CDH5安装LZO压缩机制
目录[-]
目录[-]
1、到http://archive-primary.cloudera.com/gplextras/parcels/latest/下载最新lzo parcels包,根据安装hadoop集群的服务器操作系统版本下载,我使用的是rhel6.2, 所以下载的是HADOOP_LZO-0.4.15-1.gplextras.p0.64-el6.parcel
2、同时下载manifest.json,并根据manifest.json文件中的hash值创建sha文件(注意:sha文件的名称与parcels包名一样)
3、命令行进入Apache(如果没有安装,则需要安装)的网站根目录下,默认是/var/www/html,在此目录下创建lzo,并将这三个文件放在lzo目录中
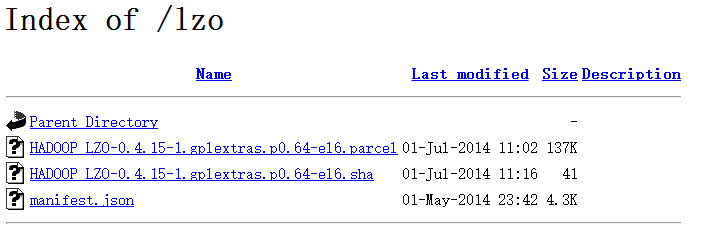
4、启动httpd服务,在浏览器查看,如http://ip/lzo,则结果如下:
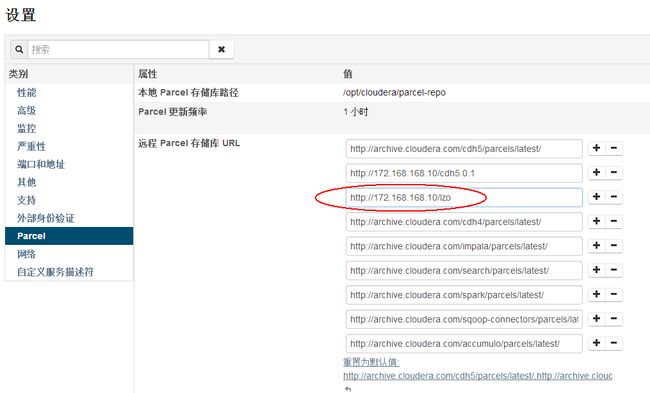
5、将发布的local parcels发布地址配置到远程 Parcel 存储库 URL地址中,见下图
6、在cloud manager的parcel页面的可下载parcel中,就可以看到lzo parcels, 点击并进行下载
7、根据parcels的部署步骤,进行分配、激活。结果如下图
修改hdfs的配置
将io.compression.codecs属性值中追加,org.apache.hadoop.io.compress.Lz4Codec,
com.hadoop.compression.lzo.LzopCodec
修改yarn配置
将mapreduce.application.classpath的属性值修改为:$HADOOP_MAPRED_HOME/*,$HADOOP_MAPRED_HOME/lib/*,$MR2_CLASSPATH,/opt/cloudera/parcels/HADOOP_LZO/lib/hadoop/lib/*
将mapreduce.admin.user.env的属性值修改为:LD_LIBRARY_PATH=$HADOOP_COMMON_HOME/lib/native:$JAVA_LIBRARY_PATH:/opt/cloudera/parcels/HADOOP_LZO/lib/hadoop/lib/native
create external table lzo(id int,name string) row format delimited fields terminated by '#' STORED AS INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' location '/test';
创建一个data.txt,内容如下:
|
1
2
3
4
5
|
1#tianhe
2#gz
3#sz
4#sz
5#bx
|
启动hive,建表并进行数据查询,结果如下:
hive> create external table lzo(id int,name string) row format delimited fields terminated by '#' STORED AS INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' location '/test';
OK
Time taken: 0.108 seconds
hive> select * from lzo where id>2;
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1404206497656_0002, Tracking URL = http://hadoop01.kt:8088/proxy/application_1404206497656_0002/
Kill Command = /opt/cloudera/parcels/CDH-5.0.1-1.cdh5.0.1.p0.47/lib/hadoop/bin/hadoop job -kill job_1404206497656_0002
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2014-07-01 17:30:27,547 Stage-1 map = 0%, reduce = 0%
2014-07-01 17:30:37,403 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.84 sec
2014-07-01 17:30:38,469 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.84 sec
2014-07-01 17:30:39,527 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.84 sec
MapReduce Total cumulative CPU time: 2 seconds 840 msec
Ended Job = job_1404206497656_0002
MapReduce Jobs Launched:
Job 0: Map: 1 Cumulative CPU: 2.84 sec HDFS Read: 295 HDFS Write: 15 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 840 msec
OK
3 sz
4 sz
5 bx
Time taken: 32.803 seconds, Fetched: 3 row(s)
hive> SET hive.exec.compress.output=true;
hive> SET mapred.output.compression.codec=com.hadoop.compression.lzo.LzopCodec;
hive> create external table lzo2(id int,name string) row format delimited fields terminated by '#' STORED AS INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' location '/test';
OK
Time taken: 0.092 seconds
hive> insert into table lzo2 select * from lzo;
Total MapReduce jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1404206497656_0003, Tracking URL = http://hadoop01.kt:8088/proxy/application_1404206497656_0003/
Kill Command = /opt/cloudera/parcels/CDH-5.0.1-1.cdh5.0.1.p0.47/lib/hadoop/bin/hadoop job -kill job_1404206497656_0003
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2014-07-01 17:33:47,351 Stage-1 map = 0%, reduce = 0%
2014-07-01 17:33:57,114 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.96 sec
2014-07-01 17:33:58,170 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.96 sec
MapReduce Total cumulative CPU time: 1 seconds 960 msec
Ended Job = job_1404206497656_0003
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://hadoop01.kt:8020/tmp/hive-hdfs/hive_2014-07-01_17-33-22_504_966970548620625440-1/-ext-10000
Loading data to table default.lzo2
Table default.lzo2 stats: [num_partitions: 0, num_files: 2, num_rows: 0, total_size: 171, raw_data_size: 0]
MapReduce Jobs Launched:
Job 0: Map: 1 Cumulative CPU: 1.96 sec HDFS Read: 295 HDFS Write: 79 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 960 msec
OK
Time taken: 36.625 seconds