【网络挖掘:成就与未来方向】之数据挖掘导论
一、数据挖掘导论
为什么要数据挖局?
计算机化和自动化数据采集导致了极其庞大的数据存储。如沃尔玛2000家商店每天产生20M的事务。
原始数据 --> 模式 --> 知识
可伸缩性、渴望更多的自动化使得更多的传统技术不那么有效,如统计方法、关系查询系统、OLAP在线事务处理。
1、数据挖掘过程
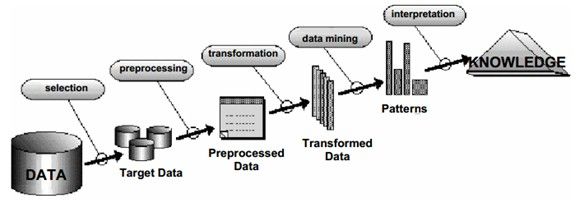
2、数据挖掘技术
基本技术:分类、聚类和关联规则;
其他:序列模式、回归和偏差检测。
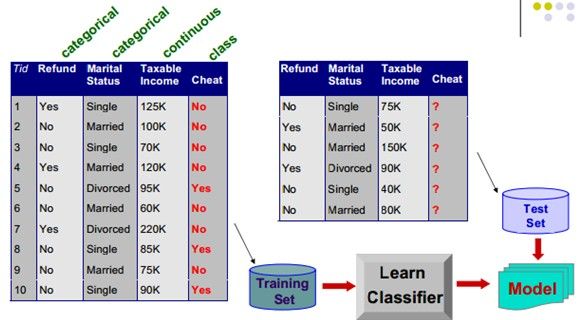
1)分类(Classification)
给定一个记录的集合叫做训练集(TrainingSet)。
每条记录包含一组属性(attribute),一个属性就是一个类别(class)。
为类属性寻找一个模型(model),作为其他属性值的一个函数。
目标:之前看不见的(previouslyunseen)记录应当尽可能精确地被指定到一个类别中。
一个测试集(Test Set)用来决定模型的精确度。通常地,给定的数据集被分为训练集和测试集,训练集用来建立模型而测试集用来验证它。
分类示例:
分类技术:
基于决策树的方法(Decision Treebased Methods);
基于规则的方法(Rule-basedMethods);
记忆基础推理法(Memory basedreasoning);
类神经网络(Neural Network);
基因算法(Genetic Algorithms);
朴素贝叶斯和贝叶斯网络(Naïve Bayesand Bayesian Belief Networks);
支持向量机(Support VectorMachines)。
2)聚类(Cluster)
什么是聚类分析?
找到相似或相关的(similar orrelated)对象并对齐进行分组,且使得不同组中的对象不同或者不相关(different or unrelated)。
基于从数据中发现的信息,这些信息描述了对象及其它们之间的关系。
也叫做无监督分类(UnsupervisedClassification)。
应用程序:
用于理解(Understanding)——对相关文档进行分组理解或找到具有相似功能的基因和蛋白质。
用于总结(Summarization)——降低大数据集的规模。
网络文档基于相似性度量(Similarity Metric)进行分组。
最常见的相似性度量是两个文档向量的点积。
以下不是聚类分析:
监督分类(Supervised Classification)——有分类标签信息;
简单分割(Simple Segmentation)——把学生按照注册时姓的字母顺序分组;
查询结果(Results of a Query)——分组是外部规范的结果;
图划分(Graph Partitioning)——一些相互关联和协同,但领域不同。
一个群组(或者簇,Cluster)的概念是模糊的。
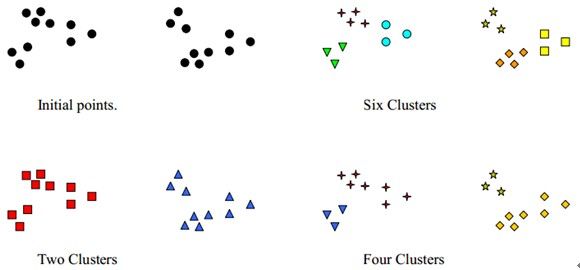
聚类的类型:
一个集群(clustering)是一个群组/簇的集合。
一个重要的区别是集群的分层和分块。
分块聚类(PartitionalClustering)——数据对象被划分到不同的子集(簇)中,每个数据对象只属于一个子集;
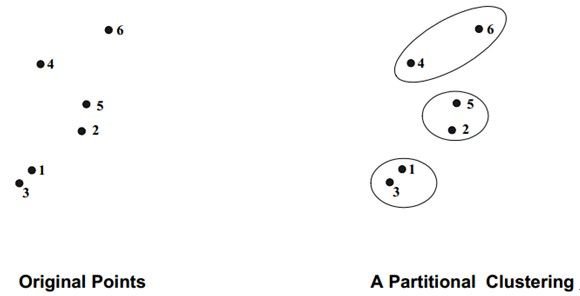
分层聚类(Hierarchical Clustering)——一组嵌套的簇被组织为一个层次树的结构。
又叫凝聚聚类(agglomerativeclustering)。
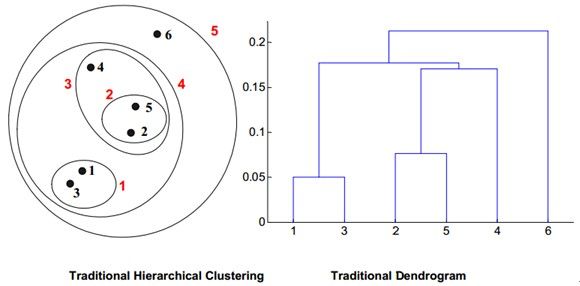
簇集之间的其他区别:
独占与非独占(Exclusive versusNon-exclusive)——在非独占聚类中,一个点可以属于多个簇;
模糊与非模糊(Fuzzy versusNon-fuzzy)——在模糊聚类中,属于每个簇的每个点都有一个介于0到1之间的权重,所有权重和必须为1,概率聚类也有类似的特征;
部分与整体(Partial versusComplete)——在某些情况下,我们只想对数据的一部分进行聚类。
3)关联规则挖掘(AssociationRules Mining)
给定一组记录(records),发现其中的规则(Rules),这个规则可以根据记录中的其他项目(items)预测一个项目的出现。
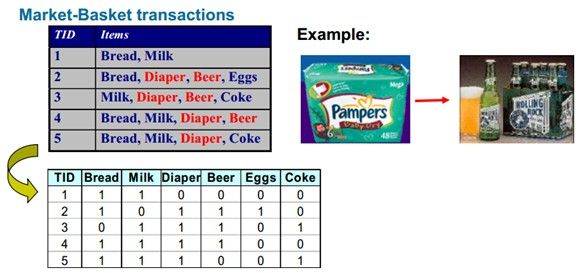
关联规则的定义:

如图,以牛奶和尿布对啤酒的关联规则为例:
支持度(support)= 牛奶、尿布和啤酒同时出现的次数/ 记录的总数
置信度(confidence) = 出现牛奶和尿布的同时也出现啤酒的记录数 / 牛奶和尿布同时出现的记录数
目标:发现所有支持度 >= 最小支持度(minsup)且置信度 >= 最小置信度(minconf)的规则。
关联规则的挖掘步骤:
1. 生成所有的频繁项集(Frequent Itemsets),也就是支持度大于等于最小支持度的项目集合;
2. 从每一个频繁项集中生成高置信度关联规则。每条规则都是一个频繁项集的二分。
这是一个开销很大的操作。
4)序列模式发现(SequentialPattern Discovery)
给定一组对象,每个对象具有事件发生的时间,有些事件之间具有很强的依赖性,发现这种规则可以预测事件的发生。
![]()
5)回归(Regression)
基于线性或非线性依赖模型根据一个连续变量的已有值预测其下一个值。
在统计和神经网络等领域有很深的研究。
例如,根据广告的开支量预测一个新产品的销售量,股市指数的时间序列预测。
6)偏差检测(DeviationDetection)
发现与先前测量的或规范的数据变化最显著的数据。
通常区别于其他数据挖掘技术单独分类,偏差往往是罕见的。
分类、聚类和时间序列分析的改进可以用来实现这个目标。
统计中的孤立点检测。
翻译有不恰当的地方,欢迎大家指正!
原文地址:http://www.ieee.org.ar/downloads/Srivastava-tut-pres.pdf