链式复制
作者提出一种方法, 在保证高可用和高吞吐的情况下,不以牺牲强一致性为代价提供分布式存储服务
要理解这篇文章解决的问题,可以看下另外两篇文章:
Brewer's CAP Theorem
Dynamo: Amazon’s Highly Available Key-value Store
CAP:对于分布式存储服务,不可能同时满足可用性、一致性和分区容错性(数据分布性的大小对系统的正确性、性能的影响)。由于分区容错性是分布式系统的基本需求,所以,分布式系统一般在可用性和一致性中做权衡。
Dynamo是非常经典的满足AP模型的系统,有非常多好的应用,包括:一致性Hash、vector clocks、Gossip等
链式复制期望从Replication的角度,保证系统的高可用和强一致性,其设计思路如下:
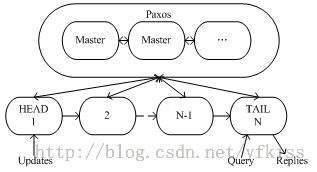
1.数据relication采用Chain Replication
b. 查询:为保证强一致性,客户查询只能在尾节点进行
a. 检测数据节点失败
b. 在新增或删除节点时,通知数据节点其新的predecessor及successor
c. 告知client 链表的头节点和尾节点
在作者的原型系统中,采用paxos协调master及其replicas,避免单点故障
3. 故障
master节点通过paxos算法保证服务一致性,只讨论数据节点故障。在出现故障时, 优先考虑一致性,而不是可用行,原文如下:
Servers are assumed to be fail-stop:
• each server halts in response to a failure rather than making erroneous state transitions, and
• a server’s halted state can be detected by the environment
我们看下不同节点故障,如何保证服务的强一致性
a. Head节点故障:successor节点成为新的Head节点,Head节点中已传播的更新继续传播,未传播的更新可以反馈给用户更新失败,不影响整体服务的强一致性!
b. 中间节点故障:master通知故障节点的predecessor节点更新successor,及故障节点的successor更新其predecessor,数据重新传播,并不影响一致性
c. Tail节点故障:Tail节点的predecessor节点成为新的TAIL节点,由于这个predecessor节点已有更新是TAIL节点的超级,从用户的角度看,数据变多了,并不影响用户读一致性
4. Thoughput
论文将chain replication和其他几种常见的replication 方式做了比较,如下:
a. chain: chain replication
b. p/b: primary/backup replication
c. weak-chain: 可以在chain replication的任意节点上做查询(并不保证强一致性)
d. weak-p/b: 可以在主从复制的任意节点上做查询(并不保证强一致性)
作者对比了在不同数据节点的情况下,随着更新比例的变化,系统整体Throughput的变化,如下图:
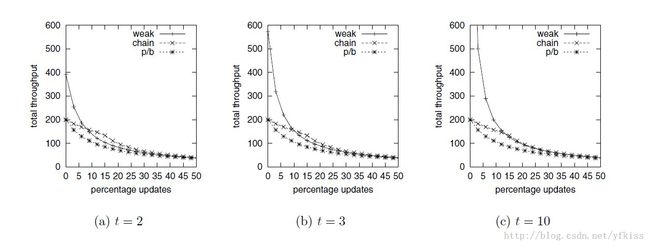
Weak-Chain和Weak-P/B 性能基本一致。随着Update比例的提高,各种replication Throughput趋于一致。在update比例较低的情况下,Weak-Chain、Weak-P/B Replication的Throughput优势明显
通过系统分析和论文作者的一些实验,可以看到:
1. Chain Replication的设计的确可以保证系统的强一致性,但在故障时,一定程度上牺牲了可用性
2. 请求Update Latency有一定程度的牺牲
3. Update比例较低时,相比不满足强一致性的Replication方式,Chain Replication牺牲了Throughput
Chain Replication在对象存储领域应用较多,也有一些基于Chain Replication扩展的应用,有兴趣的同学可以参考下Object Storage on CRAQ