机器学习简明手册
机器学习简明手册
面向读者:有一定机器学习基础的。不是新手入门手册。实用导向的,所以不会扣细节和具体式子,只给出算法idea。能当作复习提纲,或者学习的roadmap吧。参考资料主要有《机器学习实战》(简称《实战》),《统计机器学习》,李航著(简称《统计》),cs229
k近邻(k nearest neighbour)
(注意名字不要跟k-means搞混了)很简单,求离样本最近的k个点中大部分是什么标签,就作为这个点的标签。计算量有点大,大数据貌似用不来的。虽然用kd树能优化到O(logN)
算法挺简单,但是传递出机器学习的一个重要思想:所谓的机器学习,从某种程度上来说,就是把一个新的样本放到历史收集到到大数据里去找某种程度的”相似”罢了,这种”相似”,有时候比较直接,有时候没那么直接。
可操作性的地方:
我们怎么衡量“距离”?
常用欧式距离(日常生活中理解的两点之间的距离)
看Mining of Massive Datasets 3.5 里面提到还有其他几种,具体用到的时候再去细看就行了。- Jaccard距离
- 余弦距离
- 编辑距离
- 海明距离
数据需要归一化。不然算距离就不准了。比如“汽车行驶公里数”这个特征可能上万,“使用年限”只有不到10。显然不归一化的话,算距离就会被某个特征dominate
k值的选择。貌似也没啥好办法,只能试了。k值太小、太大,那个是过拟合? 太小的时候过拟合,比如k=1。k=N就相当于用样本的众数来预测了,仔细想想,这样做某种程度上也说得通。
决策树
一系列的布尔节点生成的树形结构。
看个图应该就明白。
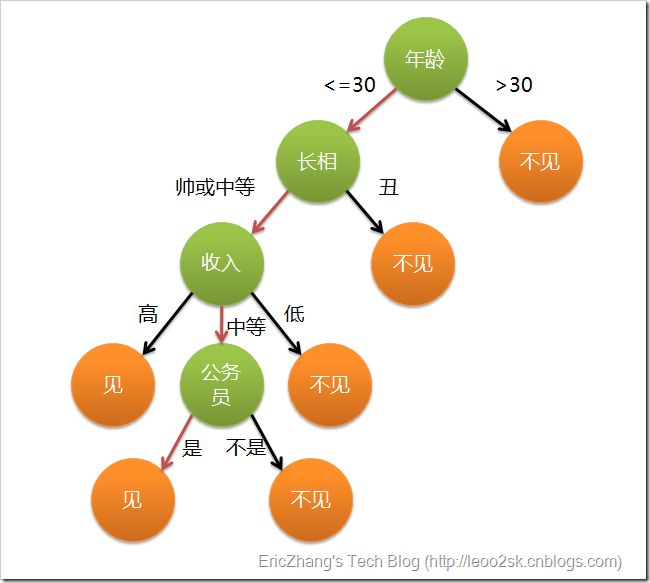
有个问题,决策树是二叉树还是多叉树?ID3和C4.5是多叉树,CART说是只能二叉树。不过多值(枚举)比如a1,a2,a3,也能转换成是否a1,是否a2,是否a3这三个布尔特征变成二叉树。
应该是很好理解,但重点就是该如何划分节点?树是递归结构,其实对每个节点就只有两个子问题:
1. 选哪个特征来分裂。
2. (对于连续变量还有) 选这个特征的哪个值来分裂,布尔特征就没这个问题。
分类的目的其实就是为了让无序的数据更有序,熟悉信息论的应该马上能联想到熵了。
- 熵:衡量无序程度。
- 信息增益(information gain),也叫互信息(mutual information):熵的减少。比如原来的一个数据集熵是A,划分后熵是B,信息增益就是A-B。 具体到B的计算,比如我们选了其中一个布尔特征x来划分树,
那么B = x为0的占比 * x为0这些样本的熵 + x为1的占比 * x为1这些样本的熵。
公式是g(D,A) = H(D) - H(D|A)
信息增益特征A,训练集D, 信息增益g(D,A) 等于经验熵H(D)减去条件熵 H(D|A)
这个就是ID3算法。
以信息增益作为划分训练集的特征,存在偏向于选择取值较多的特征的问题。使用信息增益比可以对这一问题进行校正。
– 李航 《统计学习方法》
这句话直观上怎么理解?选择取值较多的特征后,一般会变得更“有序”,我们想除去取值多(多叉树)的影响。
对比公式
- ID3: 公式是g(D,A) = H(D) - H(D|A)
- C4.5: 公式是gr(D,A) = g(D,A) /Ha(D) 就是原来ID3的基础上除以Ha(D),注意不是H(D)
Ha(D)= - ∑pi *log(pi) pi为特征a某个取值的占比。
把信息增益换成信息增益比,ID3算法就变成C4.5了。这里相当于做了归一化,有点类似于增长值和增长率的关系。
CART
CART(classification and regression tree)看名字可以知道不单单可以用于回归。限定了要二叉树。
回归树
跟k-means有点像。遍历特征j,再用启发式方法找切分点s。让划分出来的两陀尽量聚拢。
具体怎么衡量切分好坏? 算出切分后两个组的y(注意是y,不是x)的圆心c1和c2,然后让属于c1的∑(yi-c1)^2 和属于c2的∑(yi-c2)^2 和最小分类树
属于某个类的概率Pi,那么基尼指数
Gini(P)=1-∑Pi^2
就是把ID3算法的熵H换成Gini罢了。因为是二叉树,都不需要C4.5算信息增益比。
朴素贝叶斯
几个名字带“贝叶斯”的概念别搞混了。
贝叶斯概率公式
p(c|x) = p(x|c) * P(c) /p(x)
注意x是向量,c是label
这个公式怎么理解? 给你一个样本的特征x,怎么判断它的类别c,即p(c|x),比如给你一堆医学指标,然后判断是否病人有癌症。
我们可以统计训练数据里P(c)的概率,然后再统计一下 p(x|c) ,也就是得癌症的病人,出现x这种指标的概率有多大。
最后判断p(c=1|x) 和 p(c=0|x) 谁的概率大。
等等,这个好像有点扯蛋,我们如果样本里能得到p(x|c),难道还得不到p(c|x)?
(注意到x是个向量)朴素贝叶斯发挥作用就在这里了。
p(x|c)=p(x1|c) * p(x2|c) * p(x3|c) … * p(xn|c)
这个是加个朴素贝叶斯条件独立性假设的效果后才=的,现实中通常不成立,比如x1是某指标多少厘米,x2换成英寸,那两个特征显然不独立的。但实际中运用,效果还是有些合理的。就像以前学物理计算时候为了简化模型,忽略了阻力,但结果还是比较可用的,只是精度有些问题。
显然一下子豁然开朗了,虽然p(x|c)几乎在样本里获取不到(很难碰到检查指标完全跟你一样的人),但是p(x1|c)、p(x2|c)啥的,还是比较丰富的。或者另外的例子,垃圾邮件识别p(x1|c)、p(x2|c)就是垃圾邮件常见词汇出现的概率,比如“免费”,“折扣”,“优惠”这些词。这里有没联想起tf-idf里面的tf?不过tf-idf并没有处理label。
注意的点:
- p(x1|c)=0怎么办?相乘都是0了,平滑一下,分子多加上1,分母加上n(x∈R^n)。
- p(x1|c) * p(x2|c) … 都是很小的小数,相乘结果下溢怎么办?加上一个取对数操作,然后变成加法。 ln(a*b) = ln(a) + ln(b)
这两个技巧其他地方估计也用得上吧。
LR
普通的LR就不说了。
局部加权线性回归
有点像svm里面的高斯核 ,就是只考虑输入x附近的点(说到距离又想起k近邻了),离太远的权重就很低了。问题就是计算量比较大,而且predict的时候要保留整个数据集才行,这种叫做non-parametric algorithm(cs229 note1第15页)
加正则项
- L1正则叫做lasso
- L2正则叫做岭回归(ridge regression)
sgd加速
要点
- 取样一定要随机,不然会有抖动(不可分的样本)。
- a随着迭代减少才行。
缺失值处理
- 均值
- 特殊值,如-1
- 直接忽略有缺失值的样本
- 使用相似样本均值
- 使用ml方法来预测缺失值(蛋疼)
bagging
bagging全称是(bootstrap aggregating),好吧,以前还以为bagging是一个单词。
可重复抽样。然后得到多个样本进行多次训练得到多个模型。
最后,如果是分类问题就投票,回归问题就取平均。
经典的,看随机森林(random forest)吧。
boosting
思想挺简单,就是学错的样本加权,学对的样本降权,就像以前高中准备的错题本一样,哈哈。然后把weak learner合并到一起。boosting应该只是一个框架,因为只说明了思路,没说具体怎么操作,见wiki
AdaBoost
一种具体的Boost方法。
要点:
- 样本加权多少。每一轮训练完后重新给样本赋权am,分错的权重变大,分对的权重变小。
- 子模型权重多少。每一轮的子分类器的权重Wmi跟分类误差率相关。误差低的权重高
直觉上,这样做挺合理的。具体的权重式子比较复杂,就不列了。
以前觉得理解AdaBoost这样也就够了,如果式子没兴趣推导的话。 后来看了《统计学习方法》8.3提到AdaBoost的算法解释还挺有意思的
AdaBoost算法是模型为加法模型,损失函数为指数函数、学习算法为前项分步算法时的二分类学习方法。
二分类:突然才发现有个问题,AdaBoost是用于分类,不能用于回归,而且分类还是二分类。
加法模型: 就是说把模型加起来。如果是线性的函数y,相加起来其实没啥用,因为可以合并成一个函数,所以表示不了复杂函数。比如y1=a1*x + b1 , y2=a2*x + b2,可以合并成y=(a1+a2)*x+(b1+b2)。不过,AdaBoost用的子模型是分类器,而且取值为{-1,1},并且限定了最终加起来的函数是sign(x>0,y=1; x<0,y=-1},这样有正有负,加法才有意义
比如弱分类器是阶跃函数的话(x>v或x<v),而y={-1,1},这样可以组成复杂的函数,比如划分出[+, -, +, -}这样的区间。
- 损失函数为指数函数。 exp[-y*fm(x)] 可以展开为exp[-y( fm-1(x) + am * Gm(x) )] = Wmi * exp[ -y*am*Gm(x) ] ,求lose函数的极值,可以推到出am(子分类器的解)和样本权重Wmi。公式有点绕,反正意思就是加法模型我们得到A=A’+B, 那么exp(-A) = exp(-(A’+B) ) = exp(-A’)exp(-B) = w exp(-B), 样本权重w跟前项分步的结果A’跟相关,然后在给定的权重下,求解当前的子分类器B的最优解。exp(A+B)能变成exp(A)* exp(B),有没有联想起想起前面朴素贝叶斯防止下溢的技巧 ln(a*b)=ln(a)+ln(b)
从这个角度可以加深一下对AdaBoost的理解。
提升树
就是把AdaBoost的子分类器换成树,换成二分类树的话,就是前面提到的AdaBoost的特殊情况(子分类器权重都是1)而已。所以主要还是关注回归树的情况。其实就叫做GBRT。注意到加法模型的特点,对于回归的情况,第m个子回归模型直观上要拟合的是前m-1个模型的残差(residual),即r=y - fm-1(x),不过这个其实是当误差函数为平方误差时推导出来的。当损失函数比较复杂时怎么办?类似学LR的时候有gradient descent,我们不对x对梯度,而是对加法模型累加的函数fm-1 求梯度。而且我们只是用梯度近似残差,还得再线性搜索一下。《统计》里面也没细说怎么求梯度,那先这样吧。
k-means
标准的方法都懒得说了。
但是有k不好确定的问题,所以我们可以自顶向下二分K-means(bisecting K-means)。先分成两个,再选误差大的继续分成两个。
EM(Expectation Maximization)算法
有些基础的东西还是要懂的。
Jensen不等式
貌似记住一个图就行,大可不必扣细节。

k-means
EM算法描述起来可能有点抽象,可以用k-means作为实际例子直观感知一下。具体k-means算法就不罗嗦了,很简单。
EM
主要参考资料cs229 note8。简单说,EM就是在原来的likelihood函数加上一个latent random variables z ,而且注意 z 是离散值
问题是显示求解太难,所以要用EM算法了。
- (E-step) construct a lower-bound on l
- (M-step) optimize that lower-bound
cs229主要是从数学式子的角度来解释,所以其实不太好理解。对应到k-means实际例子,E-step就是算当前点离哪个圆心最近,把点归属到那个类(这种叫”hard” assigment, 而一般的情况我们是算一个概率 wi , 可以让离得近的分类概率大,离得远的概率小,这种叫”soft” assigment,k-means应该也能用”soft”,就是计算会复杂点)。然后M-step就是分配完点的新类别后, 重新算圆心等参数。
Thus, we simple set the Q′is to be the posterior distribution。– 构造 Jensen不等式,并使其取等号的结论
如果要说得直白一点,E-step( Q′is 就是latent variable z 的”soft assigment”的值)我们实际上算的是 z 的后验分布,就是当”圆心已经知道时”,算点归属到分类的概率。
而M-step就是假设当让人头痛的 z 已经知道后(记得这个是EM算法的唯一不同点),求解模型其他参数的最优值(跟以前的方法没两样了)。
这样交替迭代,有没有想起跟之前哪个很像?
The EM can also be viewed a coordinate ascent on J, in which the E-step maximizes it with respect to Q, and the M-step maximizes it with respect th θ
当然,具体的Jensen不等式的构造,收敛性证明等数学的东西就自己去看看吧。
隐马尔科夫模型
整理自《统计》
模型组成
- 初始概率分布
- 状态转移概率分布
- 观察概率分布
两个重要假设
- 齐次马尔科夫性假设。状态t只依赖状态t-1。 (跟朴素贝叶斯是不是效果有些像?能大大简化模型)
- 观测独立性假设。观测Ot只依赖状态It。
说到状态转移有没想起PageRank? 说到隐藏状态和观察序列有没想起EM算法?
EM算法是不是隐马尔可夫模型简化后的特殊情况?
| 隐马尔可夫模型 | EM算法 |
|---|---|
| 时序的 | “一次性”的 |
| 随着时间在一组状态中变换。(状态转移矩阵大小N*N) | latent变量 z 是离散值(可以当作1*N) |
| 观测结果也是枚举值 | 也可以是离散值 |
基本问题

图片来自http://www.cnblogs.com/gemstone/archive/2012/09/05/2671577.html
- 概率计算。输入模型λ、观测序列O, 求P(O|λ)。前向和后向两种方法,感觉差不多。因为有了齐次马尔科夫性假设之后,一层一层推就好了,前向和后向就起点不同罢了。
- 学习问题。如入观测序列O,求模型λ,使观测序列P(O|λ)最大。
- 预测问题,如入观测序列O,求模型λ,使状态序列P(I|λ)最大。
Apriori
频繁项集 经常出现在一块的物品集合。评价指标
支持度 出现该项的记录数/总的记录数
关联规则 频繁项集里的物品是否有强关联。评价指标
置信度 {尿布}->{啤酒} 的置信度= 支持度({尿布,啤酒}) / 支持度({尿布})。
所以{尿布,啤酒}即使是频繁项集,也不代表{尿布}->{啤酒}的关联规则一定存在。有点像准确率高不一定召回率也高的意思。
求解方法
只算一个项集是否频繁的话,那只能暴力扫描一遍了。如果要把所有的频繁项集都找出来就不能暴力扫了。
显然要递推,先找一个项的频繁项集。用A(1)来表示吧(下面符号不严谨,只是为了说明意思。不要太介意)。
然后怎么办?在一个项的频繁项集基础上再加上一项看看?虽然是可以,但是不够高效,比如有一项只出现过一次,根本就达不到阈值,枚举它也是徒劳。注意到一个项的频繁项集其实我们已经都找出来了,所以两个项的候选集合是A(1) * A(1) (笛卡尔积),候选集合找出来,其实还是得再过一遍判断是否subset。判断subset还是挺费的。
更一般的,A(k) = A(k-1) * A(1) 这样递推其实也行的,但历史数据利用得不够充分。
Apriori算法用的是A(k) = A(k-1)+ A(k-1)
s.t. A(k-2)=A(k-2)
就是说,直接利用两个A(k-1)的结果,但条件是其中要有k-2个元素相同,这样加起来才是有k个元素。比如说{1,2}和{1,3} ,{1}是相同的,相加一下等于{1,2,3}。显然把历史信息榨干了,这个就是Apriori算法的核心idea。
FP-growth
想想Apriori的瓶颈在哪?每次找的只能是候选集,所以还得扫一遍判断是subset的占比是否满足支持度。
FP-growth 核心idea就是利用trie树能压缩存储共有前缀的思想来表示集合元素,这样判断是否subset就没那么费了。算法只要刷两遍数据就得出结果。
算法描述起来挺绕的,但是先记住算法的核心idea,然后看看例子就很清楚了。比如这里有一个 关联规则挖掘算法 FP-growth的详细讲解
有acm竞赛背景的应该很好理解的。 就是很简单的东西,有些资料还写得听绕的,蛋疼。