3.4.1 初始化内存管理(一)
3.4 初始化内存管理(一)
在内存管理上下文中,初始化可以有多种含义。在许多CPU上,必须显示设置适于linux内核的内存模型。例如,在IA-32系统上需要切换到保护模式,然后内核才能检测可用内存和寄存器。在初始化过程中,还必须建立内存管理的数据结构,以及其他很多事务。因为内核在内存管理完全初始化之前就要使用内内存,在系统启动过程期间,使用了一个额外的简化形势的内存管理模块,然后又丢弃掉。
因为内存管理初始化中特定于CPU的部分使用了底层体系结构许多次要、微妙的细节,这些与内核的结构没有什么关系,最多不过是汇编语言程序设计的实践而已,所以这里不讨论。这里从比较高的层次来考虑内核初始化工作,主要是pg_data_t数据结构的初始化,与机器无关。
3.4.1 建立数据结构
对相关数据结构的初始化是从全局启动例程start_kernel开始的。该例程在加载内核并激活各个子系统之后执行。由于内存管理是内核一个非常重要的部分,因此在特定于体系结构的设置步骤中检测内存并确定系统中内存的分配情况后,会立即执行内存管理系统的初始化。此时,已经对各种系统内存模式生成了一个pgdat_t实例(内存结点,参考《linux内核探索之内存管理(二):linux系统中的内存组织--结点、内存域和页帧》),用于保存诸如结点中内存数量以及内存在各个内存域之间分配情况的信息。所有平台都实现了特定于体系结构的NODE_DATA宏,用于通过结点编号,来查询与一个NUMA节点相关的pgdat_t实例。
1. 先决条件
由于大部分系统都只有一个内存结点,所以这里只考察UMA系统。为确保内存管理代码是可移植的(UMA/NUMA),内核在mm/page_alloc.c中定义了一个pg_data_t实例(称为config_page_data--最新内核中为node_data)管理所有的系统内存。根据该文件的路径名可以看出,这不是特定于CPU的实现。实际上大部分体系结构都采用了该方案。NODE_DATA的实现现在更简单了。
//mmzone.h:
#define NODE_DATA(nid) (&node_data[(nid)])
尽管该宏有一个形式参数用于选择NUMA结点,但在UMA系统中只有一个伪结点,因此总是返回同样的数据。
内核也可以依赖于以下事实:体系结构相关的初始化代码将numnodes变量设置为系统中结点的数目。在UMA系统上因为只有一个形式上的结点,因此改数量会是1.
在编译时,预处理器语句会为特定的配置选择正确的定义。
2. 系统启动
图3-8给出start_kernel的代码流程图。其中只包括与内存管理相关的系统的初始化
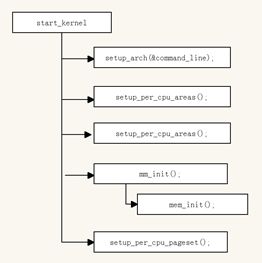
我们首先概述相关函数的任务,然后在以下各节点中仔细考察这些函数。
setup_arch是一个特定于体系结构的设置函数,其中一项任务时负责初始化自举分配器。
在SMP系统上,setup_per_cpu_areas初始化源代码中(使用per_cpu宏)定义的静态per-cpu变量,这种变量对系统中的每个CPU都有一个独立的副本。此类变量保存在内核二进制映像的一个独立的段中。Setup_per_cpu_areas的目的是为系统的各个CPU分别创建一份这些数据的副本。
build_all_zonelists建立结点和内存域的数据结构
mm_init/mem_init是另一个特定于体系结构的函数,用于停用bootmem分配并迁移到实际的内存管理函数。
kmem_cache_init初始化内核内部用于小块内存区的分配器。
setup_per_cpu_pageset从上下文提到的struct zone,为pageset数组的第一个数组元素分配内存。分配第一个数组元素,换句话说,就是意味着为第一个系统处理器分配。系统的所有内存域都会考虑进来。该函数还负责设置冷热分配器的限制。
在SMP系统上对应于其他CPU的pageset数组成员,将会在相应的CPU激活时初始化。
备注:参考《深入linux内核架构》及《深入理解Linux内核》