Percolator Google的海量数据增量处理系统
作者:刘旭晖 Raymond 转载请注明出处
Email:colorant at 163.com
BLOG:http://blog.csdn.net/colorant/
最近了解了一下基于HBase的分布式事务的实现方案,首先当然是要看一下google的percolator的paper了,顺便了解了一下几个相似的开源实现。
关键字
Percolator,BigTable, 分布式事务, 增量计算
== 目标问题 ==
Percolator的目标是在海量规模的数据集上提供增量更新的能力,并通过支持分布式的事务来确保增量处理过程的数据一致性和整体系统的可扩展性。
这个目标的需求来源于对谷歌的网页索引系统的改进,此前谷歌的网页索引系统采用的是基于MapReduce的全量批处理流程,所有的网页内容更新,都需要将新增数据和历史全量数据一起通过MapReduce进行批处理,带来的问题就是网页索引的更新频率不够快(从爬虫发现网页更新到完成索引进入检索系统,需要2-3天或者更长的周期)
== 核心思想 ==
构建这样的系统,本质的需求是
- 首先,底层的存储系统中,数据集本身必须是可以水平扩展,并支持增量更新的
- 其次,要保证增量处理的吞吐率,必然需要支持大量并发的数据更新操作(这点和基于MR的处理过程不一样),在这种应用场景下,分布式事务的支持也就成为了一个必须要支持的特性,通过分布式事务的支持,可以大大降低业务开发的难度,减少并发任务可能带来的数据一致性问题,本质上是为了保证整体系统的可靠性和易用性。
- 最后,Percolator的目标还包括提供一个增量处理的流程框架模型,用于驱动实际应用逻辑的运转。
对于上述需求,传统的DBMS可以满足事务的需求,但是处理不了海量规模的数据;MR相关的批处理系统难以做到高效的增量更新;BigTable类的NoSql技术支持海量规模数据的增量更新,但是不提供跨行跨表的分布式事务的支持。
Percolator的架构以BigTable为基础,通过增强其对分布式事务的支持能力来达到同时满足海量数据,增量处理,事务支持这三个需求目标。
由于BigTable本身提供行级别的事务支持,此外还提供数据Version的概念,所以Percolator自然的实现就是借助MVCC的思想,在BigTable的行锁基础上增加跨行和跨表的Snapshot级别的事务隔离。
MVCC的思想在传统DBMS中久已存在(Oracle/MySql等等),即使在谷歌自己的BigTable体系之上,也先后有MegaStore/Spanner等系统通过MVCC的思想来支持跨行事务,与MegaStore/Spanner等通过Paxos+MVCC来实现事务支持不同,Percolator的实现采用的是两阶段提交+MVCC,这么做大概是在满足应用需求的基础上,降低开发实现难度?
Percolator在效率方面没有做很精细化的考虑,所以和MegaStore类似,是通过功能叠加的形式,在BigTable的节点上运行Percolator的Worker来封装对BigTable的使用,以增强事务支持的(相比之下,Spanner没有通过BigTable来管理数据,而是直接管理了底层tablet)
此外由于MVCC对严格递增时间系列的需求,整个体系中需要增加TimeStamp Oracle 时间戳服务。
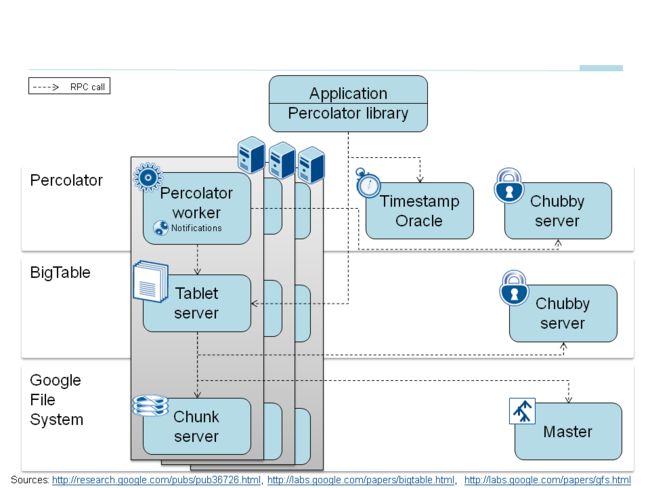
而两阶段提交对锁的管理产生的额外需求(主要是对失效worker遗留的锁的清理)是通过Chubby server对worker的状态监测来支持的。 综上,整个Percolator的系统组件框图(引用自官方相关PPT)如下:
== 实现 ==
实现上,percolator的分布式事务两阶段提交是通过在BigTable表内部每行数据中添加额外的column来标记相关的锁信息的。

简单的来说,就是在事务开始的时候,会对涉及修改的所有行在:lock column上标记加锁,然后在:datacolumn修改数据内容本身,最后在:write column上标记最新成功提交的数据的具体时间戳版本。这里面涉及到的加锁步骤,冲突解决,事务回滚等细节,有兴趣的自己看论文吧。
此外,事务的驱动框架,在Percolator里面是通过一个称为notification的机制来实现的,本质上就是表数据的变更会被用户编写的Observer观察到,并触发后续的事务。一个Percolator应用,会是由一系列的相关联的Observers触发链路串联起来的。应用程序通过写入起始的数据,触发链路的第一个Observer,执行事务,进一步更新数据,触发下一个Observer,直到完成整个应用逻辑。
在这条触发链路上,每个Observer触发的事务都是一个独立的事务,Percolator不提供跨Observer的事务特性,也不负责处理比如Observer循环触发等,这些逻辑的正确性需要由应用的实现方来保证。
为了实现notification机制,Percolator在BigTable的行数据内容上又额外添加了:notify和:ackcolumn用来起到通知变更和保证observer正确执行,具体细节同样请参考paper原文。
== Trade off ==
Percolator的整体设计实现,是有明显的取舍的,Percolator的增量处理流程在提高系统实时响应能力的同时,在性能上也付出了明显的代价,如论文里面提到的,基于2PC/MVCC实现的分布式事务方案在和底层BigTable,外部时间服务以及chubby锁服务的交互上,引入了大量额外的读写操作,相对于直接读写BigTable,写数据的代价约为400%,读数据的代价增加的不多,约5%。
从工程的角度来看,Percolator也做了大量如Timestamp批量获取,BigTable API改进,批量上锁,延迟清理冲突,数据预读取等优化,以缓解高并发增量系统引入的小批量数据操作和随机读写等行为带来的额外性能问题,但是这些措施在一定程度上反过来也会影响整体系统的latency响应速度。(Percolator的定位不是对latency有很高要求的系统,允许几十到上百秒的不确定的Latency延迟)
总体而言基于Percolator改进的网页索引系统Caffeine在处理同样规模和吞吐率的数据时,相对于原有的基于批量MR处理流程构建的系统,大概需要2倍左右的机器资源(但是latency的改进可以提高100倍以上)。
== 相关研究,项目等 ==
## 小米的Themishttps://github.com/XiaoMi/themis
Themis基本上就是percolator在HBase上的一个实现,但是相应的实现的是分布式事务着一部分,没有实现notification/observers机制。在Hbase Jira上也开过一个相应的Issue:https://issues.apache.org/jira/browse/HBASE-10999

在TimeStamp时间方面,使用的是小米自己开发的chronos https://github.com/XiaoMi/chronos
总体架构上与Percolator不同的地方是在事务的实现方面,不完全是在client Librery中,单行的事务处理基本是通过Hbase Coprocessor来实现的(比如对字段加锁,清除锁之类),在客户端client library中不需要相关的处理逻辑。
此外在实现细节方面,也做了一些工程上的变化,比如TimeStamp Server可以配置为本地的服务(要补充一下适用场合),对Prewrite阶段的locker,没有选择持久化。只写入memstore中以提高性能等
在应用方面,比如实现了给MR任务使用的InputFormat和OutputFormat,然后由于支持了跨表的事务,所以他们也尝试了通过Themis构建HBase的二级索引,做为一个独立的模块 Themis-indexer
至于小米内部将Themis应用在哪些具体的应用场景中,有机会要去了解一下。
## 韩国人的Haeinsa https://github.com/VCNC/haeinsa
Haeinsa的实现,主要思想和流程与percolator接近,通过乐观锁和两阶段提交来实现事务支持,但是在具体实现上进行了简化处理。
首先它去除了Time Oracle,也就是说全局时间戳服务的部分,因此服务器时间的同步需要由外部的机制来保证(比如NTPD)
其次上锁的机制也做了简化,只有一个lock column用来标识锁的状态,提交的数据的版本等等信息,因为锁信息进行了简化合并处理,需要在客户端缓存读取的lock标识的信息,用于在提交阶段进行判别。
简化了崩溃恢复机制,锁超时5秒以上就认为是错误超时事务,会被其它事务清除任务状态。
总体而言,因为客户端需要缓存数据,涉及到两次读取操作,错误恢复机制也比较简单,所以Haeinsa的使用定位也有一定的局限性,体现在:
每次事务处理的数据量不能太大(几百行)
事务时间超过5秒的话,容易被其它事务打断,对机器的时间同步要求也比较高。
加锁的机制决定了事务的隔离级别是Serializable(这个如果要反过来说,事务级别的设定决定了整体方案的设计也可以。。。)所以比较适用于并发事务的冲突概率比较低的场合。回来说Serializable这个级别,Haeinsa貌似也解决不了幻读的问题。
## Yahoo的OMID https://github.com/yahoo/omid
OMID的思路和percolator有着很大的区别,整体架构目标是LockFree的,在Yahoo内部的应用据说也比较成熟,篇幅问题,另外单独再写一篇学习文档来比较 :快速理解 Omid: Yahoo在HBase上的分布式事务方案
## Saleforce的Phoenix http://phoenix.apache.org/
Phoenix的事务的支持基本等于没有,要说有也只是read committed的,因为事务内数据变更的提交是在客户端合并操作以后,在commit阶段统一写入HBase的,也就是可以支持一定程度的放弃事务回滚数据的支持(根本就没提交给HBase嘛,就是放弃操作而已)。除此之外,不提供任何HBase本身功能以外的事务支持,虽然在过去的各种road map future work中一再都提到要加强事务的支持。
## 淘宝的oceanbase
这个,就是淘宝自己搞的一套东西了,和HBase完全没有关系,一开始的设计目标就是要支持事务,找时间仔细研究一下。