【Similarity Search】Multi-Probe LSH算法深入
引言
上一小节中,我们初步介绍了Multi-Probe LSH算法的大致思路,为了不显得博客文章太冗杂,所以将这个话题分成几篇文章来写。
在该小节文章中,我将具体介绍一下生成微扰向量序列(a sequence of perturbation vectors)的方法及相关分析。
步进式探测(Step-Wise Probing)
n-step微扰向量Δ有n个非零坐标,根据位置敏感哈希的性质,距离查询q一步远(one step away)的哈希桶要比距离q两步远(two step away)所包含的数据点更加接近q。
这种想法激发了步进式探测方法,首先探测所有相差一步的哈希桶(1-step buckets),然后再探测所有两步的哈希桶(2-step buckets),以此类推。
对于LSH索引由L个哈希表和每个哈希表中M个哈希函数而言,
n-step buckets的总数是
所有s-step buckets之内的桶的总数是

下图显示了K近邻的桶距离的分布。左图显示,单一哈希值差异;右图显示,不同于查询点的哈希值的几组近邻哈希值。
从中可以看出,几乎所有K近邻的数据都被映射成一个哈希值或者是存在+1或-1之差;同时,大部分K近邻数据被映射到与查询数据的距离小于2步的哈希桶中。

成功概率的估计(Success Probability Estimation)
使用步进式探测的方法,对于查询点q来说,其哈希值的每一个坐标都被等同对待,即对每一个坐标进行微调(加1或者减1)的机会都是等同的。
回想一下哈希函数

- 首先,q与一个方向向量的点积使得q被映射到一条线上,该线被W分割成几个间隔。与q相邻的点p很可能被映射在q所在的间隔上或者其相邻的间隔。
- 实际上,p落入q的左右间隔依赖于q与间隔边界的临近程度,因此,q在每个间隔中的位置在考虑微扰的构造上是潜在的价值信息。
The position of q within its slot for each
of the M hash functions is potentially useful in determining perturbations worth considering.

上图描述了q的近邻数据落入相邻间隔的概率。fi(q)=ai·q+bi是哈希函数hi(q)对q的映射值;对于δ∈{-1,+1},令xi(δ)为q到间隔为hi(q)+δ的边界的距离,所以xi(-1)=fi(q)-hi(q)·W、xi(1)=W-xi(-1);方便起见,定义xi(0)=0。
对于一个固定的点p,fi(p)-fi(q)是一个均值为0的高斯随机变量,其方差与p-q的二范数的平方成比例。
我们假设W足够大,使得近邻点p有很大的概率映射为hi(q)、hi(q)+1、hi(q)-1。
所以,p落入间隔为hi(q)+δ的概率:
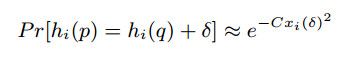
现在,我们估计使用微扰向量Δ=(δ1,...,δM)的成功的概率(找到与q临近的p):

使用微扰向量Δ找到q的近邻点的概率与下面的分数有关

该分数越小的微扰向量具有更大的概率使得找到q的近邻点,注意Δ的分数是与Δ和q都有关的函数。
该分数将作为接下来要介绍的定向查询探测序列的基础进行升序排列之用。
定向查询探测序列(Query-Directed Probing Sequence)
构造探测序列的一个最原始的方法是,对所有可能的微扰向量通过上面的公式计算分数并进行排序。但是,有L(2^M-1)个微扰向量,我们只希望使用其中很小的一部分。所以,显式地生成所有的微扰向量看上去没有必要,也是浪费的。接下来,我们描述一个按照分数升序排列生成微扰向量的更加有效的方法。
首先,我们注意到微扰向量Δ的分数依赖于Δ中非零坐标,所以,分数较低的微扰向量只含有几个非零坐标项。在生成微扰向量时,我们使用(i,δi)对的集合形式来表示非零的坐标项。*(i,δ)表示对于q的哈希值的第i个坐标加上δ项。
给定查询数据q和哈希函数hi,我们首先计算xi(δ),其中i=1,...,M,δ∈{-1,+1}。我们将这2M个值按升序排列,我们令zj表示为排序序列的第j个元素,如果zj=xi(δ),那么令πj=(i,δ),所以xi(δ)是升序排列中第j小的元素。这里满足xi(-1)+xi(+1)=W,如果πj=(i,δ),那么π2M+1-j=(i,-δ)。
现在,我们将微扰向量看做是{1,...,2M}的子集,称为扰动集(pertubation set)。对于一个扰动集A,微扰向量ΔA是从扰动集中得到的坐标集合{πj|j∈A}。
每个扰动集A都可以算一个分数
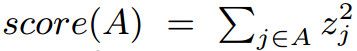
,该分数与想对应的微扰向量ΔA的分数是一样的。
这样,生成微扰向量的问题就简化成按照分数升序排列生成扰动集的问题。该过程分为两步:
- shift(A):该步骤是将max(A)换成1+max(A),比如shift({1, 3, 4}) = {1, 3, 5}
- expand(A):该步骤是为集合A增加一个元素1+max(A),比如expand({1, 3, 4}) = {1, 3, 4, 5}
产生扰动集的算法

min-heap是用于维护微扰向量候选集的,父集的分数不大于子集的分数。
该堆(heap)被初始化为集合{1},每次我们删除顶端节点(集合Ai),生成两个新的集合shift(Ai)和expand(Ai)。仅输出有效的顶端节点Ai。
该过程如下图所示:

对于j=1,...,M,πj和π2M+1-j是同一坐标的相反的扰动,一个有效的扰动集A至多只能有{j,2M+1-j}中的一个元素。
shift和expand操作还有两个性质:
- 对于一个扰动集A,shift(A)和expand(A)的分数要比A的分数大
- 对于任意一个扰动集A,shift和expand操作得到的序列是唯一的
小结
为了简化以上阐述,我们通过产生对于单一哈希表的扰动集的过程来更加细致的说明。
对于每个哈希表,我们维护由(i,δ)和zj构成的排序的清单,同时,还维护一个为所有哈希表生成扰动集的堆(a single heap)。该堆里每个候选的扰动集都对应一个哈希表t,当集合A和表t关联并从堆中去掉时,新生成的shift(A)和expand(A)也与表t关联起来。
转载请注明作者Jason Ding及其出处
Github博客主页(http://jasonding1354.github.io/)
CSDN博客(http://blog.csdn.net/jasonding1354)
简书主页(http://www.jianshu.com/users/2bd9b48f6ea8/latest_articles)
百度搜索jasonding1354进入我的博客主页