十张图带你入门Map/Reduce
你可能已经知道:Map/Reduce是一种模式,非常适合令人烦恼的并行算法。但是什么是令人烦恼的并行算法?答案:这个算法非常适合被多重并行的执行。那么什么样的模式才会非常适合并行算法?答案:任何作用在数据上的算法都会被隔离。
如果你编写的程序经常会在同一个时刻执行多重事件,并且它们需要访问一些公用数据;那么将会出现冲突,你必须着手处理当一个事件修改某个数据时,而另一个事件正在读取这段数据。这就是并发操作。如果你事件作用的数据段没有被其它事件操作,那么做的将是并行操作。显而易见:你可以使用扩展来解决并发性问题。
举个例子:如果你有一张记录了城市的表格,而每个城市都有两个属性 —— 所属州和城市年度平均温度。比如:San Francisco:{CA,58}。现在你想计算每年的平均温度 —— BY STATE。因为可以通过state对city进行分组查询,然后计算一个州的平均温度而不涉及到其他的州 —— 这里就将会出现高度并行算法问题。
如果你想逐步做这件事,你将从一个空的平均温度表开始。然后迭代访问表中的城市,查询每个城市中的state属性,接着做出相关的年度平均温度修改。
接下来看第一幅图:
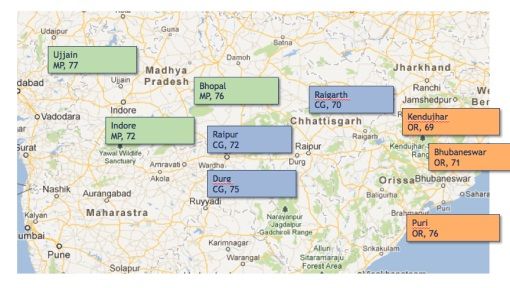
这是一张印度地图。有许多州:MP、CG、OR等等。同样有数个城市,每一个城市都有{State,City average temperture}作为值。
这里我们将做每个周的平均温度。我们将通过state来分组查询城市的平均温度,然后计算出每个组的平均值。

当然我们并不是很在意每个城市的名称,所以将抛弃它只保留州名和城市温度。

既然已经获得了我们想要的数据,那么可以通过state进行重分组。我们将得到一张关于所有州内所有平均温度的表。

这里我们得到了非常好的数据模型用于逻辑计算,而仅需要做的就是计算每个州的平均温度。

当然,这并不困难。
我们有一些数据。做一点点的重分组,然后做计算。当然所有的这些都可以并行的执行(每个state一个并行任务)。
下面我们使用Map/Reduce重做这个问题!
Map/Reduce有3个步骤:Map/Shuffle/Reduce
Shuffle部分由Hadoop自行完成,这里只需要关注Map和Reduce的实现部分。
在Map部分你需要输入<Key,Value>数据。
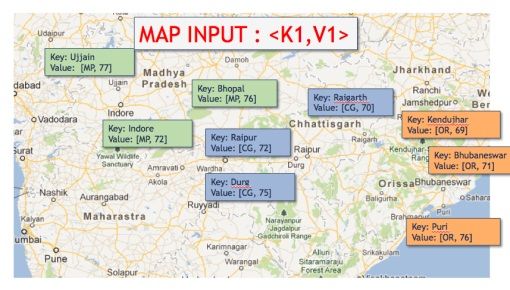
在这里Key就是城市的名称,而Value是属性集:所属州以及城市均温。
同样通过state将temperature重分组、排除下城市名称,那么在state变为Key时temperature将成为Value。

现在Shuffle的任务是实现Map的完成。它将会通过Key进行分组,然后你就会获得一个List<Value>。

这也将作为Reduce任务的输入数据 —— 从Shuffle任务中获得的Key、List<Value>。
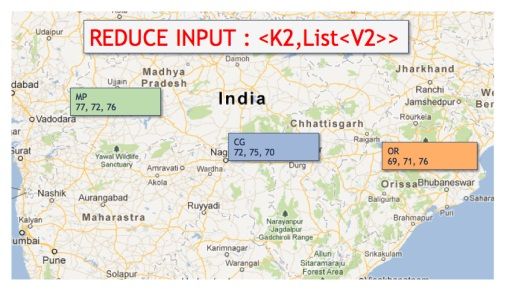
Reduce任务还是数据逻辑的完成者,在这里当然就是计算州的年平均温度。
我们也将获得如下的最终结果

这样就完成了Map/Reduce对数据进行重塑:
Mapper<K1,V1> ==》 <K2,V2>
Reducer<K2,List<V2> >==》<K3,V3>
简单的Map/Reduce入门希望能帮助弄清Map/Reduce任务的实现过程,下面附带用例代码:用例代码部分(Java)
原文链接:Confused About Map/Reduce?(编译/仲浩 王旭东/审校)
欢迎关注@CSDN云计算微博,了解更多云信息。
本文为CSDN编译整理,未经允许不得转载。如需转载请联系mark