云计算网络技术
1 TRILL/FabricPath/SPB
首先肯定是传统二层网络有哪些困境或者不给力的地方喽:1 STP阻塞掉一半链路,浪费带宽;2 接入交换机MAC地址表空间会过大;3 为了二层互联而设置的三层网管限制了虚拟机的漂移。
关于MAC地址表详细说明一下:
因为传统的二层交换机是通过学习来建立MAC地址表的。怎么学习呢,接入交换机会利用所有接收到的数据桢的源MAC地址来建立MAC表。由于传统二层MAC地址没有层次化概念,那么所有接收到的数据桢的源地址都会被放入MAC表中,导致一台交换机可能会学习到整个网段内的所有二层地址,即便大部分时间只跟其中一小部分人联系。
但是大二层技术则可以减小MAC地址表空间,比如FabricPath采用的就是“基于会话的MAC地址学习”,即只有那些目的地址为本地设备的数据帧的源地址才会被放入FabricPath/TRILL网关的MAC地址表中,其他数据帧的源地址以及广播帧的源地址都不会被学习。
既然二层网络的主要问题就是缺失了控制平面,只做根据MAC地址查表转发的工作,那么TRILL/FabricPath/SPB的主要功能就是在传统二层网络的基础上引入了控制平面,下面单独详述:
1) FabricPath:新增二层帧头,主要包括三个字段:源SwitchID,目的SwitchID,TTL。其中源/目的SwitchID分别两个字节,用于在节点间寻址;TTL主要用于防环。
2) TRILL:新增TRILL头和MAC头,其中TRILL头也是源RBridgeID,目的RBridgeID和TTL,这与FabricPath基本上完全一致。MAC头主要是方便与现有以太网兼容并存。本质上讲,TRILL与当前IP报文转发过程是完全类似的。
3) SPB:与前两者类似,同样采用IS-IS构建独立的控制平面,新增的二层帧头主要由三部分组成:源MAC,目的MAC和S-VID。其中源/目的MAC与TRILL、FabricPath中的出入网关完全类似,指代了这个大二层网络的起点和终点,只不过在SPB网络中的逐跳转发由类似于隧道标识的S-VID实现。这也正是SPB使用PBB(一种MAC-in-MAC技术)的核心思想所在。
2 虚拟接入与虚拟交换机
2.1 首先是为什么需要虚拟交换机,主要两个原因:1) 服务器虚拟化让一个物理服务器上存在多个虚拟机,那多个虚拟机收发数据都从这个物理服务器的网卡上出入,导致单个操作系统与接入交换机端口间是多对一的关系,原来针对单个端口的策略无法部署;2) 服务器管理和网络管理责权不清,互相推诿。
一句话概括就是目前虚拟机同交换机端口之间没有办法直接对应上。
2.2 那为什么仅用简单的虚拟机交换机vSwtich技术又不够呢?
vSwtich技术其实由来已久了,包括软件VEB,如VMware vShpere内置的vSwitch,VMware分布式统一网络接入平台VDS(Virtual Distributed Switch),与vSphere结合的Cisco Nexus 1000v,开源的Open vSwtich以及硬件的VEB(Virtual Ethernet Bridging)。
但是这些vSwitch也叫VEB存在三个问题:
1) 功能弱。具体说,通常只具有简单的二层转发,缺乏QoS机制和二层安全策略,流量镜像能力差。
2) 功能弱也导致网管人员难以把针对物理端口的策略平滑地迁移到VEB或者vSwtich上来;
3) 由于其管理范围被限制在物理服务器内部,没法在整个数据中心提供针对虚拟机的端到端服务。
因此,就得搞像VN-Tag或者VEPA这种复杂的专门针对DCN的虚拟交换机。
2.3 Cisco VN-Tag
核心思想:VN-Tag的核心思想就是在现有的以太网数据桢的VLAN标识前面(或者源/目的MAC后面)增加一个专用标记字段VN-Tag,这个VN-Tag主要是dvif_id和svif_id一对地址,分别对应于源和目的虚拟机的虚拟网络接口VIF,因此支持VN-Tag的上联交换机就能够区分不同的VIF,识别来自和去往特定虚拟机的流量了,这样就把对虚拟机的网络管理范围从服务器内部转移到上联网络交换机上了。
换句话说,VN-Tag是如何解决2.1中所说的虚拟机无法与交换机端口对应的问题的呢?这样:虽然服务器和上联接入交换机只有一条物理连接,但是交换机可以通过VN-Tag区分不同虚拟机的流量,然后在交换机上生成对应
关键特性:
(1) Port Extender。根据上面的原理,由于虚拟化软件Hypervisor和服务器网卡不再具备寻址功能,而是变成一个单纯的网络桥接通道,因此被VN-Tag称为Port Extender。Port Extender最主要的功能就是加上和去掉VN-Tag标签
(2) 级联。正是由于前面Port Extender的特点,VN-Tag具有级联的特性。即对应的处理交换机controlling switch可以不是与服务器直连的接入交换机,而可以是网络中任意IP可达设备,这样级联的好处是可以把流量拉到高端汇聚甚至核心设备上去进行更加精细、高速的管理
(3) 迁移。由于VN-Tag与虚拟机VIF形成了固定的对应关系,因此不管虚拟机迁移到哪台服务器上去,原来部署在VIF端口上的策略都可以保持不变。
标准化与产业化:
(1) 目前已从IEEE 802.1Qbh改为了IEEE 802.1Br(Bridge Port Extension)
(2) 产品方面,服务器需要Cisco Palo卡或者更高级的Cisco VIC 1280卡,交换机要能识别VN-Tag。
VN-Tag与VN-Link有什么区别(http://www.unifiedcomputingblog.com/2010/01/28/whats-the-difference-between-vn-link-and-vn-tag/)
VN-Link是思科市场推广的技术术语,涵盖范围广,可以指VN-Tag,可以指Polo卡,也可以指交换机上的vEth接口,甚至Nexus1000V。而VN-Tag只是其中一个特定的实现技术。
2.4 HP VEPA
核心思想也是将虚拟机间的交换行为从服务器内部转移到上联交换机。
关键特性:
(1) 发卡弯。其本质是对STP生成树协议的修改,对应的场景就是同一个服务器上不同虚拟机间通信的情形,通过强制反射Reflective Relay实现对传统STP的修改。这也叫做标准版的VEPA,对数据帧没有任何改动。
(2) Q-in-Q。这是增强版的VEPA,其本质是使用VLAN堆叠的Q-in-Q技术(802.1ad),即在传统以太网数据桢VLAN标签之外再加上一个标签,来标识不同虚拟机或者虚拟机组的流量。这个外层标签叫做S-Tag或者S-Channel或者形象地称为通道。在标准版VEPA中,上联交换机只能通过IP或者MAC地址区分不同虚拟机数据,而MAC和IP地址容易被作假和攻击,那么增强版VEPA就用另外一个标签S-Tag来实现更精细的流量管理和隔离。
标准与产业化
标准化石IEEE 802.1Qbg。
产品方面,虽然包括了除cisco和vmware之外的几乎所有厂商,但是目前仍缺少实际产品和案例的支撑,并且增强版VEPA仍然需要更换现有的交换机,因为Q-in-Q功能并不常见,当然也需要服务器网卡的支持。
3 虚拟网卡
虚拟网卡本质上就是前面提到的“虚拟接入”的具体执行中必不可少的一个环节。虽然广义上讲是SR-IOV技术(Single Root I/O Virtulization),具体上你可以理解成为Cisco Palo卡以及后续的VIC1280卡即可。虚拟网卡本质上讲完成两个重要工作:
1 将一个物理以太网卡对虚拟机虚拟化为多个独立的PCIe设备,即在一个PF物理通道上虚拟出多个轻量级的VF虚拟通道,每个对应一个虚拟机,将网络接入直接延伸到虚拟机层面。
2 为了支持前面的虚拟接入,在虚拟网卡上打上VN-Tag标签后再送往上联交换机,最终实现区分不虚拟机的流量,并可以在整个数据中心内部署针对性的隔离和Qos策略。
虚拟通道+虚拟接入=虚拟感知
在前面2虚拟接入和3虚拟通道的基础上,就可以串起来看整个虚拟化的网络环境了。其中,虚拟通道负责解决服务器内部的问题,虚拟接入负责解决服务器外部和整个数据中心范围的问题。
首先,数据包从虚拟机vNIC出来后,利用SR-IOV网卡虚拟化技术(比如Cisco的Polo卡)模拟的独立网络通道,Bypass掉hypervisor直接到达网卡,当然本质上是虚拟网卡(即物理网卡的逻辑分片);第二,虚拟化网卡打上VN-Tag标签后区分不同虚拟机流量;第三,在上联物理交换机上有虚拟接口VIF(Cisco叫做vEth,本质上是物理接口的逻辑分片)与每个VN-Tag对应,也就是和每个虚拟机的流量通道对应,交换机上的VIF就像物理端口一样可以配置各种安全、QoS和访问控制策略。这样就完全打通了,也就虚拟感知了。
虚拟感知的好处有两个:1 虚拟机间安全隔离;2 虚拟机端到端服务质量QoS保障。
关于VIF(或者Cisco的vEth)介绍参见:http://infrastructureadventures.com/tag/vn-tag/
这里补充上华为虚拟网络感知的技术,以作对比:
协议接口:
eSight nCenter通过Radius接口以及NETCONF协议与TOR交换机交互,通过vCenter的API与虚拟机管理平台交互。
其中,NETCONF协议通过标准接口来获取和修改网络设备的配置信息,用于VM上线时,nCenter与TOR交换机的信息交互;
Radius接口具有良好实时性和可靠性,适用于大用户量时服务器端的多线程结构,用于实现nCenter向TOR交换机下发ACL/QoS策略。
拓扑发现:
TOR->物理服务器的物理拓扑发现通过LLDP或者CDP(LLDP可将设备的主要能力、管理地址、接口标识等信息封装到LLDP报文中传递给邻居,邻居将这些信息存入标准MIB库中供查询)
物理服务器->vSwitch->VM的虚拟拓扑则通过调用vCenter的API实现(vCenter可以管理vSwitch)。
虚拟感知:
VM上线->
vCenter通过API通知nCenter->
nCenter向TOR发送VM上线消息->
TOR保存VM的MAC、IP等信息->
nCenter按照业务类型、租户划分策略模板,维护并下发VM所应用的策略模板->
TOR部署与配置ACL/QoS/DHCPSnooping策略
VM下线与之类似,由vCenter通过nCenter,然后nCenter通过TOR删除VM及其策略信息。而VM迁移则是通过原VM下线和新VM上线来完成的。
4 数据中心广域网二层互联:VPLS / OTV
数据中心广域网二层互联的专有名词是DCI(Data Center Interconnect),那么DCI的技术背景是:传统的数据中心广域网互联需要通过三层链路,因此需要NAT网管进行公私网地址转换,无法满足当前新业务的需求。例如:一个集群中的不同节点间通常需要保持心跳信令,而这种信令一般要求通过二层网段传输,如果一个集群的部分节点迁移到另一个数据中心,则心跳信令将被广域网三层网关和链路切断;一个单节点机房虚拟机数量达到上限时,必然要迁移到另外的数据中心,事实上VMware vSpehere平台已经开始支持广域网虚拟机迁移Metro vMotion。
DCI有多种实现方式,比如在两个数据中心间直接拉裸光纤是比较直接但是昂贵的方式,目前主要是VPLS和OTV两类。下面重点从控制平面、数据平面两个方面进行对比分析。
4.1 VPLS
VPLS是公开标准,IETF RFC4761/4762,主流数通厂家的大型路由器均能够部署为VPLS PE设备,并借助于成熟的,可靠的,并且世界上几乎所有运营商骨干网都支持的MPLS技术。
4.1.1 VPLS数据平面
VPLS的数据平面本质上就是任意两个参与VPLS的PE设备之间的直连链路,亦即标签交换路径LSP。
既然是参与VPLS的任意两个PE设备之间都要有LSP,也叫做PE LSP full mesh。
当然,这些PE设备之间是由运营商MPLS核心网络中的P路由器进行连接的,但是P路由器只负责告诉转发VPLS标签数据,并不知道自己转发的数据包是否VPLS数据。
4.1.2 VPLS控制平面
VPLS的控制平面本质上是任意两个参与VPLS的PE设备之间的PW邻居关系,亦即Pseudo Wire。一条PW包含了两个单向的点对点LSP链路。因此,本质上讲,VPLS是一种双重隧道技术:LSP+PW。
VPLS的控制平面本质上就是通过运营商的边缘PE设备近乎完美的模拟和复制了以太网的控制平面,即通过广播方式进行寻址,包括防环的split horizon。
具体来说,PE节点上会为每个本地局域网保存一个VPLS实例,记录了这个局域网内的MAC地址信息表。当PE设备受到一个未知目的MAC地址时,会将这个封包从所有加入这个VPLS实例的端口上广播出去(除了这个封包的入端口)进行MAC地址学习和FIB更新。
4.1.3 VPLS的缺点
正式由于VPLS严格模拟了以太网的行为,因此也带来了如下缺点:
1) 广域网链路上的广播消耗大量带宽。广播、生成树协议、ARP这些在局域网环境下运行问题不大,因为局域网链路带宽充裕,但是在珍贵的广域网租用带宽中,无用的广播自然是越少越好。另外,面向广域网进行MAC地址学习会让PE的FIB地址表空间过大。
2) 其他。VPLS无法与主流三层冗余网关协议HSRP、VRRP联合使用,同一个VPLS实例中无法传输多个VLAN信息,导致企业过于依赖运营商资源,并且配置过于复杂。
4.2 OTV
名字起得很好,跟virtulization挂上了关系,本质上就是一个MAC-in-IP的概念。OTV需要在每个数据中心出口部署一台OTV边缘设备(Edge Device, ED),不同数据中心出口的ED在广域网上虚拟出一个OTV网络进行传输。
由于是Cisco的私有技术,其他厂家没有支持的迹象,只做为Cisco Nexus 7000操作系统的一个特性。
4.2.1 OTV数据平面
OTV数据平面本质上就是OTV边缘设备(Edge Device, ED)之间具有IP可达即可,因为本地以太数据包被打上OTV包头后放在IP报文中进行传输,即相当于UDP包,如下图所示。
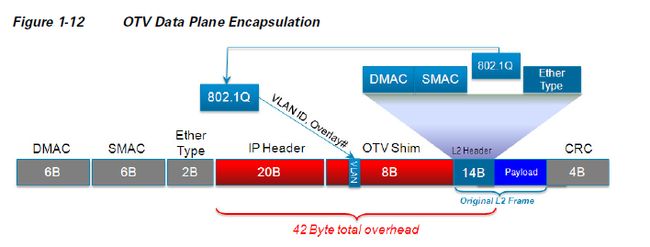
4.2.2 OTV控制平面
OTV控制平面本质上就相当于FabricPath/TRILL的广域网版本,本质上讲就是通过IS-IS来在OTV节点之间进行MAC寻址。OTV节点在建立IS-IS邻居关系后交换MAC地址表,OTV节点在此基础上建立路由表,给出到达每个MAC地址需要通过哪个OTV节点。
此外,OTV将自动屏蔽STP\VTP等二层信令,以及HSRP/VRRP/GLBP等冗余网管三层信令。
5 更大的二层互联:VXLAN
VXLAN全称Virtual eXtensible Local Area Network,虚拟扩展本地网络,是由Cisco、VMware、Broadcom、ARISTA共同向IETF提交的草案。
技术背景
虚拟化的迅猛发展对网络带来了挑战。比如二层边界问题,一方面DCN的二层越大越好,有利于虚拟机的漂移,另一方面二层域过大又带来STP、MAC表项不足等问题;又比如VLAN数量不足的问题。虽然,OTV、TRILL等大二层技术能够有效应对上述挑战,但是那需要新型的网络设备,那VXLAN就想提出一个一劳永逸地方法进行应对。
核心思想
通过引入新的转发实体VTEP(VXLAN Tunnel End Point-虚拟扩展本地网络隧道终结节点)和新的地址封装VNI(VXLAN Network Identifier-虚拟扩展本地网络标识符),所有虚拟机流量在进入VTEP之前被打上新的VNI并封装在UDP数据包中进行跨三层网关的传输,相当于在现有网络上构建起Overlay隧道。
VXLAN封装与数据平面

上图就是VXLAN的数据包格式,
1) 虚拟机发出的数据包首先被VTEP加上VXLAN包头,即24位的VNI,比VLAN的4096个数多出很多;
2) 然后封装在UDP报文中,这样虚拟机本身的MAC和VLAN信息就不作为数据转发的依据了,对外不再可见(就算虚拟机之间建立的是TCP连接,最外面也是用UDP传)
3) IP地址当然也已经不再是VM的地址了,而是隧道两端VTEP的设备三层地址。
当然,VTEP设备位置可以很灵活:
如果VTEP是Hypervisor(如VMWare ESX),那么此IP就是运行虚拟化软件的服务器网卡IP;
如果VTEP是接入交换机,则此IP就是出端口上的IP地址或者三层VLAN SVI地址;
如果VTEP是虚拟交换机如Cisco Nexus1000v,则此IP就是该虚拟交换机的IP地址(这种也是很常见的)
4) 外层MAC头中当然一般是不用VLAN信息了。
VXLAN控制平面
VXLAN使用UDP传输虚拟机间的流量(顺便补一下,TCP是IP protocol 6号,UDP是IP protocol 17号),与OTV类似,VXLAN的控制平面能够在VTEP覆盖网络上维护可行性信息。
本质上讲, VXLAN的控制平面较OTV或者FabricPath简单很多,并没有使用IS-IS作为路由协议,而是沿用了以太网的二层MAC地址学习机制,记录虚拟机、VNI以及VTEP之间的对应关系。举个形象的例子:如果VTEP2接收到IP多播报文后,它将记录内层虚拟机MAC地址与外层VTEP IP地址之间的映射关系,并记录在相同的VXLAN ID的表中。如下图中的第4步:
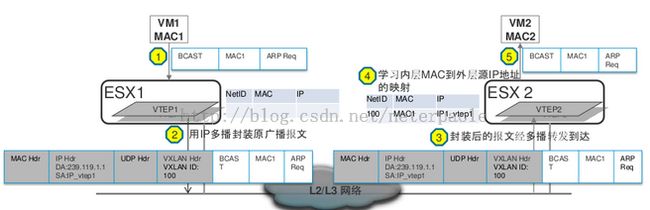
值得一提的是,VXLAN对二层MAC学习的广播行为进行了三层优化,即通过让VTEP加入特定IGMP组播组的方式。
VXLAN OTV LISP 之间的关系
相同点:
技术实现上都引入了新的转发实体:VXLAN(VTEP)、OTV(ED)、LISP(XTR);
都引入了新的数据封包:VXLAN(UDP)、OTV(UDP)、LISP(两层IP包);
都引入了增强型的控制层:VXLAN(二层MAC学习+IP组播)、OTV(利用IS-IS进行MAC地址学习)、LISP(利用基于GRE的BGP学习EID(节点标示符,与路由标识符RLOC对应)可达性信息)
OTV和VXLAN都是采用隧道技术,将一个VLAN横跨三层网关
不同点:
OTV应用场景定位i是数据中心的互连;VXLAN则瞄准的是数据中心内部的自动化部署;LISP则强调的是IP地址的移动性。由于三者解决的定位不同,因此完全可以联合使用,例如:通过VXLAN实现虚拟机在不同数据中心间的漂移;通过OTV搭建数据中心间的二层直连链路;通过LISP应用在广域骨干网。