Hadoop学习之修改Eclipse插件
之前手工成功编译Hadoop-1.2.1的Eclipse插件后,发现了若干问题,比如生成的Mapper和Reducer还在使用Hadoop-0.x版本的一些类,为了解决这些问题并使插件能够适应Hadoop-1.2.1的变化,决定修改插件的源代码后再重新编译。
首先需要确定要修改哪些类,在仔细观察了hadoop-1.2.1/src/contrib/eclipse-plugin/src/java/org/apache/hadoop/eclipse目录下的源代码和使用Eclipse开发Hadoop程序时的向导,发现只需要修改NewMapperWizard.java、NewReducerWizard.java、NewDriverWizardPage.java这几个文件就可以使Eclipse插件适应Hadoop-1.2.1版本。在详细介绍如何修改源文件之前,先看看未修改时创建Hadoop应用程序的向导和生成的Mapper、Reducer是什么样子的。
在Eclipse中新建Mapper时的向导如下图所示:
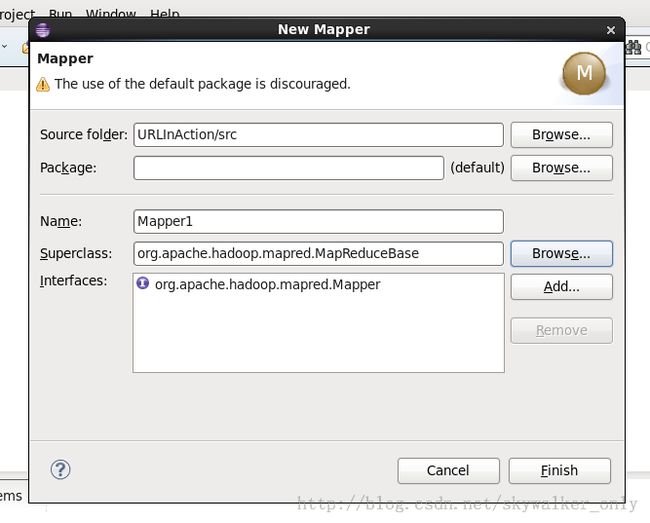
生成的Mapper程序如下:
import java.io.IOException;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
public class Mapper1 extends MapReduceBase implements Mapper {
public void map(WritableComparable key, Writable values,
OutputCollector output, Reporter reporter) throws IOException {
}
}
新建Reducer的向导图为:
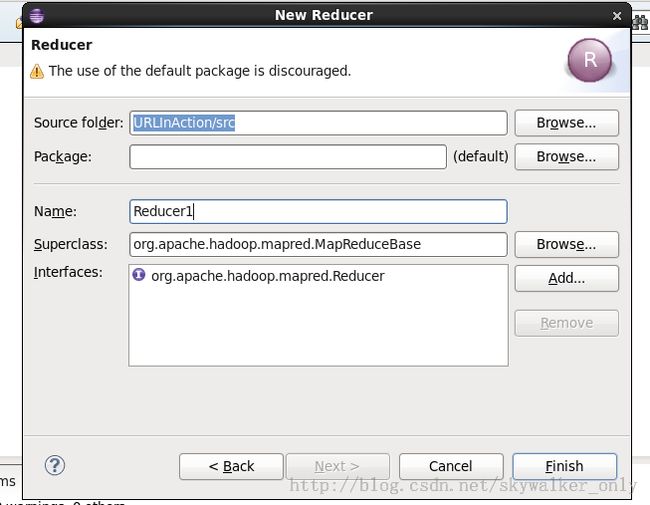
生成的Reducer代码如下:
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
public class Reducer1 extends MapReduceBase implements Reducer {
public void reduce(WritableComparable _key, Iterator values,
OutputCollector output, Reporter reporter) throws IOException {
// replace KeyType with the real type of your key
KeyType key = (KeyType) _key;
while (values.hasNext()) {
// replace ValueType with the real type of your value
ValueType value = (ValueType) values.next();
// process value
}
}
}
新建Driver的向导图为:
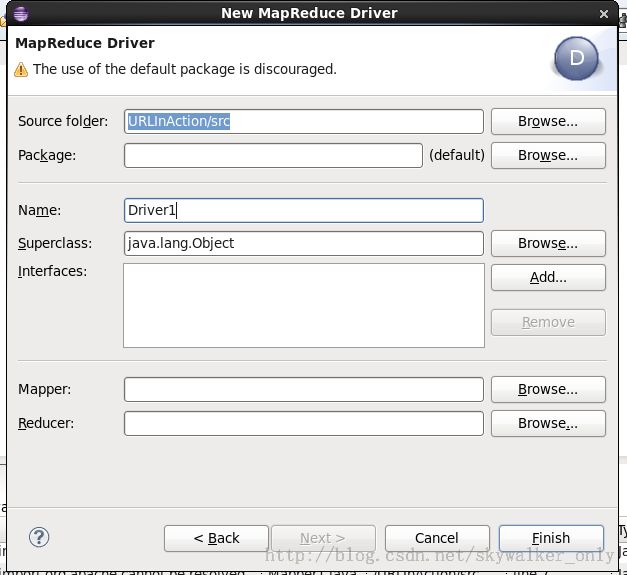
生成的Driver代码为:
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.Reducer;
public class Driver1 {
public static void main(String[] args) {
JobClient client = new JobClient();
JobConf conf = new JobConf(Driver1.class);
// TODO: specify output types
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
// TODO: specify input and output DIRECTORIES (not files)
conf.setInputPath(new Path("src"));
conf.setOutputPath(new Path("out"));
// TODO: specify a mapper
conf.setMapperClass(org.apache.hadoop.mapred.lib.IdentityMapper.class);
// TODO: specify a reducer
conf.setReducerClass(org.apache.hadoop.mapred.lib.IdentityReducer.class);
client.setConf(conf);
try {
JobClient.runJob(conf);
} catch (Exception e) {
e.printStackTrace();
}
}
}
在看过了未作修改时的Mapper和Reducer的向导和生成的代码后,现在看看修改后的效果。下面是新的Mapper向导:
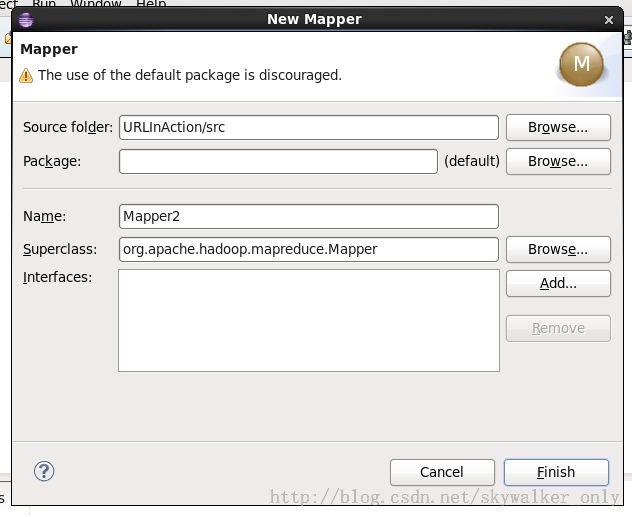
生成的新Mapper代码为:
import java.io.IOException;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Mapper;
public class Mapper2 extends Mapper {
public void map(WritableComparable key, Writable value, Context context)
throws IOException, InterruptedException {
}
}
新的Reducer向导如下:
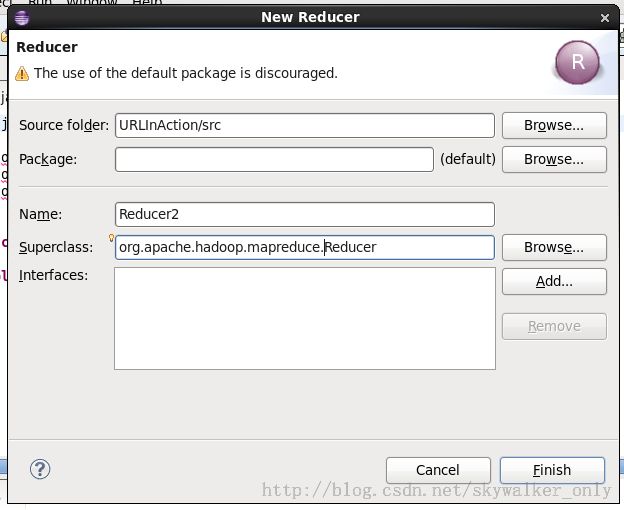
生成的新Reducer代码为:
import java.io.IOException;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Reducer;
public class Reducer2 extends Reducer {
public void reduce(WritableComparable key, Iterable<Writable> values,
Context context) throws IOException, InterruptedException {
}
}
新的Driver向导如下:
生成的新Driver代码为:
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Driver2 {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "Your job name");
// TODO: specify output types
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// TODO: specify a mapper
job.setMapperClass(org.apache.hadoop.mapred.lib.IdentityMapper.class);
// TODO: specify a reducer
job.setReducerClass(org.apache.hadoop.mapred.lib.IdentityReducer.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
在看过了实际效果后,接下来就是如何具体修改源代码,修改主要涉及到NewMapperWizard.java、NewReducerWizard.java、NewDriverWizardPage.java这三个文件。按照上面展示Mapper、Reducer、Driver的顺序,先看看Mapper的修改,在NewMapperWizard.java中修改createTypeMembers和createControl方法中的部分方法,其中createTypeMembers方法中的代码改为:
super.createTypeMembers(newType, imports, monitor);
imports.addImport("java.io.IOException");
imports.addImport("org.apache.hadoop.io.WritableComparable");
imports.addImport("org.apache.hadoop.io.Writable");
//imports.addImport("org.apache.hadoop.mapred.OutputCollector");
//imports.addImport("org.apache.hadoop.mapred.Reporter");
/*newType
.createMethod(
"public void map(WritableComparable key, Writable values, OutputCollector output, Reporter reporter) throws IOException \n{\n}\n",
null, false, monitor);*/
newType
.createMethod(
"public void map(WritableComparable key, Writable value, Context context) throws IOException, InterruptedException {\n}\n",
null, false, monitor);
createControl方法中的代码修改部分为:
//setSuperClass("org.apache.hadoop.mapred.MapReduceBase", true);
setSuperClass("org.apache.hadoop.mapreduce.Mapper", true);
// setSuperInterfaces(Arrays
// .asList(new String[] { "org.apache.hadoop.mapred.Mapper" }), true);
NewReducerWizard.java中的修改与Mapper中的修改基本类似,也是修改createTypeMembers和createControl中的代码,具体createTypeMembers为:
super.createTypeMembers(newType, imports, monitor);
imports.addImport("java.io.IOException");
imports.addImport("org.apache.hadoop.io.WritableComparable");
imports.addImport("org.apache.hadoop.io.Writable");
//imports.addImport("org.apache.hadoop.mapred.OutputCollector");
//imports.addImport("org.apache.hadoop.mapred.Reporter");
/*newType
.createMethod(
"public void reduce(WritableComparable _key, Iterable values, OutputCollector output, Reporter reporter) throws IOException \n{\n"
+ "\t// replace KeyType with the real type of your key\n"
+ "\tKeyType key = (KeyType) _key;\n\n"
+ "\twhile (values.hasNext()) {\n"
+ "\t\t// replace ValueType with the real type of your value\n"
+ "\t\tValueType value = (ValueType) values.next();\n\n"
+ "\t\t// process value\n" + "\t}\n" + "}\n", null, false,
monitor);*/
newType
.createMethod(
"public void reduce(WritableComparable key, Iterable<Writable> values, Context context) throws IOException, InterruptedException {\n}\n",
null, false,
monitor);
createControl方法的修改为:
//setSuperClass("org.apache.hadoop.mapred.MapReduceBase", true);
/*setSuperInterfaces(Arrays
.asList(new String[] { "org.apache.hadoop.mapred.Reducer" }), true);*/
setSuperClass("org.apache.hadoop.mapreduce.Reducer", true);
NewDriverWizardPage.java文件主要修改的方法也为createTypeMembers和createControl,其中createTypeMembers方法修改为:
/*String method = "public static void main(String[] args) {\n JobClient client = new JobClient();";
method += "JobConf conf = new JobConf("
+ newType.getFullyQualifiedName() + ".class);\n\n";
method += "// TODO: specify output types\nconf.setOutputKeyClass(Text.class);\nconf.setOutputValueClass(IntWritable.class);\n\n";
method += "// TODO: specify input and output DIRECTORIES (not files)\nconf.setInputPath(new Path(\"src\"));\nconf.setOutputPath(new Path(\"out\"));\n\n";
if (mapperText.getText().length() > 0) {
method += "conf.setMapperClass(" + mapperText.getText()
+ ".class);\n\n";
} else {
method += "// TODO: specify a mapper\nconf.setMapperClass(org.apache.hadoop.mapred.lib.IdentityMapper.class);\n\n";
}
if (reducerText.getText().length() > 0) {
method += "conf.setReducerClass(" + reducerText.getText()
+ ".class);\n\n";
} else {
method += "// TODO: specify a reducer\nconf.setReducerClass(org.apache.hadoop.mapred.lib.IdentityReducer.class);\n\n";
}
method += "client.setConf(conf);\n";
method += "try {\n\tJobClient.runJob(conf);\n} catch (Exception e) {\n"
+ "\te.printStackTrace();\n}\n";
method += "}\n";*/
String method = "public static void main(String[] args) throws Exception {\n Configuration conf = new Configuration();\n";
method += "Job job = new Job(conf, \"Your job name\");\n";
method += "// TODO: specify output types\njob.setOutputKeyClass(Text.class);\njob.setOutputValueClass(IntWritable.class);\n\n";
//method += "// TODO: specify input and output DIRECTORIES (not files)\nconf.setInputPath(new Path(\"src\"));\nconf.setOutputPath(new Path(\"out\"));\n\n";
if (mapperText.getText().length() > 0) {
method += "job.setMapperClass(" + mapperText.getText()
+ ".class);\n\n";
} else {
method += "// TODO: specify a mapper\njob.setMapperClass(org.apache.hadoop.mapred.lib.IdentityMapper.class);\n\n";
}
if (reducerText.getText().length() > 0) {
method += "job.setReducerClass(" + reducerText.getText()
+ ".class);\n\n";
} else {
method += "// TODO: specify a reducer\njob.setReducerClass(org.apache.hadoop.mapred.lib.IdentityReducer.class);\n\n";
}
method += "FileInputFormat.addInputPath(job, new Path(args[0]));\n";
method += "FileOutputFormat.setOutputPath(job, new Path(args[1]));\n";
method += "System.exit(job.waitForCompletion(true) ? 0 : 1);\n";
method += "}\n";
createControl方法中主要是注释掉:
// setSuperClass("org.apache.hadoop.mapred.MapReduceBase", true);
// setSuperInterfaces(Arrays.asList(new String[]{
// "org.apache.hadoop.mapred.Mapper" }), true);
这样Eclipse的Hadoop-1.2.1插件已经修改完毕,重新编译一下,并将编译成功的jar文件放到Eclipse的plugins目录中并重启Eclipse就可以达到上面描述过的效果。