Kettle调用Hadoop Job Executor实践(spoon5.0.1+cdh5.0.0)
版本:
Spoon:5.0.1 stable
CDH:5.0.0
Hadoop:2.3.0(CDH自带Hadoop)。
一、调用Hadoop Job Executor前准备:
1.下载shim包(可以到官网下载:http://wiki.pentaho.com/display/BAD/Configuring+Pentaho+for+your+Hadoop+Distro+and+Version,或者下载这个:http://download.csdn.net/detail/fansy1990/7298911、http://download.csdn.net/detail/fansy1990/7299163,这两个文件为分卷压缩文件),下载后解压缩到:Spoon_home/data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations目录。(不要修改解压后文件夹名)
2. 修改Spoon_home/data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\cdh50beta\*.xml 所有xml文件,把部署好的cloudera集群的配置文件拷贝替换即可。(注意如果是linux系统,目录斜线方向)
3. 修改Spoon_home\data-integration\plugins\pentaho-big-data-plugin\plugin.properties :(其值对应前面解压的文件夹名)
# here see the config.properties file in that configuration's directory. active.hadoop.configuration=cdh50beta
1. 在linux中运行 ./spoon.sh 打开Spoon,新建下面的任务:
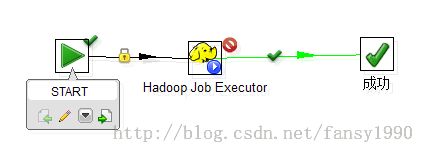
2. 编写java文件,如下:
package fz.org;
import java.io.*;
import java.util.*;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
@SuppressWarnings("deprecation")
public class WordCount2 extends Configured implements Tool {
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
static enum Counters { INPUT_WORDS }
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
private boolean caseSensitive = true;
private Set<String> patternsToSkip = new HashSet<String>();
private long numRecords = 0;
private String inputFile;
public void configure(JobConf job) {
caseSensitive = job.getBoolean("wordcount.case.sensitive", true);
inputFile = job.get("map.input.file");
if (job.getBoolean("wordcount.skip.patterns", false)) {
Path[] patternsFiles = new Path[0];
try {
patternsFiles = DistributedCache.getLocalCacheFiles(job);
} catch (IOException ioe) {
System.err.println("Caught exception while getting cached files: " + StringUtils.stringifyException(ioe));
}
for (Path patternsFile : patternsFiles) {
parseSkipFile(patternsFile);
}
}
}
private void parseSkipFile(Path patternsFile) {
try {
BufferedReader fis = new BufferedReader(new FileReader(patternsFile.toString()));
String pattern = null;
while ((pattern = fis.readLine()) != null) {
patternsToSkip.add(pattern);
}
} catch (IOException ioe) {
System.err.println("Caught exception while parsing the cached file '" + patternsFile + "' : " + StringUtils.stringifyException(ioe));
}
}
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String line = (caseSensitive) ? value.toString() : value.toString().toLowerCase();
for (String pattern : patternsToSkip) {
line = line.replaceAll(pattern, "");
}
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
reporter.incrCounter(Counters.INPUT_WORDS, 1);
}
if ((++numRecords % 100) == 0) {
reporter.setStatus("Finished processing " + numRecords + " records " + "from the input file: " + inputFile);
}
}
}
public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public int run(String[] args) throws Exception {
JobConf conf = new JobConf(getConf(), WordCount2.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
/* List<String> other_args = new ArrayList<String>();
for (int i=0; i < args.length; ++i) {
if ("-skip".equals(args[i])) {
DistributedCache.addCacheFile(new Path(args[++i]).toUri(), conf);
conf.setBoolean("wordcount.skip.patterns", true);
} else {
other_args.add(args[i]);
}
}*/
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
return 0;
}
public static void main(String[] args) throws Exception {
/*String [] arg= new String[]{
"hdfs://node33:8020/input/install.log",
"hdfs://node33:8020/output/wc002"
};*/
if(args.length!=4){
System.err.println("Usage: <input> <output> <hdfs://host:port> <host:port>");
System.exit(-1);
}
Configuration conf= new Configuration();
conf.set("fs.defaultFS", args[2]);
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.address", args[3]);
conf.set("mapred.remote.os", "Linux");
// conf.set("mapred.job.tracker","node33:8021");
int res = ToolRunner.run(conf, new WordCount2(), args);
System.exit(res);
}
}
3. 打包,使用eclipse的export命令,生成jar包。这里需要注意的是,如果是有多个main函数java文件,那么需要每个java文件打一个jar包来运行,在Hadoop Job Executor中并不能指定某个jar包中的主类,所以要在打包的时候指定,或者只把一个含有main函数的java文件放入jar包中。如果含有多个main的java文件,那么这个任务会把所有的java文件都运行一遍。
4. 配置 Hadoop Job Executor。
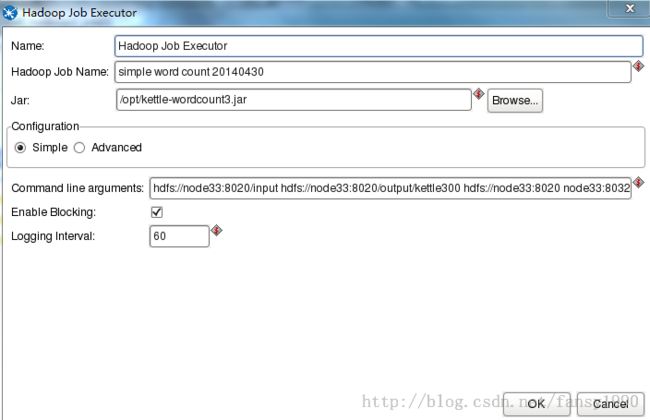
这里需要注意的是,在编写java文件的时候需要指定resource manager(使用的是yarn方式),所以下面的配置需要特别注意:
Configuration conf= new Configuration();
conf.set("fs.defaultFS", args[2]);
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.address", args[3]);
5. 保存后,点击运行即可。运行的时候在terminal中会有较多的log日志输出,可以查看。同时上面任务中的Enable Blocking 如果没有打钩,那么Job任务和kettle任务看起来像是异步的,在log中也可以看出。
三、windows 运行kettle。
如果按照上面的配置,而kettle是在windows上面运行的话,那么就会出现下面的错误:
2014/05/05 18:53:51 - Hadoop Job Executor - Caused by: java.io.IOException: Cannot run program "chmod": CreateProcess error=2, ϵͳÕҲ»µ½ָ¶
网上查看,这个是因为没有装cgwin的缘故,这里就不做操作了。
分享,成长,快乐
转载请注明blog地址:http://blog.csdn.net/fansy1990