Windows驱动开发WDM (8)- 内核同步对象
只要写过多线程应用的程序员都知道,多线程访问公共资源的时候需要同步。在用户模式下,经常使用事件,互斥,信号量等对象来控制公共资源的访问。内核模式下,也是有相应的事件,互斥,信号量等内核对象,还有自旋锁。如果不是用同步对象进行控制,那么当多线程访问的时候就会产生一些不可预测的问题了。
不使用同步对象
看下面的代码:
NTSTATUS Encoding(IN PDEVICE_OBJECT fdo, IN PIRP Irp)
{
KdPrint(("Start to Encode\n"));
PIO_STACK_LOCATION stack = IoGetCurrentIrpStackLocation(Irp);
//得到输入缓冲区大小
ULONG cbin = stack->Parameters.DeviceIoControl.InputBufferLength;
//得到输出缓冲区大小
ULONG cbout = stack->Parameters.DeviceIoControl.OutputBufferLength;
//获取输入缓冲区,IRP_MJ_DEVICE_CONTROL的输入都是通过buffered io的方式
char* inBuf = (char*)Irp->AssociatedIrp.SystemBuffer;
//假如需要将数据放到一个公共资源中,然后再进行操作,比如这里是亦或编码,那么就需要考虑同步的问题。
//不然在多线程调用的时候,公共资源的访问将会有不可预测的问题。
PDEVICE_EXTENSION pdx = (PDEVICE_EXTENSION)fdo->DeviceExtension;
RtlCopyMemory(pdx->buffer, inBuf, cbin);
//模拟延时3秒
KdPrint(("Wait 3s\n"));
KEVENT event;
KeInitializeEvent(&event, NotificationEvent, FALSE);
LARGE_INTEGER timeout;
timeout.QuadPart = -3 * 1000 * 1000 * 10;//负数表示从现在开始计数,KeWaitForSingleObject的timeout是100ns为单位的。
KeWaitForSingleObject(&event, Executive, KernelMode, FALSE, &timeout);//等待3秒
for (ULONG i = 0; i < cbin; i++)//将输入缓冲区里面的每个字节和m亦或
{
pdx->buffer[i] = pdx->buffer[i] ^ 'm';
}
//获取输出缓冲区,这里使用了直接方式,见CTL_CODE的定义,使用了METHOD_IN_DIRECT。所以需要通过直接方式获取out buffer
KdPrint(("user address: %x, this address should be same to user mode addess.\n", MmGetMdlVirtualAddress(Irp->MdlAddress)));
//获取内核模式下的地址,这个地址一定> 0x7FFFFFFF,这个地址和上面的用户模式地址对应同一块物理内存
char* outBuf = (char*)MmGetSystemAddressForMdlSafe(Irp->MdlAddress, NormalPagePriority);
ASSERT(cbout >= cbin);
RtlCopyMemory(outBuf, pdx->buffer, cbin);
//完成irp
Irp->IoStatus.Status = STATUS_SUCCESS;
Irp->IoStatus.Information = cbin;
IoCompleteRequest(Irp, IO_NO_INCREMENT);
KdPrint(("Encode thread finished\n"));
return Irp->IoStatus.Status;
}
NTSTATUS HelloWDMIOControl(IN PDEVICE_OBJECT fdo, IN PIRP Irp)
{
KdPrint(("Enter HelloWDMIOControl\n"));
PDEVICE_EXTENSION pdx = (PDEVICE_EXTENSION)fdo->DeviceExtension;
PIO_STACK_LOCATION stack = IoGetCurrentIrpStackLocation(Irp);
//得到IOCTRL码
ULONG code = stack->Parameters.DeviceIoControl.IoControlCode;
NTSTATUS status;
ULONG info = 0;
switch (code)
{
case IOCTL_ENCODE:
{
status = Encoding(fdo, Irp);//调用编码函数
}
break;
default:
status = STATUS_INVALID_VARIANT;
Irp->IoStatus.Status = status;
Irp->IoStatus.Information = info;
IoCompleteRequest(Irp, IO_NO_INCREMENT);
break;
}
KdPrint(("Leave HelloWDMIOControl\n"));
return status;
}
IOCTL_ENCODE的处理函数里面调用了Encoding函数,这里就有个问题,假如caller创建多个线程来调用DeviceIoControl函数,那么Encoding函数就会被并发调用。而Encoding函数里面使用了pdx->buffer这个公共资源,那么当多线程并发的时候势必会出问题。比如这么caller这么调用:
// TestWDMDriver.cpp : Defines the entry point for the console application.
//
#include "stdafx.h"
#include <windows.h>
#include <process.h>
#define DEVICE_NAME L"\\\\.\\HelloWDM"
void Test(void* pParam)
{
//设置overlapped标志,表示异步打开
HANDLE hDevice = CreateFile(DEVICE_NAME,GENERIC_READ | GENERIC_WRITE,0,NULL,OPEN_EXISTING,FILE_ATTRIBUTE_NORMAL,NULL);
if (hDevice != INVALID_HANDLE_VALUE)
{
char inbuf[100] = {0};
sprintf(inbuf, "hello world %d", (int)pParam);
char outbuf[100] = {0};
DWORD dwBytes = 0;
printf("input buffer: %s\n", inbuf);
DWORD dwStart = GetTickCount();
BOOL b = DeviceIoControl(hDevice, CTL_CODE(FILE_DEVICE_UNKNOWN, 0x800, METHOD_IN_DIRECT, FILE_ANY_ACCESS),
inbuf, strlen(inbuf), outbuf, 100, &dwBytes, NULL);
//将输出buffer的数据和'm'亦或,看看是否能够得到初始的字符串。
for (int i = 0; i < strlen(inbuf); i++)
{
outbuf[i] = outbuf[i] ^ 'm';
}
printf("Verify result, outbuf: %s, operated: %d bytes, time used: %d ms\n", outbuf, dwBytes, GetTickCount() - dwStart);
CloseHandle(hDevice);
}
else
printf("CreateFile failed, err: %x\n", GetLastError());
}
int _tmain(int argc, _TCHAR* argv[])
{
HANDLE handles[10];
for (int i = 0; i < 10; i++)
{
handles[i] = (HANDLE)_beginthread(Test, 0, (void*)i);
}
WaitForMultipleObjects(10, handles, TRUE, INFINITE);
return 0;
}
caller创建了10个线程,分别传入hello world 0,hello world 2 ... hellow world 9。看实际输出结果:
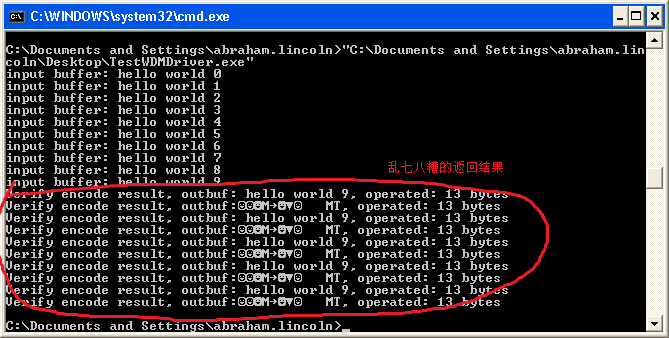
输入字符串正确,但是输出就一塌糊涂了,原因就是驱动内部使用了一个公共资源,从而导致多线程并发的时候出问题。要解决这个问题其实很简单,就是使用同步对象进行控制。
使用同步对象
这里以互斥为例子。使用互斥内核对象需要3个函数:
KeInitializeMutex 初始化互斥对象
KeWaitForSingleObject 等待获取互斥对象,如果互斥对象已经被别的线程获取了,那么这个函数就将等待。
KeReleaseMutex 释放互斥对象。
通常在设备扩展里面会加一个互斥对象,然后在AddDevice函数里面初始化互斥对象。比如:
typedef struct _DEVICE_EXTENSION
{
PDEVICE_OBJECT fdo;
PDEVICE_OBJECT NextStackDevice;
UNICODE_STRING ustrDeviceName; // 设备名
UNICODE_STRING ustrSymLinkName; // 符号链接名
char* buffer;
ULONG filelen;
KMUTEX myMutex;
} DEVICE_EXTENSION, *PDEVICE_EXTENSION;
//创建一个互斥对象 KeInitializeMutex(&pdx->myMutex, 0);
然后在访问公共资源前需要获取互斥对象,访问结束释放互斥对象,比如(红色的代码就是用来控制公共资源的):
NTSTATUS Encoding(IN PDEVICE_OBJECT fdo, IN PIRP Irp)
{
KdPrint(("Start to Encode\n"));
PIO_STACK_LOCATION stack = IoGetCurrentIrpStackLocation(Irp);
//得到输入缓冲区大小
ULONG cbin = stack->Parameters.DeviceIoControl.InputBufferLength;
//得到输出缓冲区大小
ULONG cbout = stack->Parameters.DeviceIoControl.OutputBufferLength;
//获取输入缓冲区,IRP_MJ_DEVICE_CONTROL的输入都是通过buffered io的方式
char* inBuf = (char*)Irp->AssociatedIrp.SystemBuffer;
//假如需要将数据放到一个公共资源中,然后再进行操作,比如这里是亦或编码,那么就需要考虑同步的问题。
//不然在多线程调用的时候,公共资源的访问将会有不可预测的问题。
PDEVICE_EXTENSION pdx = (PDEVICE_EXTENSION)fdo->DeviceExtension;
KeWaitForSingleObject(&pdx->myMutex, Executive, KernelMode, FALSE, NULL);//等待获取mutext
RtlCopyMemory(pdx->buffer, inBuf, cbin);
//模拟延时3秒
KdPrint(("Wait 3s\n"));
KEVENT event;
KeInitializeEvent(&event, NotificationEvent, FALSE);
LARGE_INTEGER timeout;
timeout.QuadPart = -3 * 1000 * 1000 * 10;//负数表示从现在开始计数,KeWaitForSingleObject的timeout是100ns为单位的。
KeWaitForSingleObject(&event, Executive, KernelMode, FALSE, &timeout);//等待3秒
for (ULONG i = 0; i < cbin; i++)//将输入缓冲区里面的每个字节和m亦或
{
pdx->buffer[i] = pdx->buffer[i] ^ 'm';
}
//获取输出缓冲区,这里使用了直接方式,见CTL_CODE的定义,使用了METHOD_IN_DIRECT。所以需要通过直接方式获取out buffer
KdPrint(("user address: %x, this address should be same to user mode addess.\n", MmGetMdlVirtualAddress(Irp->MdlAddress)));
//获取内核模式下的地址,这个地址一定> 0x7FFFFFFF,这个地址和上面的用户模式地址对应同一块物理内存
char* outBuf = (char*)MmGetSystemAddressForMdlSafe(Irp->MdlAddress, NormalPagePriority);
ASSERT(cbout >= cbin);
RtlCopyMemory(outBuf, pdx->buffer, cbin);
KeReleaseMutex(&pdx->myMutex, FALSE);
//完成irp
Irp->IoStatus.Status = STATUS_SUCCESS;
Irp->IoStatus.Information = cbin;
IoCompleteRequest(Irp, IO_NO_INCREMENT);
KdPrint(("Encode thread finished\n"));
return Irp->IoStatus.Status;
}
ok,将pdx->buffer通过互斥量对象给控制起来了,意味着这个资源在某一时刻只能被一个线程拥有并且使用,那么也就不存在并发的问题了。看结果:
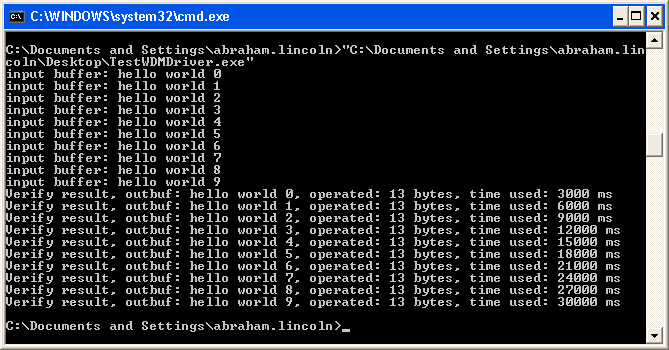
可以正常输出,搞定。
从上面的截图可以看到第一个线程等了3秒,而最后一个线程等了30秒。这是因为驱动的处理函数里面模拟了3秒延时。那3秒延时代码处在mutex中。而mutex相当于将那段代码给串行话运行了(一个线程一个线程的运行)。所有最后一个线程需要等待30秒,10 * 3 = 30.
内核模式下驱动的同步对象是作用于所有调用进程的,比方说有2个测试实例运行,那么20个线程会排队访问pdx->buffer.可以做这么个实验,同时运行2个调用例子,可以看到:
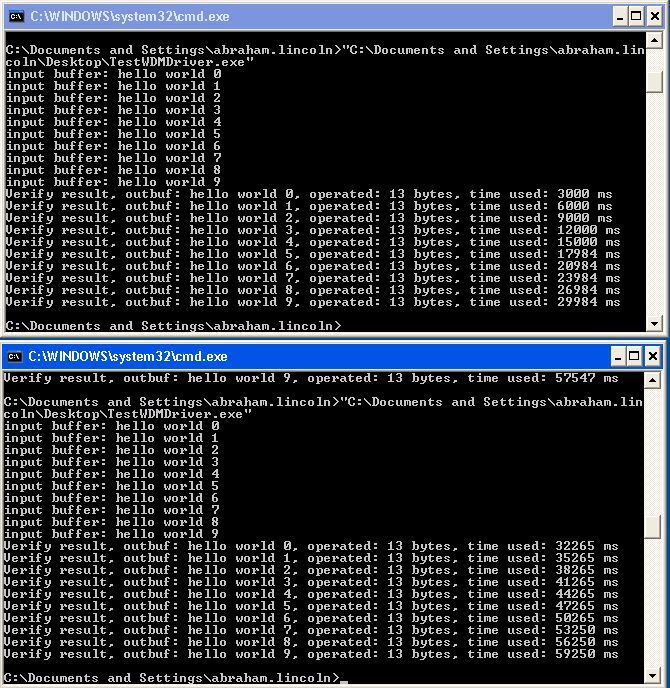
第二个调用例子的第10个线程等待了差不多60秒。
在多线程环境下,同步对象是经常被用到的,内核模式同用户模式一样都需要同步对象。