在 Web 应用中增加用户跟踪功能
简介: 随着 Web 应用的复杂化,网站用户的操作过程也日益复杂,网站功能的多样化和交互性的提高为用户提供了多种可能的浏览路径。为了改进用户的使用体验,有时也是为了模拟用户的操作过程以帮助用户解决使用中的问题,需要能在日志中识别某个用户在整个 Session 中所经历的操作过程,本文针对基于 Apache Log4J 的 Web 应用,讨论如何利用 NDC 和 MDC 的机制,简单快捷的为 Web 应用日志增加用户跟踪的基础数据。通过本文,读者可以学习到关于 NDC 和 MDC 的工作机制,以及如何利用他们在一个 Web 应用中记录用户在一个网站上的全部行为和操作过程,并可以直接使用文中的代码和思路,提高工作效率。
进行用户跟踪的重要性
随着 Web 应用的复杂化,用户在网站上的操作过程日益复杂。网站功能的多样化和交互性的提高为用户提供了多种可能的浏览路径。对于一个复杂的站点,用户在网站上操作的行为模式和操作习惯的分析,会给网站的优化提供基础的数据支持。而从技术上要为这种分析提供支持,就需要记录下每个用户在网站上的操作过程。另一方面,这种数据的记录也有助于解决用户在使用中出现的问题。我们只要知道用户遇到问题的时间和一些基本信息,就可以从日志中查出此用户遇到问题时的操作过程,从而有助于再现用户的出错场景,进而帮助用户解决问题。此外,网站用户的安全审计和分析用户特征的数据挖掘等工作也需要提供一个方法能对用户的网站操作进行跟踪和纪录。
通常 Web 应用的开发者会在开发过程中设置很多的跟踪点,在这些跟踪点向日志系统输出一些应用程序运行的信息,如果这些信息足够全面的话,开发者就可以利用他们猜测出程序如何处理的用户请求,以及可能遇到了什么问题。但不幸的是,如果一个站点在设计阶段没有把用户跟踪作为系统必须解决的一个问题提出的话,这些日志很可能就只是开发者为满足系统调试的需要而设置的一些信息。当用户访问量急剧增加的的时候,就会出现下面的问题。
在一个高访问量的 Web 应用中,经常要在同一时刻处理大量的用户请求。Web 服务器会为每一个请求分配一个线程,每一个线程都会向日志系统输入一些信息,通常日志系统都是按照时间顺序而不是用户顺序排列这些信息的,这些线程的交替运行会让所有用户的处理信息交错在一起,让人很难分辨出那些记录是同一个用户产生的。另外,高可用性的网站经常会使用负载均衡系统平衡网络流量,这样一个用户的操作记录很可能会分布在多个 Web 服务器上,如果我们没有一种方法来标示一条记录是哪个用户产生的,从这众多的日志信息中筛选出对我们有用的东西将是一项艰巨的工作。
本文试图探讨的解决方案是建立在 Log4J 的基础上的,如果你的 Web 站点已经使用了 Log4J 作为日志系统的 API 接口,根据本文所介绍的方法,就可以很容易的在每一条日志上保存用户上下文信息,为用户跟踪保存基本的访问数据。为了更清晰地介绍这种方法,我们先对 Log4J 以及 NDC/MDC 做个简单的介绍。
Log4J 简介
Log4J 主要构件
Log4J 是 Apache 组织提供的一个日志组件, 它设计了灵活的配置文件,利用它可以在不更改程序的情况下,通过修改配置文件来调控日志的输出。下面是 Log4J 最主要的三大基本构件:
- 记录器(Loger)
对日志信息进行分类筛选。通过指定优先级,控制程序中日志信息的输出:高于优先级的日志可以被输出,低于优先级的日志则被忽略。
- 输出源(Appenders)
指定日志信息的输出设备。Log4J 目前支持的输出设备有以下几种:
- org.apache.log4j.ConsoleAppender(控制台)
- org.apache.log4j.FileAppender(文件)
- org.apache.log4j.DailyRollingFileAppender(每天产生一个日志文件)
- org.apache.log4j.RollingFileAppender(文件大小到达指定尺寸的时候产生一个新的文件)
- org.apache.log4j.WriterAppender(将日志信息以流格式发送到任意指定的地方)
- org.apache.log4j.SocketAppender (Socket)
- org.apache.log4j.NtEventLogAppender (NT的Event Log)
- org.apache.log4j.JMSAppender (电子邮件)
程序员也可以根据自己的需要定制 Appenders,实现更复杂和更为方便实用的日志管理,比如把日志输入数据库,或者传输到统一的日志服务器,等等。
- 布局(Layouts)
指定日志输出的格式。Log4J 提供的 Layout 有以下几种:
- org.apache.log4j.HTMLLayout(以 HTML 表格形式布局)
- org.apache.log4j.PatternLayout(可以灵活地指定布局模式)
- org.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串)
- org.apache.log4j.TTCCLayout(包含日志产生的时间、线程、类别等等信息)
软件开发人员可以通过这三大构件,根据日志的类型和优先级进行记录,并且可以在程序运行时去控制日志信息输出的格式和往什么地方输出(控制台、日志文件)。
Log4J 使用示例
下面是一个在 Web 应用中使用 Log4J 的简单例子。
第 1 步:修改 Web 应用的 web.xml 文件
在 Web 应用的 web.xml 中指明 Log4J 的配置文件名称。
代码 1. 在 web.xml 中配置 Log4J
……
<servlet>
<servlet-name>log4j-init</servlet-name>
<servlet-class>is.dsw.common.base.log4jInit</servlet-class>
<init-param>
<!—下面的初始化参数指定 log4j 的配置文件为 log4j.properties -->
<param-name>log4j</param-name>
<param-value>/WEB-INF/log4j.properties</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet>
<servlet-name>log4jServlet</servlet-name>
<servlet-class>is.dsw.common.base.log4jServlet</servlet-class>
<load-on-startup>0</load-on-startup>
</servlet>
……
|
第 2 步:对 Log4J 进行配置
我们看到,在上面的配置中指定了 Log4J 的配置文件名为 log4j.properties。在这个文件中,我们可以通过对前文所述的 Log4J 的三大控件进行配置:
代码 2. log4j.properties 配置文件
#此项指定 log4j 本身不输出调试信息
log4j.debug=false
# 设置记录器(logger)的输出信息的级别,并指定信息源appender,此例中,输出到JADEA and A1.
log4j.rootCategory=DEBUG, OPAL, A1
……
#信息源appender为每天产生一个日志文件
log4j.appender.OPAL= org.apache.log4j.DailyRollingFileAppender
#日志格式为灵活布局模式
log4j.appender.OPAL.layout=org.apache.log4j.PatternLayout
#指定灵活布局模式下日志的格式
#%c 输出所属类的全名
#%d 输出日志时间其格式为 可指定格式 如 %d{HH:mm:ss}等
#%n 换行符
#%m 输出代码指定信息,如info(“message”),输出message
#%p 输出日志的优先级,即 FATAL ,ERROR,INFO 等
log4j.appender.OPAL.layout.ConversionPattern=%d %p %c - %m%n
|
第 3 步:在 Web 应用的 Java 代码中使用 Log4J
进行完上面两步的配置,我们就可以在 Java 程序中使用 Log4J 进行日志的输出。
首先读取 Log4J 配置信息,初始化 Logger。
代码 3. 初始化 Log4J
public class log4jInit extends HttpServlet {
public void init() {
/*找到在web.xml中指定的log4j.properties文件并读取配置信息*/
String prefix = getServletContext().getRealPath("/");
String file = getInitParameter("log4j");
System.out.println("................log4j start");
if(file != null) {
PropertyConfigurator.configure(prefix+file);
}
}
}
|
然后在 Java 代码中就可以任意地使用 Log4J 进行日志输出。
代码 4. 在 Web 应用的 Java 代码中使用 Log4J 进行日志输出
public class log4jServlet extends HttpServlet {
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws IOException {
Logger logger = Logger.getLogger(log4jServlet.class);
/*输出日志*/
logger.info("Entering doGet@Log4jServlet.");
/*更多的代码和日志输出*/
........
........
logger.info("Exiting doGet@Log4jServlet.");
}
}
|
运行该 Web 应用后,当有客户机访问该 Web 应用时,就会得到应用程序输出的日志信息。下面是以三个并发用户访问该 Web 应用的情况下,从打印出的日志中挑选出的上述相关日志信息:
图 1. 运行 Web 应用后输出的日志
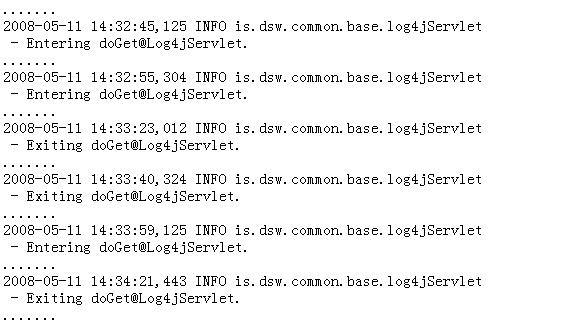
在上面的例子中,我们看到,利用 Log4J 提供的功能,我们很方便地输出了程序的日志,但是同时也看到,这样的日志在多用户并发访问的情况下,特别是应用程序复杂且拥有大量并发访问用户的情况下,根本无法区分哪些日志是属于哪个用户的,这样就使得进行日志分析和用户跟踪变成一件非常困难的事情。
NDC 介绍
NDC(Nested Diagnostic Context)是 Neil Harrison 在名为《Patterns for Logging Diagnostic Messages》的书中提出的嵌套诊断环境的机制。这种机制的提出,主要为了减少多线程的系统为每个客户单独记录日志的系统开销。在过去,区分两个客户的日志输出的常用方法是单独为每个客户机实例化新类别,但该方法会增加类别数量,并增加日志记录的管理开销。Neil Harrison 提出的方法就是把用户的上下文信息放到嵌套式诊断环境 (NDC) 中。
NDC 为每一个线程管理一个堆栈。开发人员可以在代码中合适的位置嵌入简单的 push 和 pop 方法,用来维护堆栈。通常 push 进堆栈的是可以唯一标示客户的上下文信息,如 SessionID 或者客户名称,IP 地址等。因为每个客户请求都会有单独的 NDC 堆栈,因此日志系统在输出的时候会根据每个线程找到对应的堆栈,并在输出日志的时候附加上堆栈内的信息。开发人员就可以很容易的在日志中区分出各个不同客户所产生的日志条目。
Log4J 从 1.2 起开始支持 NDC,org.apache.log4j.NDC 声明如下:
代码 5. NDC 声明代码
public class NDC {
// 返回诊断堆栈的内容
public static String get();
// 从堆栈的顶端删除一个元素
public static String pop();
//在堆栈顶端加入一个元素
public static void push(String message);
//察看这个堆栈最顶层的元素,但不删除它
public static String peek()
// 删除这个线程的堆栈内容
public static void remove();
}
|
要注意的是,org.apache.log4j.NDC 类中所有的方法都是静态的。假设 NDC 日志输出功能被打开,每一次的日志请求,Log4J 组件都会把当前线程的整个 NDC 堆栈内容输出在日志条目中。这样的过程不需要开发人员写过多的代码,程序员只需要在代码中合适的地方通过 push 和 pop 方法将正确的信息放到 NDC 的堆栈中,然后通过修改 Log4J 的配置文件,指定用户标志信息输出的位置和格式,而原来 Java 代码中输出日志的代码不需要任何修改,就能够输出带有用户标志信息的日志。
在前面的 Log4J 使用示例 部分,我们曾经讲过 Log4J 配置文件中相应的配置信息,其中 PatternLayout 的 ConversionPattern 用于程序员指定日志输出的格式。要使用 NDC 的方式输出用户标志信息,只需要在 PatternLayout 的格式定义 ConversionPattern 中使用 %x,就能在相应的位置上输出 NDC 存储的上下文信息。具体的使用方法我们将在后面的 在 Web 应用中添加用户跟踪 部分进行介绍。
MDC介绍
MDC 和 NDC 相似,也可以减少多线程的系统为每个客户单独记录日志的系统开销。它同样是为每个线程建立一个独立的存储空间,开发人员可以根据需要把信息存入其中。不同的是 MDC 使用 Map 的机制来存储信息,信息以 key/value 对的形式存储在 Map 中。
Log4J 从 1.3 alpha 版本开始提供对 MDC 的支持,org.apache.log4j.MDC 声明如下:
代码 6. MDC 声明代码
public class MDC {
// 清空map所有的条目。
public static void clear();
// 根据key值返回相应的对象
public static object get(String key);
//返回所有的key值.
public static Enumeration getKeys();
//把key值和关联的对象,插入map中
public static void put(String key, Object val),
//删除key对应的对象
public static remove(String key)
}
|
MDC 和 NDC 的使用方法也类似,区别只是在 Log4J配置文件中,在通过 PatternLayout 的 ConversionPattern 来配置日志的格式的时候,需要使用 %x{key} 来输出相应的用户标志信息对象。
下面,我们通过具体的例子来说明如何在使用 Log4J 的 Web 应用中增加用户标志信息,达到进行用户跟踪的目的。在开发中,对于使用 NDC 还是 MDC 的机制,要看具体的应用在处理上下文信息的时候,是采用堆栈式的还是 Map 式的方便。下面我们以 NDC 为例进行说明。
在 Web 应用中添加用户跟踪
通常,开发人员会在系统的很多地方设置输出点,输出日志。如果要全面的修改这些输出点使日志条目附加上所需的信息,是一件繁重的工作。我们可以利用 Servlet 的 filter 来简化这项工作。Servlets Filter 是 Servlet 2.3 规范中出现的,它能截取用户从客户端提交的请求,并在请求没有到达真正需要访问的资源前运行一个指定的类。如果我们在这个类中实现 NDC 或 MDC 的功能,就可以大量简化日志修改的工作。下面的清单显示了实现这种修改所需的三个步骤。在这里,我们使用的是 NDC,您也可以使用 MDC 实现相同的功能。
在下面的例子中,介绍如何在前面已有的 Log4J 使用示例 的 Web 应用代码的基础上,通过为 Web 应用的 Servlet 增加一个 filter 的方法,将用户标志信息在 filter 中压入/弹出 NDC 堆栈,而不需要修改任何原来的 Java 程序中的输出日志的代码,使用起来非常简便。
第 1 步:增加一个处理 NDC 堆栈信息的 filter 类
本例通过在 filter 中取得访问该 Web 应用的客户机的IP地址,用以唯一地标识客户。您也可以和实际的应用程序代码相配合,使用更加人性化的方式来唯一标识客户,如取得 Session 中存储的客户名称等。
代码 7. 在 filter 中增加将用户标志信息放入 NDC 堆栈
package is.dsw.base.filter;
import javax.servlet.Filter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpSession;
import org.apache.log4j.NDC;
public class Log4jNdcFilter implements Filter {
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain) throws IOException, ServletException {
// 获得客户的网络地址
String address = request.getRemoteAddr();
// 把网络地址放入NDC中. 那么在在layout pattern 中通过使用 %x,就可在每条日之中增加网络地址的信息.
NDC.push(address);
//继续处理其他的filter链.
chain.doFilter(req, res);
// 从NDC的堆栈中删除网络地址.
NDC.pop();
}
}
|
第 2 步:修改 Web 应用的 web.xml 文件
我们需要修改 Web 应用的 web.xml 文件,对 filter 进行设置。在 <web-app< 元素下面增加下列的代码行:
代码 8. 修改 web.xml 文件,增加 filter 配置
……
<filter>
<filter-name>NdcFilter</filter-name>
<filter-class> is.dsw.base.filter.Log4jNdcFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>NdcFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
……
|
上述 XML 中的 url-pattern 元素与这个 Web 应用中的所有 URL 匹配。如果只想应用于部分 URL,可以相应地调整模式。
第 3 步:修改 Log4J 的配置文件
需要对 Log4J.properties 文件的配置做一些改变,以便看到 NDC 上下文。在 NDC 简介部分,我们曾经说过,%x 表示会在每个日志行上打印当前 NDC 上下文。我们对 Log4J使用示例 中的 Log4J.properties配置文件 进行如下修改,在 PatternLayout 的格式定义 ConversionPattern 中增加 %x, 将 NDC 堆栈中的信息在 %x 指定的位置上进行输出。如下:
代码 9. Log4J 配置文件中修改 PatternLayout 的输出格式
log4j.appender.A1.layout.ConversionPattern=%d %p %c %x - %m%n
|
完成以上修改之后,每一条记录都会把我们在 Filter 中 push 进 NDC 堆栈的内容打印出来。仍然以 Log4J 使用示例 中的三个并发用户访问为例,我们可以得到如下的日志信息,和前面不使用 NDC 的方式下 打印的日志信息相比较,可以看到在原来日志的基础上增加了客户机 IP 地址,这样可以很容易地区分不同的用户的信息,为我们进行日志分析和用户跟踪打下了很好的基础。
图 2. 应用 NDC 之后,运行 Web 应用后输出的日志
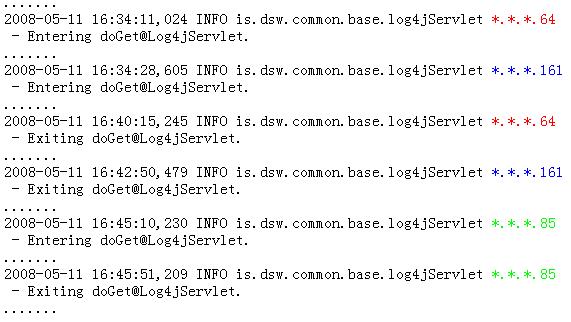
或许以上的描述已经让你了解到如何利用 NDC 和 MDC 的机制来记录某个用户的唯一标示,或者跟踪其他特定于应用的数据。一旦这些用户标示的数据记入日志,则能很容易地利用其他工具将他们抽取出来,如 grep。如果我们自定义一个数据库的 Appenders,把日志信息插入数据库的话,还能很容易的对这些数据进行统计和分析。
结论
Log4J 提供了对 NDC 和 MDC 机制的支持,开发人员可以利用此机制为每条日志记录增加我们需要的内容。本文通过在 servlet 的 filter 中合适的位置应用很少的代码,就可以修改整个应用的日志策略。合理的善用本文所提到的机制,可以节省我们的工作量,也简化程序中日志的维护。最终,客户可以获得更好的网络应用程序,遇到问题也能从技术支持团队得到迅速有效的响应。
值得注意的是,我们并不能保证本文所提出的用户跟踪方案可以完美地解决所有的问题。如果读者希望采用本方案,请参考 Apache Log4J 的文档以了解更多的信息。
回页首
下载
| 描述 | 名字 | 大小 | 下载方法 |
|---|---|---|---|
| 本文用到的 Java 代码示例 | UserTrackWeb.war | 315KB | HTTP |
关于下载方法的信息
参考资料
- Apache Log4J 使用指南 详细介绍了 Apache Log4J 的使用方法。
- Apache Log4J 主页 有大量有关 Apache Log4J 的文章。
- Apache Log4J 的 wiki。
- NDC 定义 可以查看 NDC 的信息。
- MDC 定义 可以查看 MDC 的信息。
- developerWorks Web 开发专区 为 Web 开发人员提供了关于使用 Web 2.0 技术的参考资料。