Hadoop大象之旅007-配置Hadoop伪分布模式
Hadoop大象之旅007-配置Hadoop伪分布模式
老帅
安装hadoop分为本地模式、伪分布模式、集群模式。本地模式是运行在本地,只负责存储,没有计算功能。伪分布模式是在一台机器上模拟分布式部署,方便学习和调试。集群模式是在多个机器上配置hadoop,是真正的“分布式”。
伪分布模式是在一台单机上运行,但用不同的 Java 进程模仿分布式运行中的各类结点 ( NameNode, DataNode, JobTracker, TaskTracker, SecondaryNameNode )。
分布式运行中的这几个结点的区别:从分布式存储的角度来说,集群中的结点由一个 NameNode 和若干个 DataNode 组成, 另有一个Secondary NameNode 作为NameNode 的备份。从分布式应用的角度来说,集群中的结点由一个JobTracker 和若干个 TaskTracker 组成,JobTracker 负责任务的调度,TaskTracker 负责并行执行任务。TaskTracker 必须运行在 DataNode 上,这样便于数据的本地计算。JobTracker 和 NameNode 则无须在同一台机器上。
本章讲述伪分布模式的安装。
1.先研究一下Hadoop的目录结构
参照前面章节中所述方法,使用SecureCRTPortable.exe登录CentOS;
使用命令“cd/usr/local/hadoop”或者“cd $HADOOP_HOME”进入到Hadoop根目录;
使用命令“ll”查看一下目录结构,如下图所示:
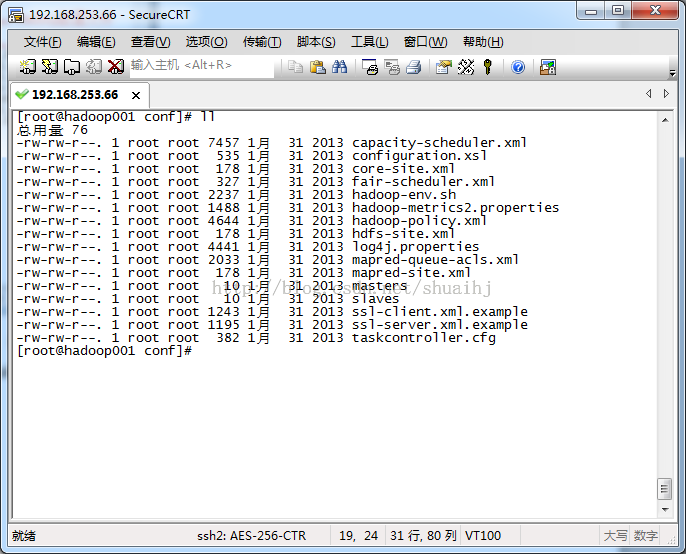
其中d开头的表示文件夹,-开头的表示文件
我们要进行伪分布模式安装,需要修改的配置文件,都在“$HADOOP_HOME/conf”文件夹中
使用命令“cd $HADOOP_HOME/conf”进入到Hadoop根目录下;
使用命令“ll”查看一下目录结构,如下图所示:
2.修改hadoop-env.sh
这是Hadoop环境变量配置文件。
为了使Hadoop认识JDK,需要设置JAVA_HOME。
使用命令“vihadoop-env.sh”编辑配置文件,如下图所示:
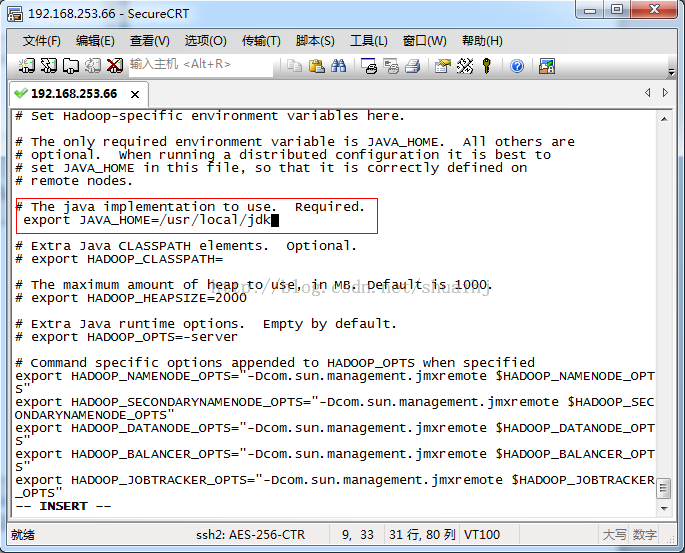
使用快捷键“i”进入文件编辑模式,修改内容如上图所示
export JAVA_HOME=/usr/local/jdk
记住要把前面的#注释删除
使用快捷键“esc”退出文件编辑模式,
使用“Shift”和“:”组合键进入命令模式,
输入命令“wq”保存并退出。
3.修改core-site.xml
这是Hadoop的核心配置文件。
使用命令“vicore-site.xml”编辑配置文件,如下图所示:
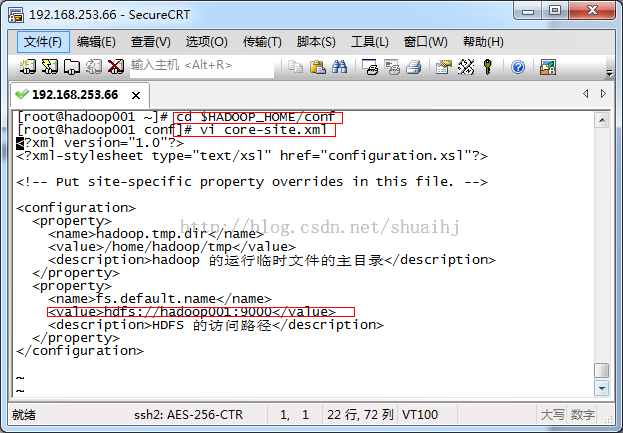
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
<description>hadoop的运行临时文件的主目录</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop001:9000</value>
<description>HDFS的访问路径</description>
</property>
<configuration>
hadoop.tmp.dir 的意思是 hadoop 运行时产生临时文件的主目录,我们把它放在/home/hadoop/temp 下;
fs.default.name 的意思是 hdfs 的访问路径,我们把它定义在 CentOS 下的 9000 端口;
这里的 hadoop001 就是在主机的名字,配置在/etc/hosts。
4.修改hdfs-site.xml
这是hdfs的配置文件。
使用命令“vihdfs-site.xml”编辑配置文件,如下图所示:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>存储副本数</description>
</property>
</configuration>
dfs.replication 的意思是hdfs存放文件副本的数量,默认为 3,在这里,我们是伪分布模式,这里设置为 1
5.修改 mapred-site.xml
这是mapreduce的配置文件
使用命令“vimapred-site.xml”编辑配置文件,如下图所示:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop001:9001</value>
<description>JobTracker的访问路径</description>
</property>
</configuration>
mapred.job.tracker 的意思是hadoop 中对于jobTracker 的访问路径,我们把它定义在 CentOS 下的 9001 端口;
这里的 hadoop001 就是在主机的名字,配置在/etc/hosts。
这就是安装伪分布模式的最小化配置。