准确率和召回率(precision&recall)
在机器学习、推荐系统、信息检索、自然语言处理、多媒体视觉等领域,经常会用到准确率(precision)、召回率(recall)、F-measure、F1-score 来评价算法的准确性。
一、准确率和召回率(P&R)
以文本检索为例,先看下图

其中,黑框表示检索域,我们从中检索与目标文本相关性大的项。图中黄色部分(A+B)表示检索域中与目标文本先关性高的项,图中
A+C部分表示你的算法检索出的项。A、B、C的含义图中英文标出。
准确率:
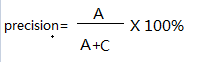
召回率:

一般来说,准确率表示你的算法检索出来的有多少是正确的,召回率表示所有准确的条目中有多少被检索出来。
准确率和召回率的关系
通常,我们希望准确率和召回率均越高越好,但事实上这两者在某些情况下是矛盾的。比如我们只搜出了一个结果,此结果是正确的,求得precisin等于1。但是由于只搜出一个结果,recall值反而很低,接近于0。所以需要综合考量,下面介绍F-measure。
二、F-measure
F-measure又称F-score,其公式为:
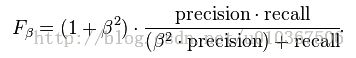
其中F2值,更加注重召回率;F0.5值更加重视准确率。
当beta=1时,就是F1-score:
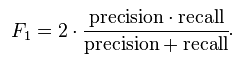
F-measure综合了precision和recall,其值越高,通常表示算法性能越好。
三、Average_precision(AP)
平均正确率(AP):对不同召回率点上的正确率进行平均。
(1)未插值的AP:某个查询Q共有6个相关结果,某系统排序返回的文档中,其中相关文档有5篇,其位置分别是第1,第2,第5,第10,第20位,则AP=(1/1+2/2+3/5+4/10+5/20+0)/6
(2)插值的AP:在召回率分别为0,0.1,0.2,...,1.0的十一个点上的正确率求平均,等价于11点平均。
(3)只对返回的相关文档进行计算的AP,AP=(1/1+2/2+3/5+4/10+5/20)/5,倾向于那些快速返回结果的系统,没有考虑召回率。
AP形式化公式请参考:http://en.wikipedia.org/wiki/Information_retrieval#Average_precision