通常我们在使用数据库时会遇到像数据库连接失败、返回SQL Code818等错误,为了寻找解决方案更是头疼之极。为了方便大家学习,本专题总结了在Oracle、SQL Server、DB2 、Mysql等主要数据库在使用过程中遇到的常见错误,分别举例说明。
十大常见错误
No1--系统篇
Oracle物理结构故障是指构成数据库的各个物理文件损坏而导致的各种数据库故障。这些故障可能是由于硬件故障造成的,也可能是人为误操作而引起。在无硬件问题的前提下我们才能按照下面的处理方发来进一步处理。
-------------------------------------------------------------
Oracle物理结构故障的处理方法:
Oracle物理结构故障是指构成数据库的各个物理文件损坏而导致的各种数据库故障。这些故障可能是由于硬件故障造成的,也可能是人为误操作而引起。所以我们首先要判断问题的起因,如果是硬件故障则首先要解决硬件问题。在无硬件问题的前提下我们才能按照下面的处理方发来进一步处理。
控制文件损坏:
控制文件记录了关于oracle的重要配置信息,如数据库名、字符集名字、各个数据文件、日志文件的位置等等信息。控制文件的损坏,会导致数据库异常关闭。一旦缺少控制文件,数据库也无法启动,这是一种比较严重的错误。
可以通过查询数据库的日志文件来定位损坏了的控制文件。日志文件位于$ORACLE_BASE/admin/bdump/alert_ORCL.ora.
损坏单个控制文件:
1. 确保数据库已经关闭,如果没有用下面的命令来关闭数据库:
svrmgrl>shutdown immediate;
2. 查看初始化文件$ORACLE_BASE/admin/pfile/initORCL.ora,确定所有控制文件的路径。
3. 用操作系统命令将其它正确的控制文件覆盖错误的控制文件。
4. 用下面的命令重新启动数据库
svrmgrl>startup;
5. 用适当的方法进行数据库全备份。
损坏所有的控制文件:
1. 确保数据库已经关闭,如果没有用下面的命令来关闭数据库:
svrmgrl>shutdown immediate;
2. 从相应的备份结果集中恢复最近的控制文件。对于没有采用带库备份的点可以直接从磁带上将最近的控制文件备份恢复到相应目录;对于采用带库备份的点用相应的rman脚本来恢复最近的控制文件。
3. 用下面的命令来创建产生数据库控制文件的脚本:
svrmgrl>startup mount;
svrmgrl>alter database backup controlfile to trace noresetlogs;
4. 修改第三步产生的trace文件,将其中关于创建控制文件的一部分语句拷贝出来并做些修改,使得它能够体现最新的数据库结构。假设产生的sql文件名字为createcontrol.sql.
注意:
Trace文件的具体路径可以在执行完第3)步操作后查看$ORACLE_BASE/admin/bdump/alert_ORCL.ora文件来确定。
5. 用下面命令重新创建控制文件:
svrmgrl>shutdown abort;
svrmgrl>startup nomount;
svrmgrl>@createcontrol.sql;
6. 用适当的方法进行数据库全备份。
重做日志文件损坏:
数据库的所有增、删、改都会记录入重做日志。如果当前激活的重做日志文件损坏,会导致数据库异常关闭。非激活的重做日志最终也会因为日志切换变为激活的重做日志,所以损坏的非激活的重做日志最终也会导致数据库的异常终止。在ipas/mSwitch中每组重做日志只有一个成员,所以在下面的分析中只考虑重做日志组损坏的情况,而不考虑单个重做日志成员损坏的情况。
确定损坏的重做日志的位置及其状态:
1. 如果数据库处于可用状态:
select * from v$logfile;
svrmgrl>select * from v$log;
2. 如果数据库处于已经异常终止:
svrmlgr>startup mount;
svrmgrl>select * from v$logfile;
svrmgrl>select * from v$log;
其中,logfile的状态为INVALID表示这组日志文件出现已经损坏;log状态为Inactive:表示重做日志文件处于非激活状态;Active: 表示重做日志文件处于激活状态;Current:表示是重做日志为当前正在使用的日志文件。
损坏的日志文件处于非激活状态:
1. 删除相应的日志组:
svrmgrl>alter database drop logfile group group_number;
2. 重新创建相应的日志组:
svrmgrl>alter database add log file group group_number (’log_file_descritpion’,…) size log_file_size;
损坏的日志文件处于激活状态且为非当前日志:
1. 清除相应的日志组:
svrmgrl>alter database clear unarchived logfile group group_number;
损坏的日志文件为当前活动日志文件:
用命令清除相应的日志组:
svrmgrl>alter database clear unarchived logfile group group_number;
如果清除失败,则只能做基于时间点的不完全恢复。
打开数据库并且用适当的方法进行数据库全备份:
svrmgrl>alter database open;
部分数据文件损坏:
若损坏的数据文件属于非system表空间,则数据库仍然可以处于打开状态可以进行操作,只是损坏的数据文件不能访问。这时在数据库打开状态下可以单独对损坏的数据文件进行恢复。若是system表空间的数据文件损坏则数据库系统会异常终止。这时数据库只能以Mount方式打开,然后再对数据文件进行恢复。可以通过查看数据库日志文件来判断当前损坏的数据文件到底是否属于system表空间。
非system表空间的数据文件损坏
1. 确定损坏的文件名字:
svrmgrl>select name from v$datafile where status=’INVALID’;
2. 将损坏的数据文件处于offline状态:
svrmgrl>alter database datafile ‘datafile_name’ offline;
3. 从相应的备份结果集中恢复关于这个数据文件的最近的备份。对于没有采用带库备份的点可以直接从磁带上恢复;对于用带库备份的点用相应的rman脚本来恢复。
4. 恢复数据文件:
svrmgrl>alter database recover datafile ‘file_name’;
5. 使数据库文件online:
svrmgrl>alter database datafile ‘datafile_name’ online;
6. 用适当的方法进行数据库全备份。
system表空间的数据文件损坏:
1. 以mount方式启动数据库
svrmgrl>startup mount;
2. 从相应的备份结果集中恢复关于这个数据文件的最近的备份。对于没有采用带库备份的点可以直接从磁带上恢复;对于用带库备份的点用相应的rman脚本来恢复。
3. 恢复system表空间:
svrmgrl>alter database recover datafile ‘datafile_name’;
4. 打开数据库:
svrmgrl>alter database open;
5. 用适当的方法进行数据库全备份。
表空间损坏:
若非system表空间已经损坏,则数据库仍然可以处于打开状态可以进行操作,只是损坏的表空间不能访问。这样在数据库打开状态下可以单独对损坏的表空间进行恢复。若是system表空间损坏则数据库系统会异常终止。这时数据库只能以Mount方式打开,然后再对表空间进行恢复。可以通过查看数据库日志文件来判断当前损坏的表空间是否是system表空间.
非system表空间损坏:
1. 将损坏的表空间处于offline状态:
svrmgrl>alter tablespace ‘tablespace_name’ offline;
2. 从相应的备份结果集中恢复关于这个表空间最近的备份。对于没有采用带库备份的点可以直接从磁带上恢复;对于用带库备份的点用相应的rman脚本来恢复。
3. 恢复表空间:
svrmgrl>alter database recover tablespace ‘tablespace_name’;
4. 使表空间online:
svrmgrl>alter tablespace ‘tablespace_name’ online;
5. 用适当的方法进行数据库全备份.
system表空间损坏:
1. 以mount方式启动数据库
svrmgrl>startup mount;
2. 从相应的备份结果集中恢复system表空间最近的备份。对于没有采用带库备份的点可以直接从磁带上恢复;对于用带库备份的点用相应的rman脚本来恢复。
3. 恢复system表空间:
svrmgrl>alter database recover tablespace system;
4. 打开数据库:
svrmgrl>alter database open;
5. 用适当的方法进行数据库全备份。
整个数据库的所有文件损坏:
整个数据库所有文件的损坏一般是在共享磁盘阵列发生无法恢复的灾难时才发生,这种情况下只能对数据库进行恢复。若数据库的归档目录也已经丢失,则数据库不可能做完全恢复,会有用户数据的丢失。
没采用带库备份的现场:
1. 将最近的备份从磁带上把各个文件解包到相应的目录下。
2. 以mount方式打开数据库:
svrmgrl>startup mount;
3. 恢复数据库:
svrmgrl>recover database until cancel;
4. 打开数据库:
svrmgrl>alter database open resetlogs;
5. 用适当的方法进行数据库全备份。
采用带库备份的现场:
1. 以nomount方式打开数据库:
svrmgrl>startup nomount;
2. 通过相应的rman脚本进行数据库软恢复。
$rman cmdfile=hot_database_restore.rcv
3. 打开数据库:
svrmgrl>alter database open resetlogs;
4. 用适当的方法进行数据库全备份。
存在最近的数据库完整冷备份前提下的一些经典紧急情况的处理:
数据文件,归档重作日志和控制文件同时丢失或损坏:
无新增archives 时的状况:
条件和假设:自上次镜像备份以来尚未生成新的archive log(s); Archivelog Mode; 有同步的datafile(s) 和control file(s) 的镜像(冷)拷贝
恢复步骤:
1. 将镜像拷贝的datafile(s) 和control file(s) 抄送回原始地点:
$ cp /backup/good_one.dbf /orig_loc/bad_one.dbf
$ cp /backup/control1.ctl /disk1/control1.ctl
2. 以mount 选项启动数据库:
$ svrmgrl
svrmgrl> connect internal
svrmgrl> startup mount
3. 以旧的control file 来恢复数据库:
svrmgrl> recover database using backup controlfile until cancel;
*** 介质恢复完成
(必须马上cancel )
4. Reset the logfiles (对启动而言不可省略):
svrmgrl> alter database open resetlogs;
5. 关闭数据库并做一次全库冷备份。
新增archives 时的状况:
条件和假设:自上次镜像备份以来已经生成新的archive log(s); Archivelog Mode; 有同步的datafile(s) 和control file(s) 的镜像(冷)拷贝;archive log(s) 可用。
恢复步骤:
1. 如果数据库尚未关闭,则首先把它关闭:
$ svrmgrl
svrmgrl> connect internal
svrmgrl> shutdown abort
2. 将备份文件抄送回原始地点:
所有Database Files
所有Control Files(没有archive(s) 或redo(s) 的情况下,control files 的更新无任何意义)
所有On-Line Redo Logs (Not archives)
init.ora file(选项)
3. 启动数据库:
$ svrmgrl
svrmgrl> connect internal
svrmgrl> startup
数据文件, 重作日志和控制文件同时丢失或损坏:
条件和假设:Archivelog Mode; 有同步的所有所失文件的镜像(冷)拷贝;archive log(s) 可用
恢复步骤(必须采用不完全恢复的手法):
1. 如果数据库尚未关闭,则首先把它关闭:
$ svrmgrl
svrmgrl> connect internal
svrmgrl> shutdown abort
2. 将备份文件抄送回原始地点:
所有Database Files
所有Control Files
所有On-Line Redo Logs(Not archives)
init.ora file(选项)
3. 启动数据库然而并不打开:
svrmgrl>startup mount
4. 做不完全数据库恢复,应用所有从上次镜像(冷)备份始积累起来的archives:
svrmgrl> recover database until cancel using backup controlfile;
......
......
cancel
5. Reset the logfiles (对启动而言不可省略):
svrmgrl> alter database open resetlogs;
6. 关闭数据库并做一次全库冷备份。
数据文件和控制文件同时丢失或损坏:
条件和假设:Archivelog Mode; 有同步的datafile(s) 和control file(s) 的冷拷贝;archive log(s) 可用
恢复步骤:
1. 将冷拷贝的datafiles(s) 和control file(s) 抄送回原始地点:
$ cp /backup/good_one.dbf /orig_loc/bad_one.dbf
$ cp /backup/control1.ctl /disk1/control1.ctl
2. 以mount 选项启动数据库:
$ svrmgrl
svrmgrl> connect internal
svrmgrl> startup mount
3. 以旧的control file 来恢复数据库:
svrmgrl> recover database until cancel using backup controlfile;
*** 介质恢复完成
(须在应用完最后一个archive log 后cancel )
4. Reset the logfiles (对启动而言不可省略):
svrmgrl> alter database open resetlogs;
重作日志和控制文件同时丢失或损坏时:
条件和假设:Control Files 全部丢失或损坏;Archivelog Mode; 有Control Files 的镜像(冷)拷贝
恢复步骤:
1. 如果数据库尚未关闭,则首先把它关闭:
$ svrmgrl
svrmgrl> connect internal
svrmgrl> shutdown abort
svrmgrl>exit
2. 以Control File 的镜像(冷)拷贝覆盖损坏了的Control File:
$ cp /backup/control1.ctl /disk1/control1.ctl
3. 启动数据库然而并不打开:
$ svrmgrl
svrmgrl> connect internal
svrmgrl> startup mount
4. Drop 坏掉的redo log (排除硬件故障):
svrmgrl> alter database drop logfile group 2;
5. 重新创建redo log:
svrmgrl> alter database add logfile group 2 '/orig_loc/log2.dbf' size 10M;
6. 以旧的control file 来恢复数据库:
svrmgrl> recover database until cancel using backup controlfile;
(必须马上cancel )
7. Reset the logfiles (对启动而言不可省略):
svrmgrl> alter database open resetlogs;
8. 关闭数据库并做一次全库冷备份
只发生归档重作日志丢失或损坏时:
根据不同环境和情况,选择下述手段之一:
a. 马上backup 全部datafiles (如果系统采用一般热备份或RMAN 热备份)
b. 马上正常关闭数据库并进行冷备份(如果系统采用冷备份)
c. 冒险前进!不做备份而让数据库接着跑,直等到下一个备份周期再做备份。这是在赌数据库在下一个备份周期到来之前不会有需要恢复的错误发生。
注意:冒险前进的选择:如果发生错误而需要数据库恢复,则最多只能恢复到出问题archive log 之前的操作现场。从另一个角度讲,archive log(s) 出现问题时,数据库若不需要恢复则其本身并没有任何问题。
Oracle逻辑结构故障的处理方法:
逻辑结构的故障一般指由于人为的误操作而导致重要数据丢失的情况。在这种情况下数据库物理结构是完整的也是一致的。对于这种情况采取对原来数据库的全恢复是不合适的,我们一般采用三种方法来恢复用户数据。
采用exp/imp工具来恢复用户数据:
如果丢失的数据存在一个以前用exp命令的备份,则可以才用这种方式。
1. 在数据库内创建一个临时用户:
svrmgrl>create user test_user identified by test;
svrmgrl>grant connect,resource to test_user;
2. 从以前exp命令备份的文件中把丢失数据的表按照用户方式倒入测试用户:
$imp system/manager file=export_file_name tables=(lost_data_table_name…) fromuser=lost_data_table_owner touser=test_user constraint=n;
3. 用相应的DML语句将丢失的数据从测试用户恢复到原用户。
4. 将测试用户删除:
svrmgrl>drop user test_user cascede;
采用logminer来恢复用户数据:
Logminer是oracle提供的一个日志分析工具。它可以根据数据字典对在线联机日志、归档日志进行分析,从而可以获得数据库的各种DML操作的历史记录以及各种DML操作的回退信息。根据这些用户就可以将由于误操作而丢失的数据重新加入数据库内。
1. 确认数据库的utl_file_dir参数已经设置,如果没有则需要把这个参数加入oracle的初始化参数文件,然后重新启动数据库。下面例子中假设utl_file_dir=’/opt/oracle/db01’;
2. 创建logminer所需要的数据字典信息,假设生成的数据字典文本文件为dict.ora:
svrmgrl>execute dbms_logmnr_d.build(dictionary_filename=>'dict.ora', dictionary_location=>'/opt/oracle/db01’);
3. 确定所需要分析的日志或者归档日志的范围。这可以根据用户误操作的时间来确定大概的日志范围。假设用户误操作时可能的日志文件为/opt/oracle/db02/oradata/ORCL/redo3.log和归档日志’/opt/oracle/arch/orcl/orclarc_1_113.ora’。
4. 创建要分析的日志文件列表,按日志文件的先后顺序依次加入:
svrmgrl>execute dbms_logmnr.add_logfile(logfilename=>’/opt/oracle/arch/orcl/orclarc_1_113.ora’,options=>dbms_logmnr.NEW);
svrmgrl> execute dbms_logmnr.add_logfile(logfilename=>’ /opt/oracle/db02/oradata/ORCL/redo3.log’,options=>dbms_logmnr.ADDFILE);
5. 开始日志分析,假设需要分析的时间在’2003-06-28 12:00:00’和’2003-06-28 13:00:00’之间:
svrmgrl>execute dbms_logmnr.start_logmnr(dictfilename=>’ /opt/oracle/db01/dict.ora’,starttime=>to_date(’ 2003-06-28 12:00:00’,’YYYY-MM-DD HH:MI:SS’),endtime=>to_date(to_date(‘2003-06-28 13:00:00’,’YYYY-MM-DD HH:MI:SS’));
6. 获取分析结果:
svrmgrl>select operation,sql_redo,sql_undo from v$logmnr_contents;
7. 根据分析结果修复数据。
8.结束logmnr:
svrmgrl>dbms_logmnr.end_logmnr;
9. 用适当的方法对原数据库进行数据库全备份。
利用备份恢复用户数据:
采用这种方法时并不是在原数据库进行恢复,而是利用数据库备份在新的机器上重新建立一个新的数据库。通过备份恢复在新机器上将数据库恢复到用户误操作前,这样就可以获得丢失的数据将其恢复到原数据库。
1. 在新的机器上安装数据库软件。
2. 对于采用带库备份的现场,需要在新的数据库服务器上安装调试相应的备份管软件。
3. 根据用户误操作的时间点进行基于时间点的数据库恢复操作。对于没有采用带库备份的现场,可以选取用户误操作前最近的备份磁带进行恢复;对于才用带库备份的点可以通过基于时间恢复点恢复的rman脚本来进行恢复。
4.重新打开数据库:
svrmgrl>alter database open resetlogs;
5. 从新的数据库中获取丢失的用户数据,通过DML操作将其恢复到原数据库中。
6. 用适当的方法对原数据库进行数据库全备份。
--------------------------------------------------------
No2--CPU消耗
经常看见有人问,MSSQL占用了太多的内存,而且还不断的增长; 或者说已经设置了使用内存,可是它没有用到那么多,这是怎么一回事儿呢?我们来看看MSSQL是怎样使用内存的。
----------------------------------------------------------------------------------
SQL Server最大的开销一般是用于数据缓存,如果内存足够,它会把用过的数据和觉得你会用到的数据统统扔到内存中,直到内存不足的时候,才把命中率低的数据给清掉……
经常看见有人问,MSSQL占用了太多的内存,而且还不断的增长;或者说已经设置了使用内存,可是它没有用到那么多,这是怎么一回事儿呢?
首先,我们来看看MSSQL是怎样使用内存的。
最大的开销一般是用于数据缓存,如果内存足够,它会把用过的数据和觉得你会用到的数据统统扔到内存中,直到内存不足的时候,才把命中率低的数据给清掉。所以一般我们在看statistics io的时候,看到的physics read都是0。
其次就是查询的开销,一般地说,hash join是会带来比较大的内存开销的,而merge join和nested loop的开销比较小,还有排序和中间表、游标也是会有比较大的开销的。
所以用于关联和排序的列上一般需要有索引。
再其次就是对执行计划、系统数据的存储,这些都是比较小的。
我们先来看数据缓存对性能的影响,如果系统中没有其它应用程序来争夺内存,数据缓存一般是越多越好,甚至有些时候我们会强行把一些数据pin在高速缓存中。但是如果有其它应用程序,虽然在需要的时候MSSQL会释放内存,但是线程切换、IO等待这些工作也是需要时间的,所以就会造成性能的降低。这样我们就必须设置MSSQL的最大内存使用。可以在SQL Server 属性(内存选项卡)中找到配置最大使用内存的地方,或者也可以使用sp_configure来完成。如果没有其它应用程序,那么就不要限制MSSQL对内存的使用。
然后来看查询的开销,这个开销显然是越低越好,因为我们不能从中得到好处,相反,使用了越多的内存多半意味着查询速度的降低。所以我们一般要避免中间表和游标的使用,在经常作关联和排序的列上建立索引。
------------------------------------------------------------------------------------
No3--拒绝访问
本文介绍了java语言中通过JDBC访问Oracle数据库时出现的2个异常,通过详细分析给出相应解决方案。
------------------------------------------------------------------------------------
| 发布时间:2007.10.31 09:10 来源:赛迪网技术社区 作者:baocl |
|
1. 连接非常慢, 连接成功后执行select操作出现异常: Exception in thread "main" java.sql.SQLException: ORA-00600: 内部错误代码,参数: [ttcgcshnd-1], [0], [], [], [], [], [], []
解决: 使用oracle安装目录下的jdbc/lib/classes12.jar后正常.
2. 使用PreparedStatement的setString(i, s)时出现:
可以参考帖子:http://community.csdn.net/Expert/topic/3936/3936672.xml?temp=.2879145 java.sql.SQLException: 数据大小超出此类型的最大值: 3000
后面那个值大小不定, 感觉与s大小有关
表结构 create table test( name char(32), addr varchar(3000) //varchar2也一样 ) 解决办法: 采用setCharacterStream --------------------------------------------------------------------------------
import java.sql.*;
import java.io.*;
import java.util.*;
/**
* oracle测试
* @author kingfish
* @version 1.0
*/
public class TestOra {
public static void testORACLE() {
String url = "jdbc:oracle:thin:@localhost:1521:oradb";
String username = "system";
String password = "manager"; Connection conn = null;
try {
Class.forName("oracle.jdbc.driver.OracleDriver");
conn = DriverManager.getConnection(url, username, password);
}
catch (Exception e) {
e.printStackTrace();
return;
} char[] carray = new char[1000];
Arrays.fill(carray, ′我′);
String s = new String(carray);
try {
PreparedStatement pst = conn.prepareStatement(
"insert into test(name,addr) values(?,?)");
pst.setString(1, "kingfish"); pst.setCharacterStream(2,
new InputStreamReader(new ByteArrayInputStream(s.
getBytes())), s.length()); //pst.setString(2,s); //用此句则异常
pst.execute(); Statement st = conn.createStatement();
ResultSet r = st.executeQuery("SELECT * from test"); while (r.next()) {
s = r.getString(2);
System.out.println("len=" + s.length());
System.out.println("value=" + s);
} r.close();
st.close();
conn.close();
}
catch (Exception e) {
e.printStackTrace();
}
} /**
* 测试
* @param args String[]
*/
public static void main(String[] args) {
testORACLE();
}
} |
------------------------------------------------------------------------------------
No4--SQL语句
有些朋友看到这个标题可能会有疑问,难道在视图中使用*符号还有何要注意的地方吗?对于这个问题,我们先不必回答,先看一下例子吧。
------------------------------------------------------------------------------------
有些朋友看到这个标题可能会有疑问,难道在视图中使用*符号还有何要注意的地方吗?对于这个问题,我们先不必回答,先看一下例子吧。
我这里,使用的数据库是SqlServer2000自带的Northwind,这样方便大家自己私下里测试。首先,创建两个视图,视图的脚本如下:
![]() --视图 vCustomersA
--视图 vCustomersA
![]() create view
vCustomersA
create view
vCustomersA
![]() as
as
![]() select
CustomerID ,CompanyName,ContactName,ContactTitle,
select
CustomerID ,CompanyName,ContactName,ContactTitle,
![]() Address,City,Region,PostalCode,Country,Phone,Fax
Address,City,Region,PostalCode,Country,Phone,Fax
![]() from
dbo.Customers
from
dbo.Customers
![]() go
go
![]() --视图 vCustomersB
--视图 vCustomersB
![]() create view
vCustomersB
create view
vCustomersB
![]() as
as
![]() select * from
vCustomersA
select * from
vCustomersA
![]() go
go
![]()
然后,使用这两个视图查询客户ID为ALFKI的资料,查询语句如下:
![]() select * from vCustomersA where CustomerID = 'ALFKI'
select * from vCustomersA where CustomerID = 'ALFKI'
![]() select * from vCustomersB where CustomerID = 'ALFKI'
select * from vCustomersB where CustomerID = 'ALFKI'
![]()
查询的结果如下:

这个时候,当我们再次使用视图vCustomersB查询客户ID为ALFKI的资料的时候,错误已经悄然来临,你注意到了吗?让我们来看一下这两个视图的查询结果吧,查询语句如下:
查询的结果如下图:

------------------------------------------------------------------------------------
No5--日志错误
数据库响应缓慢,应用请求无法返回,业务操作陷于停顿,此时需要DBA介入并进行问题诊断及故障处理。 本文对IO状况、DBWR进程等日志文件进行详细分析。
------------------------------------------------------------------------------------
数据库版本:8.1.5.0.0
数据库症状:数据库响应缓慢,应用请求无法返回,业务操作陷于停顿,此时需要DBA介入并进行问题诊断及故障处理。
1. 登录数据库进行检查
首先我们登录数据库,检查故障现象。
经过检查发现,数据块的所有重做日志组除current外都处于active状态:
oracle:/oracle/oracle8>sqlplus "/ as sysdba"SQL*Plus: Release 8.1.5.0.0 - Production on Thu Jun 23 18:56:06 2005(c) Copyright 1999 Oracle Corporation. All rights reserved.Connected to:Oracle8i Enterprise Edition Release 8.1.5.0.0 - ProductionWith the Partitioning and Java optionsPL/SQL Release 8.1.5.0.0 - ProductionSQL> select * from v$log; GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIM---------- ---------- ---------- ---------- ---------- --- ---------------- ------------- --------- 1 1 520403 31457280 1 NO ACTIVE 1.3861E+10 23-JUN-05 2 1 520404 31457280 1 NO ACTIVE 1.3861E+10 23-JUN-05 3 1 520405 31457280 1 NO ACTIVE 1.3861E+10 23-JUN-05 4 1 520406 31457280 1 NO CURRENT 1.3861E+10 23-JUN-05 5 1 520398 31457280 1 NO ACTIVE 1.3860E+10 23-JUN-05 6 1 520399 31457280 1 NO ACTIVE 1.3860E+10 23-JUN-05 7 1 520400 104857600 1 NO ACTIVE 1.3860E+10 23-JUN-05 8 1 520401 104857600 1 NO ACTIVE 1.3860E+10 23-JUN-05 9 1 520402 104857600 1 NO ACTIVE 1.3861E+10 23-JUN-059 rows selected.SQL> / GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIM---------- ---------- ---------- ---------- ---------- --- ---------------- ------------- --------- 1 1 520403 31457280 1 NO ACTIVE 1.3861E+10 23-JUN-05 2 1 520404 31457280 1 NO ACTIVE 1.3861E+10 23-JUN-05 3 1 520405 31457280 1 NO ACTIVE 1.3861E+10 23-JUN-05 4 1 520406 31457280 1 NO CURRENT 1.3861E+10 23-JUN-05 5 1 520398 31457280 1 NO ACTIVE 1.3860E+10 23-JUN-05 6 1 520399 31457280 1 NO ACTIVE 1.3860E+10 23-JUN-05 7 1 520400 104857600 1 NO ACTIVE 1.3860E+10 23-JUN-05 8 1 520401 104857600 1 NO ACTIVE 1.3860E+10 23-JUN-05 9 1 520402 104857600 1 NO ACTIVE 1.3861E+10 23-JUN-059 rows selected.
我们知道,当数据库发生日志切换时(Log Switch),Oracle会触发一个检查点(Checkpoint),检查点进程(Checkpoint Process,CKPT)会通知DBWR(Database?Writer)进程去执行写操作。在日志文件所保护的处于Buffer cache中的脏数据(dirty buffer)未写回磁盘之前,日志文件不能被覆盖或重用。
如果数据库异常繁忙,或者DBWR的写出过慢,就可能出现检查点未完成,Oracle却已经用完所有日志文件的情况。在这种情况下,数据库的日志无法生成,整个数据库将处于停顿状态,此时日志文件中会记录类似如下信息:
Mon Jan 23 16:11:39 2006Thread 1 cannot allocate new log,
sequence 5871Checkpoint not complete Current log# 2 seq# 5870 mem# 0:
+ORADG/danaly/onlinelog/group_2.260.600173851
Current log# 2 seq# 5870 mem# 1:
+ORADG/danaly/onlinelog/group_2.261.600173853
检查v$session_wait视图,我们可以从中看到很多session处于log file switch (checkpoint incomplete) 的等待。
2. 检查DBWR进程
在本案例中,所有日志组都处于active状态,那么显然DBWR的写出存在问题。
接下来让我们检查一下DBWR的繁忙程度:
SQL> !oracle:/oracle/oracle8>ps -ef|grep ora_ oracle 2273 1 0 Mar 31 ? 57:40 ora_smon_hysms02 oracle 2266 1 0 Mar 31 ? 811:42 ora_dbw0_hysms02 oracle 2264 1 16 Mar 31 ? 16999:57 ora_pmon_hysms02 oracle 2268 1 0 Mar 31 ? 1649:07 ora_lgwr_hysms02 oracle 2279 1 0 Mar 31 ? 8:09 ora_snp1_hysms02 oracle 2281 1 0 Mar 31 ? 4:22 ora_snp2_hysms02 oracle 2285 1 0 Mar 31 ? 9:40 ora_snp4_hysms02 oracle 2271 1 0 Mar 31 ? 15:57 ora_ckpt_hysms02 oracle 2283 1 0 Mar 31 ? 5:37 ora_snp3_hysms02 oracle 2277 1 0 Mar 31 ? 5:58 ora_snp0_hysms02 oracle 2289 1 0 Mar 31 ? 0:00 ora_d000_hysms02 oracle 2287 1 0 Mar 31 ? 0:00 ora_s000_hysms02 oracle 2275 1 0 Mar 31 ? 0:04 ora_reco_hysms02 oracle 21023 21012 0 18:52:59 pts/65 0:00 grep ora_
DBWR的进程号是2266。
使用Top命令观察一下该进程的CPU耗用:
oracle:/oracle/oracle8>toplast pid: 21145; load averages: 3.38, 3.45, 3.67 18:53:38725 processes: 711 sleeping, 1 running, 10 zombie, 3 on cpuCPU states: 35.2% idle, 40.1% user, 9.4% kernel, 15.4% iowait, 0.0% swapMemory: 3072M real, 286M free, 3120M swap in use, 1146M swap free PID USERNAME THR PRI NICE SIZE RES STATE TIME CPU COMMAND 11855 smspf 1 59 0 1355M 1321M cpu/0 19:32 16.52% oracle 2264 oracle 1 0 0 1358M 1316M run 283.3H 16.36% oracle 11280 oracle 1 13 0 1356M 1321M sleep 79.8H 0.77% oracle 6957 smspf 15 29 10 63M 14M sleep 107.7H 0.76% java 17393 smspf 1 30 0 1356M 1322M cpu/1 833:05 0.58% oracle 29299 smspf 5 58 0 8688K 5088K sleep 18.5H 0.38% fee_ftp_get 21043 oracle 1 43 0 3264K 2056K cpu/9 0:01 0.31% top 20919 smspf 17 29 10 63M 17M sleep 247:02 0.29% java 25124 smspf 1 58 0 16M 4688K sleep 0:35 0.25% smif_status_rec 8086 smspf 5 23 0 21M 13M sleep 41.1H 0.24% fee_file_in 16009 root 1 35 0 4920K 3160K sleep 0:03 0.21% sshd2 25126 smspf 1 58 0 1355M 1321M sleep 0:26 0.20% oracle 2266 oracle 1 60 0 1357M 1317M sleep 811:42 0.18% oracle 11628 smspf 7 59 0 3440K 2088K sleep 0:39 0.16% sgip_client_ltz 26257 smspf 82 59 0 447M 178M sleep 533:04 0.15% java
我们注意到,2266号进程消耗的CPU不过0.18%,显然并不繁忙,DBWR并不繁忙,但是检查点无法完成,那么我们可以判断,瓶颈就很可能出现在IO上。
3. 检查IO状况
我们可以使用IOSTAT工具检查系统IO状况:
gqgai:/home/gqgai>iostat -xn 3 extended device statistics r/s w/s kr/s kw/s wait actv wsvc_t asvc_t %w %b device...... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 c0t6d0 1.8 38.4 32.4 281.0 0.0 0.7 0.0 16.4 0 29 c0t10d0 1.8 38.4 32.4 281.0 0.0 0.5 0.0 13.5 0 27 c0t11d0 24.8 61.3 1432.4 880.1 0.0 0.5 0.0 5.4 0 26 c1t1d0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 9.1 0 0 hurraysms02:vold(pid238) extended device statistics r/s w/s kr/s kw/s wait actv wsvc_t asvc_t %w %b device........ 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 c0t6d0 0.3 8.3 0.3 47.0 0.0 0.1 0.0 9.2 0 8 c0t10d0 0.0 8.3 0.0 47.0 0.0 0.1 0.0 8.0 0 7 c0t11d0 11.7 65.3 197.2 522.2 0.0 1.6 0.0 20.5 0 100 c1t1d0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 hurraysms02:vold(pid238) extended device statistics r/s w/s kr/s kw/s wait actv wsvc_t asvc_t %w %b device........ 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 c0t6d0 0.3 13.7 2.7 68.2 0.0 0.2 0.0 10.9 0 12 c0t10d0 0.0 13.7 0.0 68.2 0.0 0.1 0.0 9.6 0 11 c0t11d0 11.3 65.3 90.7 522.7 0.0 1.5 0.0 19.5 0 99 c1t1d0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 hurraysms02:vold(pid238) extended device statistics r/s w/s kr/s kw/s wait actv wsvc_t asvc_t %w %b device........ 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 c0t6d0 0.0 8.0 0.0 42.7 0.0 0.1 0.0 9.3 0 7 c0t10d0 0.0 8.0 0.0 42.7 0.0 0.1 0.0 9.1 0 7 c0t11d0 11.0 65.7 978.7 525.3 0.0 1.4 0.0 17.7 0 99 c1t1d0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 hurraysms02:vold(pid238) extended device statistics r/s w/s kr/s kw/s wait actv wsvc_t asvc_t %w %b device........ 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 c0t6d0 0.3 87.7 2.7 433.7 0.0 2.2 0.0 24.9 0 90 c0t10d0 0.0 88.3 0.0 436.5 0.0 1.8 0.0 19.9 0 81 c0t11d0 89.0 54.0 725.4 432.0 0.0 2.1 0.0 14.8 0 100 c1t1d0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 hurraysms02:vold(pid238)
在以上输出中,我们注意到,存放数据库的主要卷c1t1d0的繁忙程度始终处于99~100,而写速度却只有500K/s左右,这个速度是极为缓慢的。
根据IOSTAT的手册:
(%b percent of time the disk is busy (transactions in progress)Kw/s kilobytes written per second)
根据我们的常识,T3盘阵通常按Char写速度可以达到10M/s左右,以前测试过一些Tpcc指标,可以参考:www.eygle.com/unix/Use.Bonnie.To.Test.IO.speed.htm。
而正常情况下的数据库随机写通常都在1~2M左右,显然此时的磁盘已经处于不正常状态,经过确认的确是硬盘发生了损坏,Raid5的Group中损坏了一块硬盘。
经过更换以后系统逐渐恢复正常。
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/xuejinyoulan/archive/2007/11/01/1861485.aspx
------------------------------------------------------------------------------------
No6--存储过程
在 Unix 操作系统下,有时会发生当 DB2 用户使用db2 -td@ -vf 会出现创建失败的现象。本文为您提供解决方案。
------------------------------------------------------------------------------------
问:在 Unix 操作系统下,有时会发生当 DB2 用户使用如:
DB2 -td@ -vf <存储过程创建脚本文件>
创建存储过程失败的情况,而查看 DB2diag.log 文件则发现有类似如下报错信息:
2002-10-05-13.47.40.075759 Instance:DB2inst1 Node:000 PID:1355876(DB2agent (ABC) 0) TID:1 Appid:OC10103F.OD12.017302185202 oper system services sqloChangeFileOwnership Probe:100 Database:ABC errno: 0x0FFFFFFFFFFF7AF0 : 0x00000001 .... PID:1355876 TID:1 Node:000 Title: Path/Filename /home/DB2inst1/sqllib/function/routine/sqlproc/ABC/DB2INST1/tmp/ 2002-10-05-13.47.40.166289 Instance:DB2inst1 Node:000 PID:1355876(DB2agent (ABC) 0) TID:1 Appid:OC10103F.OD12.017302185202 PSM - SQL Procedure psm_ctrl::psm_init_backend Probe:230 Database:ABC DIA8402C A disk error has occurred. ZRC=0x860F0004 PID:1355876 TID:1 Node:000 Title: SQL procedure initialization: 0x09000000031213BC : 696E 7374 616E 6365 206F 776E 6572 2064 instance owner d 0x09000000031213CC : 6F65 7320 6E6F 7420 6265 6C6F 6E67 2074 oes not belong t 0x09000000031213DC : 6F20 6665 6E63 6564 2075 7365 7227 7320 o fenced user's 0x09000000031213EC : 7072 696D 6172 7920 6772 6F75 70 primary group |
答:在 Unix 平台下的 DB2 存储过程对于实例用户和受防护用户之间的关系有一个约束,即 DB2 实例用户必须同时是受防护用户的主组中的一个用户。上述问题的发生就是由于在系统上,实例用户未加入至受防护用户的主组中,从而引发了存取权限不够的问题所导致的,而并非真的发生了如日志中所报的磁盘错误。解决这一问题的方法很简单,只要将实例用户加入该主组即可。但有时用户会发现,即使已将用户加入到指定组,问题仍然存在,这时还应检查一下实例用户所加入的组是否是实例用户所对应的受防护用户的主组,即检查一下加入的组是否正确。
要找到实例用户所应的受防护用户以及受防护用户的主组,可用如下方法:
1. 转入实例用户 Home 路径下的 sqllib/adm 路径
2. 执行命令:ls -l .fenced,会得到类似如下输出:
-r--r--r-- 1 DB2fencj DB2fgrp2 0 Jul 30 09:57 .fenced
3. 输出中表明,该文件所属的用户(DB2fencj)即为受防护用户,所属的组(DB2fgrp2)即为受防护用户的主组
继而,用户便可验证实例用户是否被加入到了正确的组中,如果结果正确,便可以解决上述问题。
------------------------------------------------------------------------------------
No7--游标溢出
前几天一直发现自己的程序在页面多次刷新或者多个人同时访问时,会捕获到“游标超过最大数”的错误。在程序中,没有显示的定义游标,使用时也是类似于在SQL SERVER中一样。
------------------------------------------------------------------------------------
第一次接触ORACLE数据库,感觉和SQL SERVER太多的不同了,光是个自增长值就让我忙活了好长时间。不过今天不是来说这个问题的,且说说我遇到的另一个问题,关于ORACLE提示“游标超过最大数”的错误。
前几天一直发现自己的程序在页面多次刷新或者多个人同时访问时,会捕获到“游标超过最大数”的错误。在程序中,没有显示的定义游标,使用时也是类似于在SQL SERVER中一样。查找一些资料后发现,使用OracleClient.dll连接数据库并用OracleDataReader读取数据时,读取后要即时的将OracleDataReader关闭掉,调用OracleDataReader.Close()方法即可。这一点是以前与Sql Server连接时从没有注意到过的。
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/ludbul/archive/2005/07/04/413535.aspx
------------------------------------------------------------------------------------
No8--备份出错
你的备份做好了吗?检查了吗?删除旧的备份是不是花去你很多时间,特别是在网络条件不好的时候?如果数据库备份文件的传送在某一时刻停止了,你多久才能发现为本文向你详细解决这些问题。
------------------------------------------------------------------------------------
早上看了一个贴子,是一个哥们推广自己一个智能的数据库备份系统,他总结了数据库备份过程中所有可能出错的情况,可以借鉴。
如果你做DBA时间不长,对数据库的备份有些担心,希望能找到一种让你放心的备份方案,那么本文绝对适合你。
关于数据库的备份恢复原理,大家多少都比较熟悉了。但是,你目前做的数据库备份有多可靠?你可以安心睡觉了吗?如果答案是肯定的,那就不用多花时间看下文了,如果觉得还不够安心,总担心数据库哪一天坏了修不好,那么请接着看:
1、我有RAID,还需要做数据库备份吗?需要。有了RAID,万一部份磁盘损坏,可以修复数据库,有的情况下数据库甚至可以继续使用。但是,如果哪一天,你的同事不小心删除了一条重要的记录,怎么办?RAID是无能为力的。你需要合适的备份策略,把那条被误删的数据恢复出来。所以有了RAID,仍需要做备份集群,磁盘镜像同理。
2、如果你只做全备份,那么受限于全备份的大小和备份时间,不可能常做。而且只有全备份,不能将数据库恢复至某个时间点。所以,我们需要全备份+日志备份。比如每天一个全备份,每隔1小时或若干分钟一个日志备份。说到差异备份,因为微软的差异备份记录的是上一次全备份以来发生的变化,所以,如果数据库的改动很频繁的话,没过多久,差异备份就会和全备份的大小接近,因此这种情况下就不合适了。因此,全备份+日志备份的方案适合绝大多数的用户。
3、如果你仅在数据库本地做备份,万一磁盘损坏,或者整个服务器硬件损坏,备份也就没了,就没法恢复数据库。因此,你需要把备份文件传送至另一个物理硬件上。大多数用户不用磁带机,因此不考虑。一般,我们需要另一台廉价的服务器或者PC来存放数据库的备份,来防止硬件损坏造成的备份丢失。
4、你可以在数据库服务器本地做完备份,然后使用某些方式将备份文件传送至备机。你是在备份完成后就马上穿送的吗?其实可以考虑将传送备份的脚本用T-SQL语句来写。
5、备份文件传送至备机后,就可以高枕无忧了吗?不。作为DBA的你还需要检查备机上的备份文件是否能将数据库恢复至最新,如果采用日志备份,会不会因为丢失某一个日志备份文件而导致数据库不能恢复至最新?如何检查日志备份文件之间存在断档?
6、为了将数据库尽可能的恢复到最新,你可能会每隔10分钟(甚至1分钟)执行一次日志备份,那么万一数据库坏了,在恢复的时候,手动恢复成百上千个日志文件,是不是不太现实?
7、如果你所在公司有很多的数据库服务器(就像我所在的公司),而且磁盘空间有限,那么你不得不经常登录服务器来删除旧的备份文件,如果哪天忘了,或者五一十一长假,磁盘空间用完了,就麻烦了。
8、数据库在备份的时候,并不会检查数据页面的完整性,如果数据页坏了,备份作业仍会执行,而且不会报错,等到你发现数据页有错误的时候,你也很可能已经因为磁盘空间不足,而删除了早期的备份,而此时剩下的那些备份可能都是包含损坏的数据页,如果损坏的数据页是某个表的表头的话,那这个表你就再也没办法恢复了。
9、所以你需要定期执行DBCC检查,来尽早发现数据库页面的完整性。在未作完DBCC检查之前,你不能删除旧的备份,以防止新的备份存在问题。所以,删除备份文件的工作变的有些麻烦。
10、你可能知道SQL Server提供了数据库维护计划。没错,使用它可以定期做备份,执行DBCC检查,但这一切仅限于本机操作。为了使数据库可靠,你还是需要自己把本地备份传送至备机。
综上,你的备份做好了吗?检查了吗?删除旧的备份是不是花去你很多时间,特别是在网络条件不好的时候?如果数据库备份文件的传送在某一时刻停止了,你多久才能发现?公司值晚班的同事有权限检查数据库的备份情况吗?
------------------------------------------------------------------------------------
No9--连接错误
一般而言,有以下两种连接 SQL Server 的方式,一是利用 SQL Server 自带的客户端工具;二是利用用户自己开发的客户端程序,客户端程序中又是利用 ODBC 或者 OLE DB 等连接 SQL Server。下面,我们将就这两种连接方式,具体谈谈如何来解决连接失败的问题
------------------------------------------------------------------------------------
在使用SQL Server 的过程中,用户遇到的最多的问题莫过于连接失败了。一般而言,有以下两种连接 SQL Server 的方式,一是利用 SQL Server 自带的客户端工具,如企业管理器、查询分析器、事务探查器等;二是利用用户自己开发的客户端程序,如ASP 脚本、VB程序等,客户端程序中又是利用 ODBC 或者 OLE DB 等连接 SQL Server。下面,我们将就这两种连接方式,具体谈谈如何来解决连接失败的问题。
一、客户端工具连接失败
在使用 SQL Server 自带的客户端工具(以企业管理器为例)连接 SQL Server时,最常见的错误有如下一些:
1、SQL Server 不存在或访问被拒绝
ConnectionOpen (Connect())
2、用户'sa'登录失败。原因:未与信任 SQL Server 连接相关联。
3、超时已过期。
下面我们依次介绍如何来解决这三个最常见的连接错误。
第一个错误"SQL Server 不存在或访问被拒绝"通常是最复杂的,错误发生的原因比较多,需要检查的方面也比较多。一般说来,有以下几种可能性:
1、SQL Server名称或IP地址拼写有误;
2、服务器端网络配置有误;
3、客户端网络配置有误。
要解决这个问题,我们一般要遵循以下的步骤来一步步找出导致错误的原因。
首先,检查网络物理连接:
ping <服务器IP地址>
或者
ping <服务器名称>
如果 ping <服务器IP地址> 失败,说明物理连接有问题,这时候要检查硬件设备,如网卡、HUB、路由器等。还有一种可能是由于客户端和服务器之间安装有防火墙软件造成的,比如 ISA Server。防火墙软件可能会屏蔽对 ping、telnet 等的响应,因此在检查连接问题的时候,我们要先把防火墙软件暂时关闭,或者打开所有被封闭的端口。
如果ping <服务器IP地址> 成功而 ping <服务器名称> 失败,则说明名字解析有问题,这时候要检查 DNS 服务是否正常。有时候客户端和服务器不在同一个局域网里面,这时候很可能无法直接使用服务器名称来标识该服务器,这时候我们可以使用HOSTS文件来进行名字解析,具体的方法是:
1、使用记事本打开HOSTS文件(一般情况下位于C:/WINNT/system32/drivers/etc).
2、添加一条IP地址与服务器名称的对应记录,如:
172.168.10.24 myserver
也可以在 SQL Server 的客户端网络实用工具里面进行配置,后面会有详细说明。
其次,使用 telnet 命令检查SQL Server服务器工作状态:
telnet <服务器IP地址> 1433
如果命令执行成功,可以看到屏幕一闪之后光标在左上角不停闪动,这说明 SQL Server 服务器工作正常,并且正在监听1433端口的 TCP/IP 连接;如果命令返回"无法打开连接"的错误信息,则说明服务器端没有启动 SQL Server 服务,也可能服务器端没启用 TCP/IP 协议,或者服务器端没有在 SQL Server 默认的端口1433上监听。
接着,我们要到服务器上检查服务器端的网络配置,检查是否启用了命名管道,是否启用了 TCP/IP 协议等等。我们可以利用 SQL Server 自带的服务器网络使用工具来进行检查。
点击:程序 -> Microsoft SQL Server -> 服务器网络使用工具,打开该工具后看到的画面如下图所示:
从这里我们可以看到服务器启用了哪些协议。一般而言,我们启用命名管道以及 TCP/IP 协议。
点中 TCP/IP 协议,选择"属性",我们可以来检查 SQK Server 服务默认端口的设置,如下图所示:
一般而言,我们使用 SQL Server 默认的1433端口。如果选中"隐藏服务器",则意味着客户端无法通过枚举服务器来看到这台服务器,起到了保护的作用,但不影响连接。
检查完了服务器端的网络配置,接下来我们要到客户端检查客户端的网络配置。我们同样可以利用 SQL Server 自带的客户端网络使用工具来进行检查,所不同的是这次是在客户端来运行这个工具。
点击:程序 -> Microsoft SQL Server -> 客户端网络使用工具, 打开该工具后看到的画面如下图所示:
从这里我们可以看到客户端启用了哪些协议。一般而言,我们同样需要启用命名管道以及 TCP/IP 协议。
点击 TCP/IP 协议,选择"属性",可以检查客户端默认连接端口的设置,如下图所示。
该端口必须与服务器一致。
单击"别名"选项卡,还可以为服务器配置别名。服务器的别名是用来连接的名称,连接参数中的服务器是真正的服务器名称,两者可以相同或不同。如下图中,我们可以使用myserver来代替真正的服务器名称sql2kcn-02,并且使用网络库 Named Pipes。别名的设置与使用HOSTS文件有相似之处。
通过以上几个方面的检查,错误 1 发生的原因基本上可以被排除。下面我们再详细描述如何来解决错误 2。
当用户尝试在查询分析器里面使用sa来连接SQL Server,或者在企业管理器里面使用sa来新建一个SQL Server注册时,经常会遇到如图 2 所示的错误信息。该错误产生的原因是由于SQL Server使用了"仅 Windows"的身份验证方式,因此用户无法使用SQL Server的登录帐户(如 sa )进行连接。解决方法如下所示:
1、 在服务器端使用企业管理器,并且选择"使用 Windows 身份验证"连接上 SQL Server;
2、 展开"SQL Server组",鼠标右键点击SQL Server服务器的名称,选择"属性",再选择"安全性"选项卡;
3、 在"身份验证"下,选择"SQL Server和 Windows "。
4、 重新启动SQL Server服务。
在以上解决方法中,如果在第 1 步中使用"使用 Windows 身份验证"连接 SQL Server 失败,那么我们将遇到一个两难的境地:首先,服务器只允许了 Windows 的身份验证;其次,即使使用了 Windows 身份验证仍然无法连接上服务器。这种情形被形象地称之为"自己把自己锁在了门外",因为无论用何种方式,用户均无法使用进行连接。实际上,我们可以通过修改一个注册表键值来将身份验证方式改为 SQL Server 和 Windows 混合验证,步骤如下所示:
1、点击"开始"-"运行",输入regedit,回车进入注册表编辑器;
2、依次展开注册表项,浏览到以下注册表键:
[HKEY_LOCAL_MACHINE/SOFTWARE/Microsoft/MSSQLServer/MSSQLServer]
3、在屏幕右方找到名称"LoginMode",双击编辑双字节值;
4、将原值从1改为2,点击"确定";
5、关闭注册表编辑器;
6、重新启动SQL Server服务。
此时,用户可以成功地使用sa在企业管理器中新建SQL Server注册,但是仍然无法使用Windows身份验证模式来连接SQL Server。这是因为在 SQL Server 中有两个缺省的登录帐户:BUILTIN/Administrators 以及 <机器名>/Administrator 被删除。要恢复这两个帐户,可以使用以下的方法:
1、打开企业管理器,展开服务器组,然后展开服务器;
2、展开"安全性",右击"登录",然后单击"新建登录";
3、在"名称"框中,输入 BUILTIN/Administrators;
4、在"服务器角色"选项卡中,选择"System Administrators" ;
5、点击"确定"退出;
6、使用同样方法添加 <机器名>/Administrator 登录。
以下注册表键
HKEY_LOCAL_MACHINE/SOFTWARE/Microsoft/MSSQLServer/MSSQLServer/LoginMode
的值决定了SQL Server将采取何种身份验证模式。该值为1,表示使用Windows 身份验证模式;该值为2,表示使用混合模式(Windows 身份验证和 SQL Server 身份验证)。
看完如何解决前两个错误的方法之后,让我们来看一下如图 3 所示的第三个错误。
如果遇到第三个错误,一般而言表示客户端已经找到了这台服务器,并且可以进行连接,不过是由于连接的时间大于允许的时间而导致出错。这种情况一般会发生在当用户在Internet上运行企业管理器来注册另外一台同样在Internet上的服务器,并且是慢速连接时,有可能会导致以上的超时错误。有些情况下,由于局域网的网络问题,也会导致这样的错误。
要解决这样的错误,可以修改客户端的连接超时设置。默认情况下,通过企业管理器注册另外一台SQL Server的超时设置是 4 秒,而查询分析器是 15 秒(这也是为什么在企业管理器里发生错误的可能性比较大的原因)。具体步骤为:
1、在企业管理器中,选择菜单上的"工具",再选择"选项";
2、在弹出的"SQL Server企业管理器属性"窗口中,点击"高级"选项卡;
3、在"连接设置"下的"登录超时(秒)"右边的框中输入一个比较大的数字,如 20。
查询分析器中也可以在同样位置进行设置。
二、应用程序连接失败
以上的三种错误信息都是发生在 SQL Server 自带的客户端工具中,在应用程序中我们也会遇到类似的错误信息,例如:
Microsoft OLE DB Provider for SQL Server (0x80004005)
[DBNETLIB][ConnectionOpen (Connect()).]Specified SQL server not found.
Microsoft OLE DB Provider for SQL Server (0x80004005)
用户 'sa' 登录失败。原因: 未与信任 SQL Server 连接相关联。
Microsoft OLE DB Provider for ODBC Drivers 错误 '80004005'.
[Microsoft][ODBC SQL Server Driver]超时已过期.
首先,让我们来详细看以下的示意图来了解一下使用 ODBC 和使用 OLE DB 连接 SQL Server 有什么不同之处。
从上图中,我们可以看出在实际使用中,应用程序创建和使用各种 ADO 对象,ADO 对象框架调用享用的 OLE DB 提供者。为了访问 SQL Server 数据库,OLE DB 提供了两种不同的方法:用于 SQL Server 的 OLE DB 提供者以及用于 ODBC 的 OLE DB 提供者。这两种不同的方法对应于两种不同的连接字符串,标准的连接字符串写法如下所示:
1、使用用于 SQL Server 的 OLE DB 提供者:
使用 SQL Server 身份验证:
oConn.Open "Provider=sqloledb;" & _
"Data Source=myServerName;" & _
"Initial Catalog=myDatabaseName;" & _
"User Id=myUsername;" & _
"Password=myPassword"
使用 Windows 身份验证(信任连接):
oConn.Open "Provider=sqloledb;" & _
"Data Source=myServerName;" & _
"Initial Catalog=myDatabaseName;" & _
"Integrated Security=SSPI"
2、使用用于 ODBC 的 OLE DB 提供者(不使用 ODBC 数据源):
使用 SQL Server 身份验证:
oConn.Open "Driver={SQL Server};" & _
"Server=MyServerName;" & _
"Database=myDatabaseName;" & _
"Uid=myUsername;" & _
"Pwd=myPassword"
使用 Windows 身份验证(信任连接):
oConn.Open "Driver={SQL Server};" & _
"Server=MyServerName;" & _
"Database=myDatabaseName;" & _
"Trusted_Connection=yes"
3、使用用于 ODBC 的 OLE DB 提供者(使用 ODBC 数据源):
oConn.Open "DSN=mySystemDSN;" & _
"Uid=myUsername;" & _
"Pwd=myPassword"
如果遇到连接失败的情况,我们只要按照一中所示的方法,结合程序中的连接字符串进行检查,基本都能得到解决。另外,还有以下几个要注意的地方:
1、配置 ODBC 数据源时,点击"客户端"配置选项可以让我们指定连接使用的网络库、端口号等属性,如下图所示:
2、如果遇到连接超时的错误,我们可以在程序中修改 Connection 对象的超时设置,再打开该连接。例如:
<%
Set Conn = Server.CreateObject("ADODB.Connection")
DSNtest="DRIVER={SQL Server};SERVER=ServerName;UID=USER;PWD=password;DATABASE=mydatabase"
Conn. Properties("Connect Timeout") = 15 '以秒为单位
Conn.open DSNtest
%>
3、如果遇到查询超时的错误,我们可以在程序中修改 Recordset 对象的超时设置,再打开结果集。例如:
Dim cn As New ADODB.Connection
Dim rs As ADODB.Recordset
. . .
cmd1 = txtQuery.Text
Set rs = New ADODB.Recordset
rs.Properties("Command Time Out") = 300
'同样以秒为单位,如果设置为 0 表示无限制
rs.Open cmd1, cn
rs.MoveFirst
. . .
三、小结
本文针对大部分用户在使用 SQL Server 过程中常见的连接失败的错误,重点讨论了在使用 SQL Server 客户端工具以及用户开发的应用程序两种情况下,如何诊断并解决连接失败的错误。看过本文以后,相信每一个读者都会对 SQL Server 的连接工作原理、身份验证方式以及应用程序开发等有一个较为全面而深入的连接。本文中所有的测试或者示例均在 Windows 2000 Advanced Server + SQL Server 2000 企业版上通过。
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/xuejinyoulan/archive/2007/11/03/1864937.aspx
------------------------------------------------------------------------------------
No10--出现死锁
当系统使用频繁就会出现插入表操作和删除表操作同时进行的情况。插入事务和删除事务分别将主表和子表放置独占锁,而两表又等着相互访问,这时造成死锁。这种情况下有三种解决方案。
------------------------------------------------------------------------------------
在数据库中经常会遇到这样的情况:一个主表A,一个子表B,B表中包含有A表的主键作为外键。当要插入数据的时候,我们会先插入A表,然后获得A表的Identity,再插入B表。如果要进行删除操作,那么就先删除子表B,然后再删除主表A。在程序设计中,对两个表的操作是在一个事务之中完成的。
当系统使用频繁就会出现插入操作和删除操作同时进行的情况。这个时候插入事务会先将主表A放置独占锁,然后去访问子表B,而同时删除事务会对子表B放置独占锁,然后去访问主表A。插入事务会一直独占着A表,等待访问B表,删除事务也一直独占着B表等待访问A表,于是两个事务相互独占一个表,等待对方释放资源,这样就造成了死锁。
遇到这种情况我听说了三种做法:
1 取消AB两个表之间的外键关系,这样就可以在删除数据的时候就可以先删除主表A,然后删除子表B,让对这两个表操作的事务访问顺序一致。
2 删除A表数据之前,先使用一个事务将B表中相关外键指向另外A表中的另外一个数据(比如在A表中专门建一行数据,主键设置为0,永远不会对这行数据执行删除操作),这样就消除了要被删除的数据在AB两个表中的关系。然后就可以使用删除事务,先删除A表中的数据,再删除B表中的数据,以达到和插入事务表访问一致,避免死锁。
3 在外键关系中,将“删除规则”设置为“层叠”,这样删除事务只需要直接去删除主表A,而不需要对子表B进行操作。因为删除规则设置为层叠以后,删除主表中的数据,子表中所有外键关联的数据也同时删除了。
以上三个解决办法都是同事给出的建议,我也不知道到底该使用什么办法才好。
不知道对于这种情况要防止死锁大家还有没有什么其他好办法?
------------------------------------------------------------------------------------
注:sp_depends的代码是公开的,有兴趣的可以看一下其实现过程。
到此,你应该明白,当你更新你的表或视图的时候,你还要刷新依赖于这些对象的视图的元数据,即需要调用sp_refreshview来刷新依赖于该对象的视图。但是你在查询依赖于一个表或者视图的对象集合的时候需要注意的一点是,在你更新了一个表或视图之后,那些之前创建的依赖于该表或视图的依赖关系将会丢失(你更新的表或视图所依赖的对象集合不会丢失),用我之前的例子来看,vCustomersB依赖于vCustomersA,那么当我们修改了vCustomersA以后,vCustomersB与vCustomersA之间的依赖关系将会丢失而vCustomersA所依赖的Customers将不会丢失(依赖关系在对象创建或更新时创建,更新时,会把先前的依赖关系删掉)。(调用sp_depends你就可以看出来这种微妙的变化)
希望在你阅读了本文以后,你在使用视图的时候会更加的得心应手,避免错误发生。文中有不对的地方欢迎指正批评!
![]() select * from vCustomersA where CustomerID = 'ALFKI'
select * from vCustomersA where CustomerID = 'ALFKI'
![]() select * from vCustomersB where CustomerID = 'ALFKI'
select * from vCustomersB where CustomerID = 'ALFKI'
![]()
查询的结果如下:

你注意到数据的异常了吗?使用视图vCustomersB查询的结果出现了错误,CompanyName显示的资料是:Maria Anders,而在视图vCustomersA查询的结果中CompanyName是:Alfreds Futterkiste。我们仅仅是在vCustomersA中互换了两个字段的位置,再次使用vCustomersB查询数据却发生了数据错位的现象,这是什么原因导致的呢?
带着这个问题,让我们去了解一下,何谓视图?在Sql Server2000的帮助文档中是这样描述视图的,定义如下:“视图是一个虚拟表,其内容由查询定义,同真实的表一样,视图包含一系列带有名称的列和行数据。但是,视图并不在数据库中以存储的数据值集形式存在。行和列数据来自由定义视图的查询所引用的表,并且在引用视图时动态生成。”通过这个定义我们可以看出,视图是一个虚拟的表,它仅仅包括视图的定义脚本,查询的内容则是动态的生成。当我们创建了一个视图以后,视图的脚本会保存到当前数据库的系统表syscomments里,我们可以通过系统提供的存储过程:sp_helptext查询得到视图的定义脚本。从定义上看,好像并不能得到我们想要的答案,那么我们就先不管Sql Server2000是如何实现视图的,我们先来解决一下当前的问题(我上面提到的)。可能有些朋友已经知道了解决问题的办法了,那就是把vCustomersB的定义脚本重新执行一下(其实只需要把create换成alter执行一下就可以),脚本如下:
SqlServer2000也提供了一个扩展存储过程sp_refreshview来帮我们做这件事情,调用的脚本如下:
![]() --重新执行一下vCustomersB的定义脚本
--重新执行一下vCustomersB的定义脚本
![]() alter view
vCustomersB
alter view
vCustomersB
![]() as
as
![]() select * from
vCustomersA
select * from
vCustomersA
![]() go
go
![]()
![]()
那么,除了这个方法以外,其实
![]() --刷新指定视图的元数据
--刷新指定视图的元数据
![]() exec sp_refreshview 'vCustomersB'
exec sp_refreshview 'vCustomersB'
![]()
我个人目前就知道这两个办法,不知道,你还有没有其他的办法,有的话可以一起分享一下。
sp_refreshview的功能描述为:“刷新指定视图的元数据。由于视图所依赖的基础对象的更改,视图的持久元数据会过期。”由于sp_refreshview的代码被封装了(没有公开),所以我们看不到它的内部实现,不过看了这个存储过程的描述,你是否对视图有了新的认识呢?根据现有的迹象,我推测,视图的工作原理大致如下:
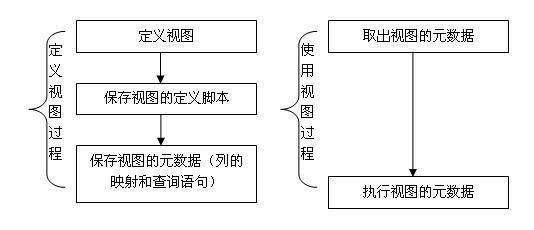
从这里,我们可以看到,当我们使用一个视图查询数据的时候,其实我们是在使用视图的元数据来查询的,当视图依赖的对象发生了变化以后,视图的元数据就需要更新,这样,使用视图时才不会违背我们的意愿。
知道了问题的产生的原因后,那么我们在重新修改一个表或视图的脚本时,我们就需要更新依赖于该对象的视图,否则就会出现意想不到的错误。如何找到依赖于该对象的对象(包括视图,触发器,存储过程)呢?SqlServer2000在该数据库的系统表sysdepends里记录这些依赖关系,所以你可以查询该表获取你想要的信息,但其实,你可以通过使用系统提供的存储过程:sp_depends来获取该对象的所依赖的对象(返回的第一个表)以及依赖于该对象的对象(返回的第二个表),脚本如下:
![]() --查询vCustomersA的依赖的对象以及依赖于vCustomersA的对象
--查询vCustomersA的依赖的对象以及依赖于vCustomersA的对象
![]() exec sp_depends 'vCustomersA'
exec sp_depends 'vCustomersA'
![]()
一切正常,这个时候,需求发生了变化,我们需要改动vCustomersA,改动后的脚本如下:(为了说明问题,我们只是把CompanyName和ContactName互换一下位置)
![]() --改动后的视图vCustomersA
--改动后的视图vCustomersA
![]() alter view
vCustomersA
alter view
vCustomersA
![]() as
as
![]() select
CustomerID ,ContactName,CompanyName,ContactTitle,
select
CustomerID ,ContactName,CompanyName,ContactTitle,
![]() Address,City,Region,PostalCode,Country,Phone,Fax
Address,City,Region,PostalCode,Country,Phone,Fax
![]() from
dbo.Customers
from
dbo.Customers
![]() go
go
![]()