HTK孤立词语音识别小系统
我主要参考两篇博客搭建起这个语音识别系统的:http://my.oschina.net/jamesju/blog/116151 http://www.cnblogs.com/mingzhao810/archive/2012/08/03/2617674.html
感谢两位博主的无私奉献。
我实现的是6个单词的识别,即:hello, world, port, starboard, standby, steer 新建八个文件夹: def, hmms, models, lab, sig, mfcc, results, test,如图:

1.数据录制与标注,涉及文件夹:sig, lab
在命令提示符中进入当前目录,就是上面八个文件夹所在的目录,然后进入sig目录,我们先把录制的.sig格式语音和.lab格式的标注文件放这里。先录制第一个单词,即“hello”.在命令提示符中输入:HSLab hello.sig出现录音与标注界面,按下rec录音,按下stop停止录音,然后按下mark进行标记,并对每一段标记命名(Mark后点Labelas)。前后为静音,中间为识别单词,注意,每段标记需要有一定的间隔,不能重合,否则在使用Hinit的时候会出错。标记完后点击保存,注意命名,默认是hello_0.lab和hello_1.lab,需要手动更改。如图:

重复录制10遍hello并标注,并用同样方法录制与标注剩余的单词各10遍。然后把sig文件夹里的.lab文件剪切到lab文件夹。hello_1.lab中的数据为:
![]()
2.原始语音文件转换为特征矢量文件,涉及文件夹: sig,lab,mfcc,test
(1)在test文件夹中新建analysis.conf文件,内容为:
SOURCEFORMAT=HTK TARGETKIND=MFCC_0_D_A WINDOWSIZE=250000.0 TARGETRATE=100000.0 NUMCEPS=12 USEHAMMING=T PREEMCOEF=0.97 NUMCHANS=26 CEPLIFTER=22
具体参数介绍详见HTKbook。
(2)在def文件夹中新建targetlist.txt,内容为(由于有6个单词,每个单词有10条,共60条,故这里我就列出了前10条,即hello的转换,大家照着这个格式复制5遍,把hello替换成其他单词即可):
sig/hello_1.sig mfcc/hello_1.mfcc sig/hello_2.sig mfcc/hello_2.mfcc sig/hello_3.sig mfcc/hello_3.mfcc sig/hello_4.sig mfcc/hello_4.mfcc sig/hello_5.sig mfcc/hello_5.mfcc sig/hello_6.sig mfcc/hello_6.mfcc sig/hello_7.sig mfcc/hello_7.mfcc sig/hello_8.sig mfcc/hello_8.mfcc sig/hello_9.sig mfcc/hello_9.mfcc sig/hello_10.sig mfcc/hello_10.mfcc
然后输入命令:Hcopy -A -D -C test/analysis.conf -S def/targetlist.txt
出现的界面为:

然后在mfcc文件夹中出现.mfcc文件,如图:

3.建立HMM模型,涉及文件夹:models,test,hmms,lab
(1)在models文件夹中新建7个文件,即:hmm_hello, hmm_world, hmm_port, hmm_starboard, hmm_standby, hmm_steer, hmm_sil
在hmm_hello文件中输入如下内容:
~o <VecSize> 39 <MFCC_0_D_A> ~h "hello" <BeginHMM> <NumStates> 10 <State> 2 <Mean> 39 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 <Variance> 39 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 <State> 3 <Mean> 39 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 <Variance> 39 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 <State> 4 <Mean> 39 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 <Variance> 39 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 <State> 5 <Mean> 39 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 <Variance> 39 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 <State> 6 <Mean> 39 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 <Variance> 39 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 <State> 7 <Mean> 39 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 <Variance> 39 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 <State> 8 <Mean> 39 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 <Variance> 39 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 <State> 9 <Mean> 39 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 <Variance> 39 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 <TransP> 10 0.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.5 0.5 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.5 0.5 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.5 0.5 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.5 0.5 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.5 0.5 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.5 0.5 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.5 0.5 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.5 0.5 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 <EndHMM>
其他5个单词只需把~h”hello”中的hello替换即可。
sil即静音模型,在hmm_sil中输入如下内容:
~o <VecSize> 39 <MFCC_0_D_A> ~h "sil" <BeginHMM> <NumStates> 3 <State> 2 <Mean> 39 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 <Variance> 39 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 <TransP> 3 0.0 1.0 0.0 0.0 0.5 0.5 0.0 0.0 0.0 <EndHMM>
(2) hmm初始化
在test文件夹中新建trainlist.txt文件,内容为(这里只列出了hello的10条,其他5个单词复制5遍替换hello即可):
mfcc/hello_1.mfcc mfcc/hello_2.mfcc mfcc/hello_3.mfcc mfcc/hello_4.mfcc mfcc/hello_5.mfcc mfcc/hello_6.mfcc mfcc/hello_7.mfcc mfcc/hello_8.mfcc mfcc/hello_9.mfcc mfcc/hello_10.mfcc
在hmms文件夹中新建hmm0文件夹,然后执行命令:
Hinit -A -D -T 1 -S test/trainlist.txt -M hmms/hmm0 –H models/hmm_hello –l hello –L lab hello Hinit -A -D -T 1 -S test/trainlist.txt -M hmms/hmm0 –H models/hmm_world –l world –L lab world Hinit -A -D -T 1 -S test/trainlist.txt -M hmms/hmm0 –H models/hmm_port –l port –L lab port Hinit -A -D -T 1 -S test/trainlist.txt -M hmms/hmm0 –H models/hmm_starboard –l starboard –L lab starboard Hinit -A -D -T 1 -S test/trainlist.txt -M hmms/hmm0 –H models/hmm_standby –l standby –L lab standby Hinit -A -D -T 1 -S test/trainlist.txt -M hmms/hmm0 –H models/hmm_steer –l steer –L lab steer Hinit -A -D -T 1 -S test/trainlist.txt -M hmms/hmm0 –H models/hmm_sil –l sil–L lab sil
初始化hello完成界面如图:

所有单词初始化完成后我们可以在hmm0文件夹中得到如下文件:

这一步很容易出错,如果出错请检查数据标注的时候是否有重合。
(3)如果初始化成功,则可以进行hmm训练
在hmms中新建三个文件夹,hmm1,hmm2,hmm3
使用命令:
HRest -A -D -T 1 -S test/trainlist.txt -M hmms/hmm1 -H hmms/hmm0/hmm_hello -l hello -L lab hello HRest -A -D -T 1 -S test/trainlist.txt -M hmms/hmm2 -H hmms/hmm1/hmm_hello -l hello -L lab hello HRest -A -D -T 1 -S test/trainlist.txt -M hmms/hmm3 -H hmms/hmm2/hmm_hello -l hello -L lab hello
这里只列出hello的训练,其他单词与sil的训练只需把hello替换成相应单词和sil即可。经过三次迭代后的界面如图:
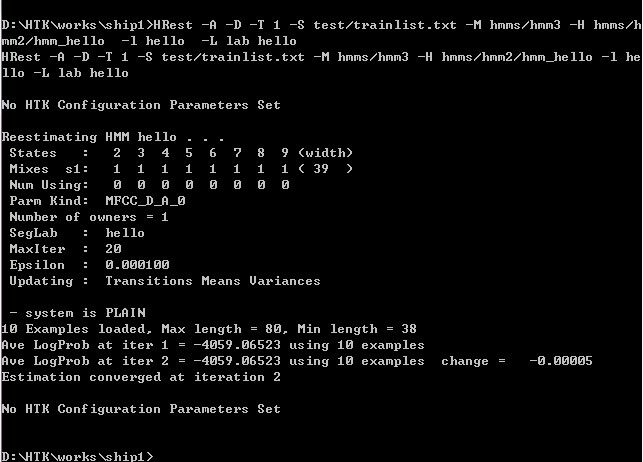
最后我们可以在hmm3文件中得到如下内容:

4.建立语法规则与字典,涉及文件夹:def
(1)在def文件夹中新建gram.txt文件,输入语法:
$WORD=HELLO | WORLD | PORT | STARBOARD | STANDBY | STEER;
({START_SIL}[$WORD]{END_SIL})
(2)在def文件夹中新建dict.txt文件,输入字典:
HELLO [hello] hello WORLD [world] world PORT [port] port STARBOARD [starboard] starboard STANDBY [standby] standby STEER [steer] steer START_SIL [sil] sil END_SIL [sil] sil
(3)建立任务网络
输入命令:Hparse -A -D -T 1 def/gram.txt def/net.slf
在def文件中生成了net.slf文件,其内容形式如下:

5.识别,涉及文件夹:def, hmms, models, test,results
(1) 在results文件夹中新建reco.mlf文件
(2) 在test文件夹中新建hmmsdef.mmf文件,其内容为hmms/hmm3文件夹中的所有hmm_xxx的数据,注意:在第一个复制进去的hmm_xxx为全部数据,剩下的从第一行的~h开始复制,也就是说只保留第一个~o。
(3) 此时可以用一个.mfcc文件进行测试,先在test文件中新建一个hmmlist.txt文件,内容为:
hello world port starboard standby steer sil
命令为:Hvite -A -D -T 1 -H test/hmmsdef.mmf -i result/reco.mlf -w def/net.slf def/dict.txt test/hmmlist.txt mfcc /hello_1.mfcc
识别结果的界面为:

看到START_SIL HELLO END_SIL了吗?这就识别出了hello,当然在resuls文件夹中也保存了识别结果:
![]()
(4) 交互识别
在test文件夹中新建directin.conf文件,内容为:
SOURCERATE=625.0 SOURCEKIND=HAUDIO SOURCEFORMAT=HTK TARGETKIND=MFCC_0_D_A WINDOWSIZE=250000.0 TARGETRATE=100000.0 NUMCEPS=12 USEHAMMING=T PREEMCOEF=0.97 NUMCHANS=26 CEPLIFTER=22 AUDIOSIG=-1
输入命令:Hvite -A -D -T 1 -C test/directin.conf -g -H test/hmmsdef.mmf -w def/net.slf def/dict.txt test/hmmlist.txt
此时出现如下界面:
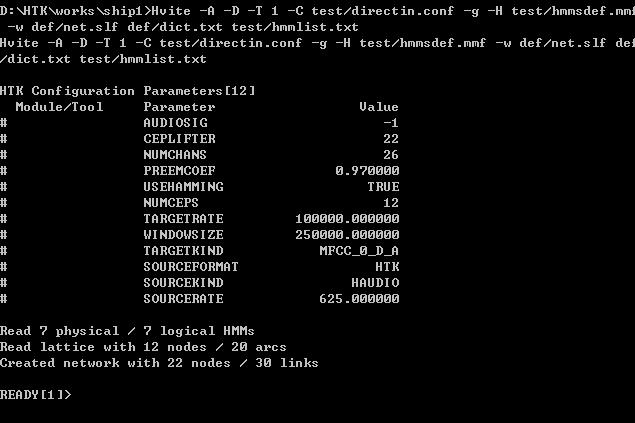
好了,开始说话吧!说一个单词然后回车就能看到识别结果,然后继续说,如图:
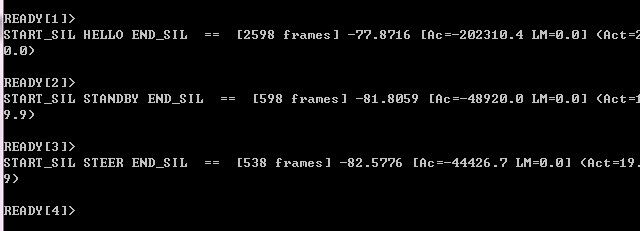
貌似识别率还可以,变着声说都能识别出来。至此,一个简单的孤立词语音识别小系统就算完成了。
6. 性能评价,涉及文件夹:test,results
(1)在test文件夹中新建文件ref.mlf,输入内容形如下列(这里只列举hello,每个单词选3个.lab文件即可):
#!MLF!# "lab/hello_1.lab" 20625 5693750 sil 5778750 10477500 hello 10562500 14500000 sil "lab/hello_2.lab" 20625 4995000 sil 5058750 12975625 hello 13039375 14500000 sil "lab/hello_3.lab" 20625 5333750 sil 5397500 10520000 hello 10541250 14500000 sil
(2)在test文件夹中新建testlist.txt文件,用以创建测试路径,内容形如下列:
test/mfcc/hello_1.mfcc test/mfcc/hello_2.mfcc test/mfcc/hello_3.mfcc test/mfcc/world_1.mfcc test/mfcc/world_2.mfcc test/mfcc/world_3.mfcc test/mfcc/port_1.mfcc test/mfcc/port_2.mfcc test/mfcc/port_3.mfcc test/mfcc/starboard_1.mfcc test/mfcc/starboard_2.mfcc test/mfcc/starboard_3.mfcc test/mfcc/standby_1.mfcc test/mfcc/standby_2.mfcc test/mfcc/standby_3.mfcc test/mfcc/steer_1.mfcc test/mfcc/steer_2.mfcc test/mfcc/steer_3.mfcc
(3)使用命令:
Hvite -A -D -T 1 -S test/testlist.txt -H test/hmmsdef.mmf -i results/reco.mlf -w def/net.slf def/dict.txt test/hmmlist.txt
完成界面为:
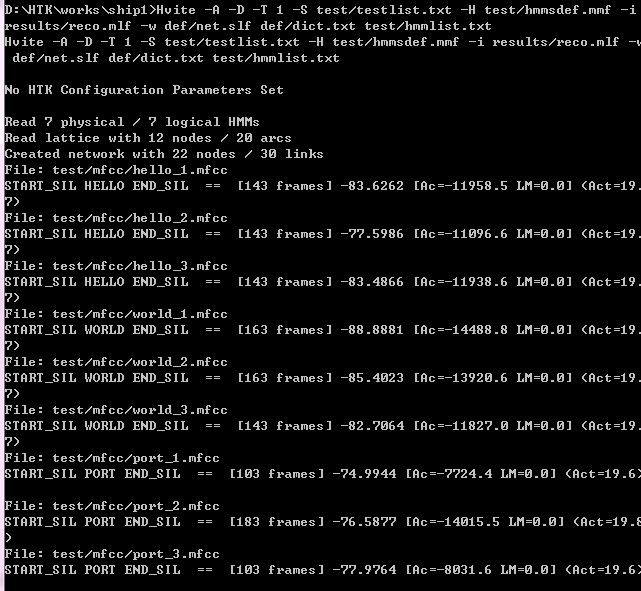
results文件中的reco.mlf文件保存了结果:
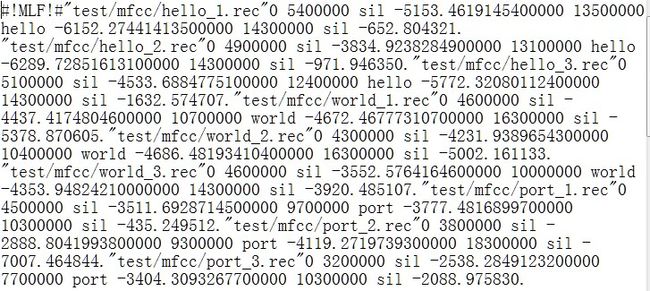
(4)错误率统计
在test文件夹中新建labellist.txt文件,内容为:
lab/hello_1.lab lab/hello_2.lab lab/hello_3.lab lab/world_1.lab lab/world_2.lab lab/world_3.lab lab/port_1.lab lab/port_2.lab lab/port_3.lab lab/starboard_1.lab lab/starboard_2.lab lab/starboard_3.lab lab/standby_1.lab lab/standby_2.lab lab/standby_3.lab lab/steer_1.lab lab/steer_2.lab lab/steer_3.lab
然后使用命令:HResults -I test/ref.mlf test/labellist.txt results/reco.mlf
得到错误率统计界面:
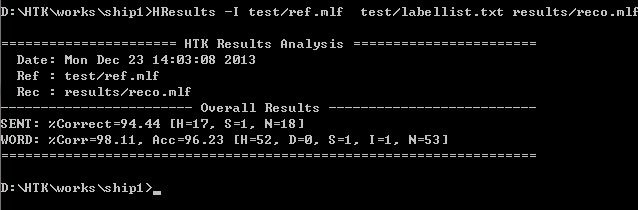
SENT: %Correct=94.44 为句子识别率,WORD:%Corr=98.11为单词识别率。
7. 总结
用HTK建立一个孤立词识别系统还是比较方便的,刚开始接触的时候总会遇到各种问题,得慢慢摸索才能解决。下一步将使用HTK搭建一个小词汇量连续语音识别小系统(200词左右)。所有文件已经上传到CSDNhttp://download.csdn.net/detail/cdj0311/6757935,能直接使用。