数据挖掘 graph mining 之 ranking 介绍
近年来,图挖掘graph mining渐渐热了起来。这里的图是图论里说的那个图,也就是点集合和边集合构成的一种数据结构。
图挖掘中几个比较重要的方向有:
1. community detection
2. frequent subgraph mining
3. ranking
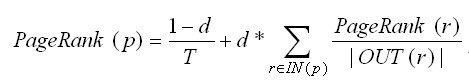
ranking中最出名的就是google的pagerank, pagerank的思想简单而巧妙:假设一个人在浏览网页的时候,有一定的概率会点击页面的超链接,或者直接输入URL访问其他页面。那些会被广大页面所引用的页面,就是高质量的界面。
Pagerank的公式非常简单:每个页面p的pr值等于所有指向p的pr值贡献度之和
其中,T为计算中的页面总量, d是阻尼常数因子,一般取0.85;IN(p)为所有指向p的页面的集合;OUT(r)为页面r出链的集合。计算的时候,所有节点初始化pr值相等,每一轮为每个节点计算出pr值以后,进行归一化,下一轮用上一轮的pr值。经过若干次迭代计算,pr值就会收敛到一个稳定的结果了。
首先我们初始化ABC的pr值分别为1/3。
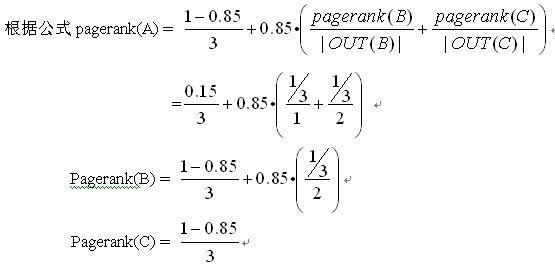
得到ABC新的pr值以后,再进行多次计算,就可以得到最后ABC的pr值了.
表示成矩阵计算更直观一些:

这里面的矩阵G’就是graph的邻接矩阵G每一列进行归一化,再转置得到的。
(后面那个矩阵的乘法表示错了,你就当做 pr(A) = 向量与矩阵第一行的点积,pr(B) = 向量与矩阵第二行的点积...)
更一般化的写法:
有个更详细的讲解说明,在这http://www.kreny.com/pagerank_cn.htm
在公式中,pr向量乘以转置矩阵G’的每一行,都是独立的,因此pagerank又是一个可以分布式计算的算法。
介绍完pagerank,下面再介绍图挖掘中community detection.中的一个算法
community detection社团发现是复杂网络研究中一个比较热门的方向。和聚类的任务相似,社团发现的任务是要把网络中节点划分到不同的小社区。社区中节点之间连线比较密集,但社团与社团之间连接很稀疏,这与聚类的定义也很相似。社团发现算法也很多,本人知道的就这一个,来自于这篇论文:
Near linear time algorithm to detect community structures in large-scale networks。
文章提出的一个叫label propagation(我简称LP)的方法,避免了前人的工作存在的问题:
1.需要预先制定一些参数信息,如社团数、中心点之类的;
2.计算复杂度高。
LP算法的思想如下:一个节点的选择类别是取决于与它相连接的节点的类别。
将所有节点初始化类别C为节点编号,之后为每个节点根据邻居计算其属于那个类别。这个过程迭代进行。每轮迭代之后更新节点类别,更新方式可以是同步或者异步。
同步的方式是节点类别的计算只依赖于上一轮迭代时的节点类别,即

算法核心步骤可以描述为:
1. 初始化节点C0(x)=x
2. 令t=1
3. 网络中所有节点进行随机排序,得到顺序X
4. 对X中每个节点x计算Ct(x)
5. 如果每个节点的类别都是它邻居类别的最多的那个,算法停止,否则转到步骤3
算法不能保证一定收敛,(虽然实验也指出经过5轮迭代,就有95%的节点达到了最终的类别)需要额外的判断条件。原文的判断条件不列了,另外一篇文章指出只要修改一下f,让x判断也包括本节点的类别就行了。
读完LP算法你就会发现,它处理方式和pagerank很接近,都是一个向量乘上一个矩阵,向量代表各节点的状态,矩阵代表节点与邻居的关系。LP虽然是为了社团发现,但用的是一种graph ranking的思想。这种Ranking方法在考察网络中一个节点的重要程度,是通过与之相连的节点间的重要性。当一个节点连接到另一节点时,它会向这个被相连的节点进行一个“投票”;节点得到的“票数”越多,它就越重要;同时它投出的票也越重要。
例如另一个也很出名的ranking算法HITS。HITS算法认为,一个链接到其他很多网页的网页是一个好的hub(中心网页),一个被很多其他网页链接的网页是一个好的authority(权威网页);一个链接到很多好的权威网页的网页是一个更好的hub(中心网页);同理,一个被很多好的中心网页链接的网页是一个更好的authority(权威网页)网。
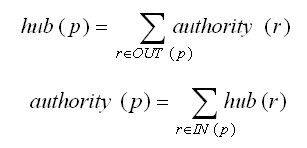
各个节点的状态在若干次投票之后达到一个比较稳定的状态,这种状态可以说就是隐藏在网络中的一种知识,各个算法在处理投票上有所不同,因此ranking是一种值得掌握的数据挖掘方法。