【linux学习笔记】linux作业
1.awk数组
awk用于数据处理很方便。awk的数组,是一种关联数组(Associative Arrays),下标可以是数字和字符串。因无需对数组名和元素提前声明,也无需指定元素个数 。数组元素用0或空串来初始化,这根据上下文而定。
<1>建立数组
<2>读取数组值 awk数组example:计算总数(sum)(这次做作业用到)
另外,见学校linux版帖子:http://bbs.byr.cn/#!article/Linux/119000
2. rm命令的管道操作问题(ll|grep "ab "|rm 问题的解决)
由于这里仅把ls的输出重定向,我们可以看作是把一个临时文件(其实并不是的)给了grep做参数,这个文件的内容是:2.log, 3.log。然后在把这个也看做是一个临时文件,传递给rm。也就是说用rm删除一个重定向,rm就执行不了了,因为rm不能拿重定向做参数
rm `ls|grep ab`才是正确的做法。
(另外,注意这里的引号``是ESC键下的符号!)
3、linux统计文件夹中文件数目
第一种方法:
ls -l|grep “^-”|wc -l
ls -l
长列表输出该目录下文件信息(注意这里的文件,不同于一般的文件,可能是目录、链接、设备文件等)。如果ls -lR|grep “^-”|wc-l则可以连子目录下的文件一起统计。
grep ^- 这里将长列表输出信息过滤一部分,只保留一般文件,如果只保留目录就是 ^dwc -l 统计输出信息的行数,因为已经过滤得只剩一般文件了,所以统计结果就是一般文件信息的行数,又由于一行信息对应一个文件,所以也就是文件的个数。
第二种方法:
find ./ -type f|wc -l(比如我这次用的就是:find ./ -name "*".log -empty,-->man find 就知道是怎么回事了 )
由于默认find会去子目录查找,如果只想查找当前目录的文件用find ./ -maxdepth 1 -type f|wc -l即可。
需要说明的是第二种方法会比第一种方法快很多,尤其是也统计子目录时。
4.crontab(源于古希腊的词"chronos",, “时间”的意思.)
用法见下图:
* * * * *
分时 日 月 天
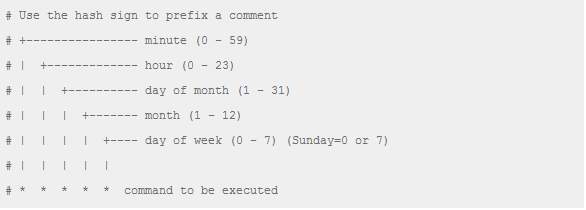
example:
0 2 1 * * root
rm -f /tmp/* #每月1号凌晨2点,清理/tmp下的文件
0 8 6 5 * root mail robin < /home/galeki/happy.txt #每年5月6日8点am给robin发信祝他生日快乐
0 8 6 5 * root mail robin < /home/galeki/happy.txt #每年5月6日8点am给robin发信祝他生日快乐
假如,我想每隔2分钟就要执行某个命令,或者我想在每天的6点、12点、18点执行命令,诸如此类的周期,可以通过 “ / ” 和 “ , ” 来设置:
*/2 * * * * root ............... #每两分钟就执行........
0 6,12,18 * * * root ............... #每天6点、12点、18点执行........