机器学习(八)支持向量机svm终结篇
一、SMO算法简单推导
前面讲了一大堆都是理论推导,最后得到的公式是:
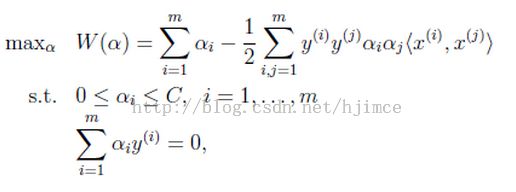
KKT条件为:
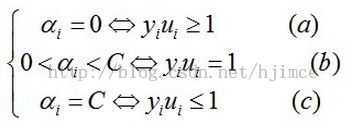
接着我们要将的就是如何求解,编程如何实现,这才是我们学习的真正目的。
在这里我们先不管KKT条件,相关公式推导,我们的目的是求解拉格朗日乘子,求解上面那么方程,我们可以用梯度上升的方法进行求解。然而按照梯度上升的思想,如果我们对α1进行迭代更新的时候,我们需要固定除了α1以外的所有参数,然后对上面的式子进行求解偏导数。如果按照这种思路进行求解,我们发现约束等式变为:
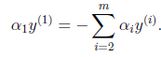
根本无法对α1进行迭代更新,因此我们需要一次性选择两个参数进行更新,也就是我们想要对αi进行更新的时候,还要再选择αj,这样就有
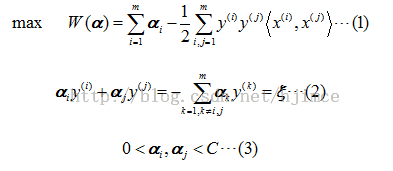
上面的公式三个公式,便是我们得到的结果,接着我们的目的是要消去αi,然后得到只有变量αj方程式。
步骤1:有方程(2)我们可以知道那是一条直线,当yi 与yj 异号的时候,这个直线就相当于αi-αj=ξ,然后根据![]() ,这样可以得到如图所示的图解:
,这样可以得到如图所示的图解:
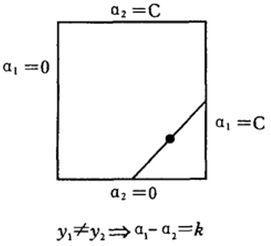
也就是说αj除了要在直线上之外,还要满足αj的取值点位于上面的正方形中。据此我们可以得到αj的取值范围:
![]()
其中上式中L、H的计算公式为:
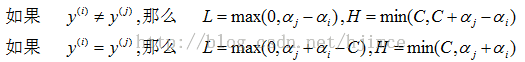
这一步我们仅仅根据公式(2)(3)得到更精确的αj取值范围,上面得到的αj依旧可以在直线上移动,只要移动的范围满足公式(4)即可。
步骤2:把约束方程(2)写成:
![]()
然后代入方程(1),消去αi,然后根据梯度上升法,求取αj,可得求取公式:
![]()
其中:
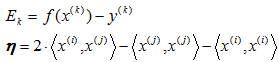
因此我们最后的αj取值为:
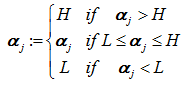
因此如果求得αj,这个时候我们就可以求取αi了。
步骤3:更新αi,最简单的方法是直接把更新得到的αj代入公式(5),就可以了。当然还可以用下面的式子求取:
![]()
因为yi值为1或-1,因此最后的求解公式为:
![]()
到了这里,我们已经实现的了对αi、αj的优化更新。
步骤4:接着我们需要更新b值,使得其对于数据点i,j都满足kkt条件,我们知道在前面的推导中,我们知道如果更新后的αi满足0<αi<C,这个时候根据KKT条件满足yi*gi(xi)=1,因此我们最后b的更新公式为:
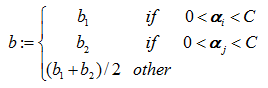
二、SMO算法实现
为了更为简单的学习SMO算法,我先从最简单,简化版的SMO算法,进行讲解,这样从简单到复杂,比较容易掌握。其实SMO算法的过程,只要根据上面的推导过程,代码一步一步的往下写,基本上没什么问题。
简化版SMO算法流程:
输入参数:训练数据点X,软约束参数C、迭代次数n
输出:W,b,拉格朗日乘子
1、初始化参数拉格朗日乘子α,b
2、循环迭代,直到满足最大迭代次数
{
(1)根据公式![]() ,计算W
,计算W
(2)遍历每个数据点xi,根据以下公式,判断其对应的拉格朗日乘子是否可以被优化(不满足以下KKT条件):
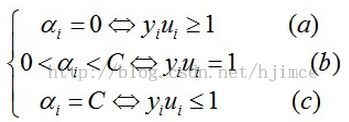
如果不满足KKT条件,那么随机选择另外一个数据点j,及其对应的拉格朗日乘子αj,以αi、αj为一对,固定其它的α,对这两个参数进行优化,具体优化步骤如下:
a、计算αj 优化值,根据如下公式:
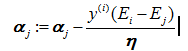
其中:
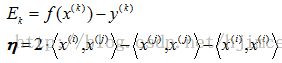
根据下面公式,计算αj的取值范围:
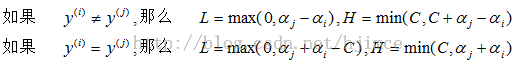
最后αj的最后更新值为:
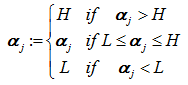
b、根据计算更新的αj计算αi,计算公式如下:
![]()
c、更新计算直线的截距 b,计算公式如下:
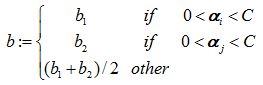
}
简化版SMO编程实现:
from numpy import *
from matplotlib.pyplot import *
#文件读取函数
def readdata(filename):
dataset=[];
labelset=[];
file=open(filename,'r');
for line in file.readlines():
linedata=line.strip().split('\t');
dataset.append([linedata[0],linedata[1]]);
labelset.append([linedata[2]])
dataset=mat(dataset,float);
labelset=mat(labelset,int);
return dataset,labelset
#随机选择函数
def SelectionJ(i,m):
j=i
while j==i:
j=int(random.uniform(0,m))
return j
#根据约束条件,计算取值范围
def LH(labeli,labelj,alphai,alphaj,C):
if labeli*labelj<0:
L=max(0,alphaj-alphai);
H=min(C,C+alphaj-alphai);
else:
L=max(0,alphai+alphaj-C)
H=min(C,alphaj+alphai)
return L,H
def smo(data,label,C,toler,maxiter):
#参数初始化
m,n=shape(data)
b=0;
alpha=mat(zeros([m,1]));
fx=mat(zeros([m,n]))
it=0;
while it<maxiter:
alphaPairsChanged = 0
for j in range(n):
fx[:,j]=multiply(multiply(alpha,label),data[:,j]);
weight=fx.sum(axis=0);
for i in range(m):
fxi=weight*data[i,:].T+b
#满足KKT条件:
#1.label[i]*fxi>1 && alpa[i]==0
#2.label[i]*fxi==1 && 0<alpa[i]<C
#3.label[i]*fxi<1 && alpa[i]=C
EI=fxi-label[i];#定义EI,则EI*label[i]=fxi*label[i]-label[i]*label[i]=fxi*label[i]-1
#根据定义的EI,可知根据符号 EI*label[i]与零比较,等价于上面的KKT条件
#那么不满足KKT条件的为:
#1、EI*label[i]>0 && alpa[i]>0 需要做优化
#2、EI*label[i]==0 && 这个时候数据点i位于边界上,不做优化处理
#3、EI*label[i]<0 && alpa[i]<C 需要做优化
if (EI*label[i]>toler and alpha[i]>0) or (EI*label[i]<-toler and alpha[i]<C):
#alpa[i]不满足KKT,随机选择alpa[j]与alpa[i]进行优化,且i!=j
j=SelectionJ(i,m);
alphai_old=alpha[i].copy()#因为下面要开始更新参数,所以我们
alphaj_old=alpha[j].copy()#深拷贝
#计算更新alpha[j]的公式:alpha[j]:=alpha[j]-(EJ-EI)/eta;
EJ=weight*data[j,:].T+b-label[j];
eta=2*data[j,:]*data[i,:].T-data[i,:]*data[i,:].T-data[j,:]*data[j,:].T
if eta>=0:print 'eta' ;continue#必满足2xy-x^2-y^2>=0 等于零的时候,下面公式的分母为零,因此不能继续计算
alpha[j]-=label[j]*(EI-EJ)/eta;
#计算alpha[j]的取值范围L,H
L,H=LH(label[i],label[j],alphai_old,alphaj_old,C)
#根据公式alpha[j]范围,重新求取alpha[j],公式如下:
#如果 alpha[j]>H 那么alpha[j]=H
#如果 L<=alpha[j]<=H 那么不需要更新
#如果 alpha[j]<L 那么alpha[j]=L
if alpha[j]>H:
alpha[j]=H
elif alpha[j]<L:
alpha[j]=L
#根据公式,更新alpha[i]
alpha[i]+=label[i]*label[j]*(alphaj_old-alpha[j])
#更新参数b 分别根据公式 计算b1、b2 并计算b值
b1=b-EI-label[i]*(alpha[i]-alphai_old)*data[i,:]*data[i,:].T- \
label[j]*(alpha[j]-alphaj_old)*data[i,:]*data[j,:].T
b2=b-EJ-label[j]*(alpha[i]-alphai_old)*data[i,:]*data[j,:].T- \
label[j]*(alpha[j]-alphaj_old)*data[j,:]*data[j,:].T
if 0<alpha[i] and alpha[i]<C:
b=b1;
elif 0<alpha[j] and alpha[j]<C:
b=b2
else:
b=(b1+b2)/2
alphaPairsChanged += 1
if (alphaPairsChanged == 0):
it+= 1
else:
it= 0
return alpha,b,weight
data,label=readdata("testSet.txt");
alpha,b,weight=smo(data,label,0.6,0.01,40)
print weight[0,0]
print weight[0,1]
y1=float((weight[0,0]*2+b)/(-weight[0,1]));
y2=float((weight[0,0]*8+b)/(-weight[0,1]));
plot([2,8],[y1,y2],'-')
for i in range(len(label)):
if label[i]<0:
plot(data[i,0],data[i,1],'.y')
elif label[i]>0:
plot(data[i,0],data[i,1],'.b')
show()
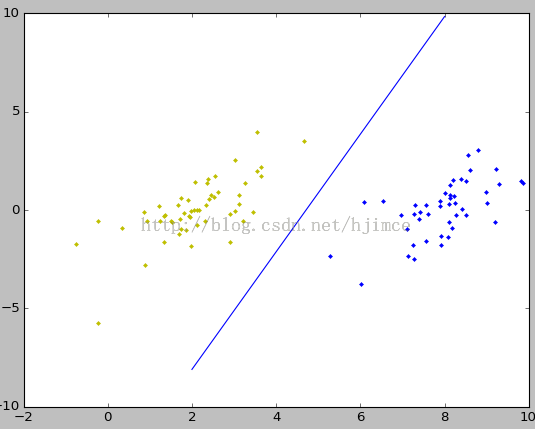
分类结果
至此可以说算法已经完成了,然而简化版的SMO算法有很多问题,比如速度非常慢,因此接着我们就要讲解进化版的SMO算法。本文地址:http://blog.csdn.net/hjimce/article/details/45421827 作者:hjimce 联系qq:1393852684 更多资源请关注我的博客:http://blog.csdn.net/hjimce 原创文章,转载请保留本行信息