AM all 0.00 0.00 0.00 0.00 100.00 10:30:31 AM all 0.00 0.00 0.00 0.00 100.00 10:30:32 AM all 0.25 0.00 0.00 0.00 99.75 10:30:33 AM all 0.00 0.00 0.00 0.00 100.00 Average: all 0.20 0.00 0.05 0.00 99.751 结构说明:
%sys:CPU处在系统模式下的时间百分比。
%wio:CPU等待输入输出完成时间的百分比。
%idle:CPU空闲时间百分比。
1 结果分析:
#sar -v 1 5 Linux 2.6.16.60-0.21-xxx64-110923 (xxx64) 06/26/2013 10:36:03 AM dentunusd file-sz inode-sz super-sz %super-sz dquot-sz %dquot-sz rtsig-sz %rtsig-sz 10:36:04 AM 2451803 3072 2642237 0 0.00 0 0.00 0 0.00 10:36:05 AM 2451803 3072 2642237 0 0.00 0 0.00 0 0.00 10:36:06 AM 2451803 3072 2642237 0 0.00 0 0.00 0 0.00 10:36:07 AM 2451803 3072 2642237 0 0.00 0 0.00 0 0.00 10:36:08 AM 2451803 3072 2642237 0 0.00 0 0.00 0 0.00 Average: 2451803 3072 2642237 0 0.00 0 0.00 0 0.002 结构说明:
inod-sz:目前核心中正在使用或分配的i节点表的表项数,由核心参数MAX-INODE控制。
file-sz: 目前核心中正在使用或分配的文件表的表项数,由核心参数MAX-FILE控制。
ov:溢出出现的次数。
Lock-sz:目前核心中正在使用或分配的记录加锁的表项数,由核心参数MAX-FLCKRE控制。
#sar -d 1 5 Linux 2.6.16.60-0.21-xxx64-110923 (xxx64) 06/26/2013 10:39:08 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util 10:39:09 AM dev8-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 10:39:09 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util 10:39:10 AM dev8-0 1.00 96.00 0.00 96.00 0.01 12.00 12.00 1.20 10:39:10 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util 10:39:11 AM dev8-0 200.00 887.13 1695.05 12.91 0.25 1.27 1.09 21.78 10:39:11 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util 10:39:12 AM dev8-0 55.45 1647.52 198.02 33.29 0.40 7.29 5.07 28.12 10:39:12 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util 10:39:13 AM dev8-0 12.00 0.00 224.00 18.67 0.00 0.00 0.00 0.00 Average: DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util Average: dev8-0 53.98 529.08 425.50 17.68 0.13 2.49 1.90 10.283 结构说明
%busy: 设备忙时,传送请求所占时间的百分比。
avque: 队列站满时,未完成请求数量的平均值。
r+w/s: 每秒传送到设备或从设备传出的数据量。
blks/s: 每秒传送的块数,每块512字节。
avwait: 队列占满时传送请求等待队列空闲的平均时间。
avserv: 完成传送请求所需平均时间(毫秒)。
在显示的内容中,wd-0是硬盘的名字,%busy的值比较小,说明用于处理传送请求的有效时间太少,文件系统效率不高,一般来讲,%busy值高些,avque值低些,文件系统的效率比较高,如果%busy和avque值相对比较高,说明硬盘传输速度太慢,需调整。
#sar -b 1 5 Linux 2.6.16.60-0.21-xxx64-110923 (xxx64) 06/26/2013 10:41:30 AM tps rtps wtps bread/s bwrtn/s 10:41:31 AM 126.73 0.00 126.73 0.00 1164.36 10:41:32 AM 0.00 0.00 0.00 0.00 0.00 10:41:33 AM 17.00 0.00 17.00 0.00 216.00 10:41:34 AM 16.83 0.00 16.83 0.00 300.99 10:41:35 AM 12.00 0.00 12.00 0.00 312.00 Average: 34.66 0.00 34.66 0.00 400.004 结构说明
lread/s: 平均每秒从系统buffer读出的逻辑块数。
%rcache: 在buffer cache中进行逻辑读的百分比。
bwrit/s: 平均每秒从系统buffer向磁盘所写的物理块数。
lwrit/s: 平均每秒写到系统buffer逻辑块数。
%wcache: 在buffer cache中进行逻辑读的百分比。
pread/s: 平均每秒请求物理读的次数。
pwrit/s: 平均每秒请求物理写的次数。
在 显示的内容中,最重要的是%cache和%wcache两列,它们的值体现着buffer的使用效率,%rcache的值小于90或者%wcache的值 低于65,应适当增加系统buffer的数量,buffer数量由核心参数NBUF控制,使%rcache达到90左右,%wcache达到80左右。但 buffer参数值的多少影响I/O效率,增加buffer,应在较大内存的情况下,否则系统效率反而得不到提高。
1.3 命令uptime:系统启动时间与工作负载【不用】
top的最上一行
1.4 命令mpstat:检测多CPU实时信息【不用】
读取文件/proc/stat
mpstat是MultiProcessor Statistics的缩写,是实时系统监控工具,在多CPUs系统里,其不但能查看所有CPU的平均状况信息,而且能够查看特定CPU的信息。
#mpstat -P ALL Linux 2.6.16.60-0.21-xxx64-110923 (xxx) 06/25/2013 05:17:44 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s 05:17:44 PM all 1.18 0.01 0.35 0.20 0.05 0.28 0.00 97.94 319.17 05:17:44 PM 0 1.61 0.00 0.58 0.06 0.19 1.07 0.00 96.48 110.95 05:17:44 PM 1 1.13 0.01 0.30 0.48 0.00 0.02 0.00 98.05 74.08 05:17:44 PM 2 0.89 0.00 0.25 0.04 0.00 0.01 0.00 98.80 65.51 05:17:44 PM 3 1.08 0.01 0.28 0.22 0.00 0.01 0.00 98.41 68.63
1.5 命令ps:进程管理
1.5.1 三种常用范式
#ps -l查阅所有运行进程命令:
#ps aux 或者 #ps -ef
1.5.2 “ps aux” 说明
“ps -ef”比“ps aux”多一项PPID$ps aux |more USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.0 0.0 10348 624 ? Ss Apr29 0:22 init [3] root 2 0.0 0.0 0 0 ? S< Apr29 0:40 [migration/0] root 3 0.0 0.0 0 0 ? SN Apr29 0:25 [ksoftirqd/0] root 4 0.0 0.0 0 0 ? S< Apr29 0:00 [watchdog/0] root 5 0.0 0.0 0 0 ? S< Apr29 0:12 [migration/1] root 6 0.0 0.0 0 0 ? SN Apr29 0:18 [ksoftirqd/1] root 7 0.0 0.0 0 0 ? S< Apr29 0:00 [watchdog/1] root 8 0.0 0.0 0 0 ? S< Apr29 0:10 [migration/2] root 9 0.0 0.0 0 0 ? SN Apr29 0:16 [ksoftirqd/2] root 10 0.0 0.0 0 0 ? S< Apr29 0:00 [watchdog/2]上述解释如下:
USER 用户名 PID 进程ID(Process ID) PPID 父进程的进程ID(Parent Process id) %CPU 进程的cpu占用率 %MEM 进程的内存占用率 VSZ 进程所使用的虚存的大小(Virtual Size) RSS 进程使用的驻留集大小或者是实际内存的大小,Kbytes字节 TTY 与进程关联的终端(tty),若与终端无关,则显示(?),否则显示类似(pts/0)等 STAT 进程的状态:进程状态使用字符表示的(STAT的状态码) START 进程启动时间和日期 TIME 进程使用的总cpu时间 COMMAND 正在执行的命令行命令STAT狀態位常見的狀態字符
D (Uninterruptible sleep)无法中断的休眠状态(通常 IO 的进程); R (Runnable)正在运行或在运行队列中等待 S (Sleeping)休眠中, 受阻, 在等待某个条件的形成或接受到信号 T (Terminate)停止或被追踪; W 进入内存交换 (从内核2.6开始无效); X 死掉的进程 (基本很少見); Z (Zombie)僵尸进程; < 优先级高的进程 N 优先级较低的进程 L 有些页被锁进内存; s 进程的领导者(在它之下有子进程); l 多进程的(使用 CLONE_THREAD, 类似 NPTL pthreads); + 位于后台的进程组;
1.5.3 未知执行命令时:pgrep
$ pgrep chrome 32575 32580 ...
或使用pstree查看
$ pstree -p | grep chrome
|-chrome-sandbox(32582)---chrome(32583)-+-chrome(32622)-+-{chrome}(32625)
| | |-{chrome}(32627)
...
1.5.4 已知执行命令时:ps
2.1 直接查找命令:
【已知:跑了以python2.7开头的很多命令】
ps -ef | grep python2.7
$ps -ef | grep python2.7 admin 18535 18484 0 14:22 pts/9 00:00:00 python2.7 tester.py sql_case/ plan run admin 18536 18484 0 14:22 pts/9 00:00:00 python2.7 tester.py sql_case/ plan run admin 18537 18484 0 14:22 pts/9 00:00:00 python2.7 tester.py sql_case/ plan run admin 18538 18484 0 14:22 pts/9 00:00:00 python2.7 tester.py sql_case/ plan run admin 18539 18484 0 14:22 pts/9 00:00:00 python2.7 tester.py sql_case/ plan run admin 19218 8361 0 14:24 pts/0 00:00:00 grep python2.72.2 过滤命令:
ps -ef | grep python2.7 | grep -v grep | grep tester.py
$ps -ef | grep python2.7|grep tester.py admin 18535 18484 0 14:22 pts/9 00:00:00 python2.7 tester.py sql_case/ plan run admin 18536 18484 0 14:22 pts/9 00:00:00 python2.7 tester.py sql_case/ plan run admin 18537 18484 0 14:22 pts/9 00:00:00 python2.7 tester.py sql_case/ plan run admin 18538 18484 0 14:22 pts/9 00:00:00 python2.7 tester.py sql_case/ plan run admin 18539 18484 0 14:22 pts/9 00:00:00 python2.7 tester.py sql_case/ plan run
2.3 打印进程号:
ps -ef | grep python2.7| grep -v grep | grep tester.py | awk'{print $2}'
$ps -ef | grep python2.7|grep tester.py | awk '{print $2}'
18535
18536
18537
18538
18539
ps -ef | grep python2.7| grep -v grep | grep tester.py | awk'{print $2}' | wc -l
$ps -ef | grep python2.7|grep tester.py | awk '{print $2}'| wc -l
5
2.4 杀死进程
ps -ef | grep python2.7| grep -v grep | grep tester.py | awk'{print $2}' | xargs kill -9
$ps -ef | grep python2.7|grep tester.py | awk '{print $2}'| xargs kill -9
【另,如果确认之生成了进程python2.7 balabala】
亦可以killall python2.7
1.5.5 杀死进程:kill_killall
强制杀掉父进程
$ kill -9 32582或者删除与之相关所有进程
$ killall chrome
1.6 命令pstree:打印进程树
以树状图显示进程,只显示进程的名字,且相同进程合并显示。
#pstree
以树状图显示进程,还显示进程PID。
#pstree -p
以树状图显示进程PID为<pid>的进程以及子孙进程,如果有-p参数则同时显示每个进程的PID。
#pstree 2701
sshd-+-sshd---bash---update_and_rest---cvs
|-sshd---bash---pstree
`-sshd---bash
#pstree -p 2701
sshd(2701)-+-sshd(6745)---bash(6749)---update_and_rest(14193)---cvs(14194)
|-sshd(12626)---bash(12630)---pstree(15588)
`-sshd(13324)---bash(13328)
1.7 命令uname:内核相关信息【简略】
#uname -a读取文件/proc/version
2,监控内存
2.1 命令vmstat:监控虚拟内存【常用】
#vmstat 5 procs -----------memory---------- ---swap-- -----io---- -system-- -----cpu------ r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 1545696 230416 3392220 21564928 0 1 12 68 0 0 1 1 98 0 0 1 0 1545696 226860 3392244 21564904 0 0 2 1540 338 6142 18 8 74 0 0 2 0 1545696 217804 3392280 21564868 0 0 76 210 294 6198 26 8 66 0 0 2 0 1545692 215816 3392308 21564844 0 0 2 243 283 5980 43 7 50 0 0 2 0 1545692 215384 3392340 21565840 0 0 2 200 295 6063 42 8 50 0 0(1)进程procs:
r:在运行队列中等待的进程数,【这个值也可以判断是否需要增加CPU(长期大于1)】
b:在等待io的进程数 。
(2)Linux 内存监控内存memoy:
swpd:现时可用的交换内存(单位KB)。【如果 swpd 的值不为0,或者还比较大,比如超过100M了,但是 si, so 的值长期为 0,这种情况我们可以不用担心,不会影响系统性能。 】
free:空闲的内存(单位KB)。
buff: 作为buffer cache的内存,对块设备的读写进行缓冲(单位:KB)。
cache:作为page cache的内存, 文件系统的cache(单位:KB)。【如果 cache 的值大的时候,说明cache住的文件数多,如果频繁访问到的文件都能被cache住,那么磁盘的读IO bi 会非常小。】
(3) Linux 内存监控swap交换页面
si: 从磁盘交换到内存的交换页数量,单位:KB/秒。【内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响。磁盘IO和CPU资源都会被消耗。】
so: 从内存交换到磁盘的交换页数量,单位:KB/秒。【常有人看到空闲内存(free)很少或接近于0时,就认为内存不够用了,实际上不能光看这一点的,还要结合si,so,如果free很少,但是si,so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。】
(4) Linux 内存监控 io块设备:
bi: 发送到块设备的块数,单位:KB/秒。【随机磁盘读写的时候,这2个 值越大(如超出1M),能看到CPU在IO等待的值也会越大】
bo: 从块设备接收到的块数,单位:KB/秒。
(5)Linux 内存监控system系统:
in: 每秒的中断数,包括时钟中断。【上面这2个值越大,会看到由内核消耗的CPU时间会越多】
cs: 每秒的环境(上下文)转换次数。
(6)Linux 内存监控cpu中央处理器:
cs: 。以百分比表示。
sy:系统内核消耗的CPU时间百分比【sy 的值高时,说明系统内核消耗的CPU资源多,这并不是良性的表现,我们应该检查原因。】
id:中央处理器的空闲时间 。以百分比表示。
2.3 命令free:内存使用情况【常用】
#free -m -s 5 #m表示以MB为单位显示(默认是KB)s表示间隔时间 这里为5秒显示一次
total used free shared buffers cached
Mem: 32175 31825 350 0 3362 20984
-/+ buffers/cache: 7479 24696
Swap: 2055 1509 545
第一行:【对操作系统来讲是buffers/cached 都是属于被使用】
Mem一行和top命令的Mem结果是一致的。且total(32175)=used(31825) + free(350)
第二行:【对应用程序来讲是buffers/cached 是等于可用的,因为buffer/cached是为了提高文件读取的性能,当应用程序需在用到内存的时候,buffer/cached会很快地被回收。所以从应用程序的角度来说,可用内存=系统free memory+buffers+cached.】
-/+ buffers/cache的意思相当于:
-buffers/cache 的计算后的used的内存数:used(31825) - buffers(3362) - cached(20984) = 7479
+buffers/cache 的计算后的free的内存数:free(350) + buffers(3362) + cached(20984) = 24696
buffers: 内存,指用来给块设备IO做的缓冲大小,减少实际IO次数
cache: 内存,是用来给文件做缓冲
swap: 磁盘空间,用来将内存中暂时不用的数据交换到磁盘,实现虚拟内存(缺页中断)
4,监控磁盘IO
4.1 命令iostat:监控磁盘IO【常用】
iostat 命令用来显示存储子系统的详细信息,通常用它来监控磁盘 I/O 的情况。要特别注意 iostat 统计结果中的 %iowait 值,太大了表明你的系统存储子系统性能低下。
#iostat -x 1 10 Linux 2.6.18-238.el5 (study) 08/09/11 Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn sda 11.55 423.43 29.12 329833 22686 sda1 0.11 1.24 0.00 968 2 sda2 11.41 421.92 29.12 328657 22684
参数 -x表示显示详细信息;1 10表示,数据显示每隔1秒刷新一次,共显示10次。
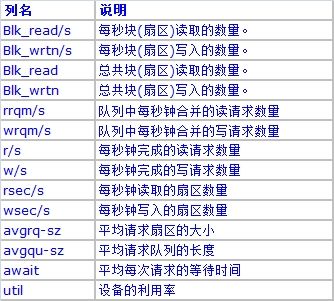
4.2 命令lsof:列出某个进程打开的所有文件信息【常用】
1、不带任何参数运行lsof会列出所有进程打开的所有文件。(lsof -h 查看参数) 2、列出哪些进程使用某些文件 lsof /usr/xxx/1.log 3、 递归查找某个目录中所有打开的文件 lsof +D /usr/xxx/logs 等价于: lsof | grep '/usr/xxx/logs' 4、查找某个程序打开的所有文件 lsof -c httpd; 可逗号分隔多个进程名称,如lsof -c httpd,smbd 5、 列出某个用户打开的所有文件 lsof -u root 列出根用户使用的文件 lsof -u root -c httpd 列出根用户运行的或者apache进程使用的所有文件 lsof -a -u root -c httpd 列出根用户运行的且apache进程使用的文件 6、 列出所有由某个PID对应的进程打开的文件 lsof -p PID 7、列出系统中开放端口及运行在端口上的服务的详细信息 lsof -i 列出所有打开了网络套接字(TCP和UDP)的进程 lsof -i tcp 列出所有TCP网络连接 lsof -i :port 使用某个端口的进程 8、列出所有与某个描述符关联的文件 lsof -d 2 列出所有以描述符2打开的文件 lsof -d 0-2 列出所有描述符为0,1,2的文件 lsof -d mem 列出所有内存映射文件 lsof -d txt 列出所有加载在内存中并正在执行的进程 9、分析lsof -i 命令运行输出结果 lsof 的每一项输出都对应着一个打开了特定端口的服务,输出的最后一列,如:tcp ip:port1->ip2:port (ESTABLISHED) ip1:port 对应本地机器和开放的端口,ip2:port 对应远程机器和开放的端口; 若要列出本机当前开放的端口,可使用: lsof -i | grep ":[0-9]\+->" -o | grep "[0-9]\+" -o | sort | uniq 注:root用户运行lsof命令
恢复删除的文件
当系统中的某个文件被意外地删除了,只要这个时候系统中还有进程正在访问该文件,那么我们就可以通过lsof从/proc目录下恢复该文件的内容。
假如由于误操作将/var/log/messages文件删除掉了,那么这时要将/var/log/messages文件恢复的方法如下:
1,使用lsof来查看当前是否有进程打开/var/logmessages文件,如下: # lsof /var/log/messages syslogd 1283 root 2w REG 3,3 5381017 1773647 /var/log/messages (deleted) 从上面的信息可以看到 PID 1283(syslogd)打开文件的文件描述符为 2。同时还可以看到/var/log/messages已经标记被删除了。 2,在 /proc/1283/fd/2 (fd下的每个以数字命名的文件表示进程对应的文件描述符)中查看相应的信息,如下: # head -n 10 /proc/1283/fd/2 xxxx 3,恢复数据如果可以通过文件描述符查看相应的数据,那么就可以使用 I/O 重定向将其复制到文件中,如: cat /proc/1283/fd/2 > /var/log/messages 对于许多应用程序,尤其是日志文件和数据库,这种恢复删除文件的方法非常有用。
5,监控网络
5.1 netstat:查看端口占用【常用】
-t (tcp)仅显示tcp相关选项
-u (udp)仅显示udp相关选项
-n 拒绝显示别名,能显示数字的全部转化成数字。
-l 仅列出有在 Listen (监听) 的服務状态
-p 显示建立相关链接的程序名
-r 显示路由信息,路由表
-e 显示扩展信息,例如uid等
-s 按各个协议进行统计
-c 每隔一个固定时间,执行该netstat命令。
提示:LISTEN和LISTENING的状态只有用-a或者-l才能看到
列出所有端口 (包括监听和未监听的) netstat -a 列出所有 tcp 端口 netstat -at 列出所有 udp 端口 netstat -au 只显示监听端口 netstat -l 只列出所有监听 tcp 端口 netstat -lt 只列出所有监听 udp 端口 netstat -lu 只列出所有监听 UNIX 端口 netstat -lx
常用场景:
$netstat -nltp | grep httpd (Not all processes could be identified, non-owned process info will not be shown, you would have to be root to see it all.) tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTEN 6560/httpd tcp 0 0 0.0.0.0:61085 0.0.0.0:* LISTEN 6613/httpd $netstat -nltp | grep ":8080" (Not all processes could be identified, non-owned process info will not be shown, you would have to be root to see it all.) tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTEN 6560/httpd $ps aux | grep -v grep | grep 6560 admin 6560 0.0 0.0 101468 2864 ? S 12:44 0:00 /apsara/apache/bin/httpd -k restart
5.2 nslookup:查看dns??
nslookup root_server_ip_addresstcpdump
5.3 命令tcpdump:网络抓包分析工具??
1)监听指定网卡(-i $interface) tcpdump -i eth1 注:如果没有权限,则加上sudo sudo tcpdump -i eth1 2)监听指定端口(加port xxx) sudo tcpdump -i eth1 port 12345 3)监听指定端口的TCP请求(加tcp) sudo tcpdump -i eth1 tcp port 12345 还可以监听其他协议,如ip,ip6,arp,tcp,udp等 4)监听指定IP(加host xxx.xxx.xx.xxx) sudo tcpdump -i eth1 host 10.10.10.106 可以指定是源地址和目的地址src/dst sudo tcpdump -i eth1 src host 10.10.10.106 sudo tcpdump -i eth1 dst host 10.10.10.106 如果要同时监听IP和端口,则要用and关键字 sudo tcpdump -i eth1 host 10.10.10.106 and port 80 5)展示详细信息(加-v -vv -vvv) sudo tcpdump -i eth1 -v tcp port 12345 6)将请求信息保存到文件(加-w filename) sudo tcpdump -w 20131218.pcap -i eth1 -v tcp port 12345 7)捉包时打印包数据到屏幕上(加-X) sudo tcpdump -X -i eth1 -v tcp port 12345 8)指定捉包数据的长度(加-s $num) sudo tcpdump -X -s 1024 -i eth1 -v tcp port 12345 (如果不指定,则会捉默认的96字节,太小了) 将长度加大后,可以展示更详细的数据 9)以ASCII方式显示数据包(加-A)方便查看数据 sudo tcpdump -A -X -s 1024 -i eth1 -v tcp port 80 (不过大部分服务器都gzip了,不一定能捉到明文数据) 10)捉取指定数量的包(加-c $num) sudo tcpdump -A -X -s 1024 -i eth1 -v tcp -c 10 port 80
6 监控IPC(进程间通信)
6.1 命令ipcs:查看ipc status
取得ipc信息:
ipcs [-m|-q|-s] -m 输出有关共享内存(shared memory)的信息 -q 输出有关信息队列(message queue)的信息 -s 输出有关信号量(semaphore)的信息
6.2 命令ipcrm:查看ipc remove
ipcrm -m <id> ipcrm -q <id> ipcrm -s <id>
删除所有的>0的共享内存:
ipcs -m | grep $user | awk '$6>0 { print $2 }' | xargs ipcrm -m