用OpenCL实现HEVC中ME模块的测试数据分析
使用opencl来实现编码算法中运动搜索模块!
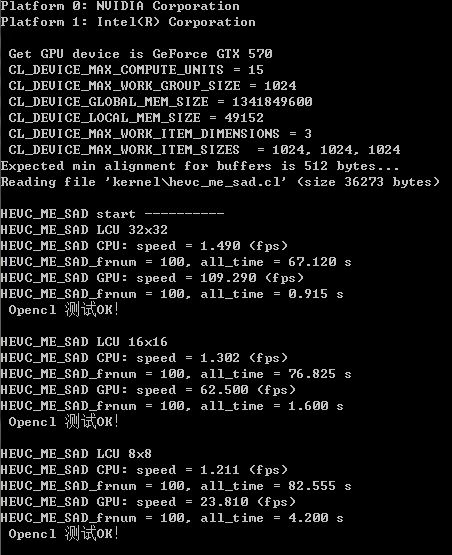
下面测试数据时在GTX570上的测试结果:
LCU为32x32, 100帧720P, CPU上纯C算法使用搜索时间是67s, GPU上是0.915s
LCU为16x16, CPU 是76.8s, GPU上是1.6s
LCU为8x8, CPU 是82.5s, GPU上是4.2s
同样的程序, CPU改为SSE实现, GPU做一个小的改动, 使用缩减算法! 结果如下:
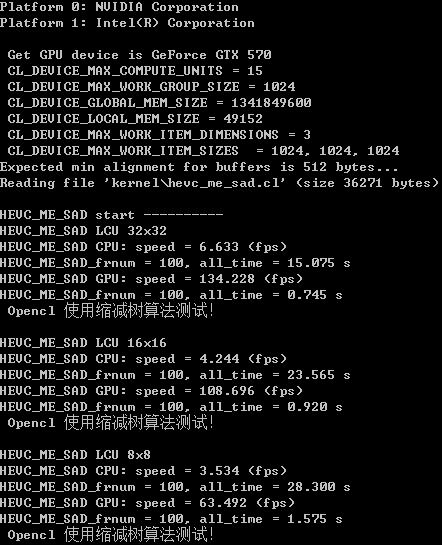
从上面数据可以看出, sse 比C语言快5倍左右, 新的GPU kenel快了20%左右, 其中LCU为8x8的快了好几倍!
综合看来
OPENCL实现 比C语言实现接近100倍的级别, 比SSE快了接近20倍左右!
另外提一句, 如果OPENCL不适用__local 内存的话, 会慢一半!
下面贴出部分代码供参考:
#define SearchRange 16
#define Edge_SIZE_T 48
//32x32 version of kernel
__kernel void opencl_me_32x32(const __global short* p_ref, __global short* p_cur, __global int* outputBuf, __local int* local_refBuf, __local int* local_curBuf, __local int* mv_cost)
{
int searchrange = SearchRange;
int edeg = Edge_SIZE_T;
int width = get_global_size(0);
int height = get_global_size(1);
int block_w = get_local_size(0);
int block_h = get_local_size(1);
int local_x = get_local_id(0);
int local_y = get_local_id(1);
int lcu_x = get_group_id(0);
int lcu_y = get_group_id(1);
int stride = width + 2 * edeg;
int lcu_adr_offset = edeg * stride + edeg;
int local_refBuf_stride = block_w + 2 * searchrange;
//LCU blcok adr
lcu_adr_offset += lcu_y * stride * block_h + lcu_x * block_w;
int ref_lcu_adr_offset = lcu_adr_offset - searchrange - searchrange * stride;
//thread adr
int global_thread_adr_offset = local_y * stride + local_x;
int thread_adr_offset = local_y * local_refBuf_stride + local_x;
local_curBuf[local_y * block_w + local_x] = p_cur[lcu_adr_offset + global_thread_adr_offset];
local_refBuf[thread_adr_offset] = p_ref[ref_lcu_adr_offset + global_thread_adr_offset ];
local_refBuf[thread_adr_offset + block_w] = p_ref[ref_lcu_adr_offset + global_thread_adr_offset + block_w];
local_refBuf[thread_adr_offset + local_refBuf_stride * block_h] = p_ref[ref_lcu_adr_offset + global_thread_adr_offset + stride * block_h];
local_refBuf[thread_adr_offset + local_refBuf_stride * block_h + block_w] = p_ref[ref_lcu_adr_offset + global_thread_adr_offset + stride * block_h + block_w];
barrier(CLK_LOCAL_MEM_FENCE);
{
int i;
int uiSum = 0;
for( int i = 0; i < block_h; i++ )
{
计算sad
}
{
比较最小SAD 保存bestcost
}
if((local_y ==0) && (local_x == 0))
{
int best_sad = mv_cost[local_y*2*SearchRange*3 + local_x*3 + 2];
int best_mvx = mv_cost[local_y*2*SearchRange*3 + local_x*3 + 0];
int best_mvy = mv_cost[local_y*2*SearchRange*3 + local_x*3 + 1];
outputBuf[(lcu_y * get_num_groups(0) + lcu_x)*3 + 0] = best_mvx;
outputBuf[(lcu_y * get_num_groups(0) + lcu_x)*3 + 1] = best_mvy;
outputBuf[(lcu_y * get_num_groups(0) + lcu_x)*3 + 2] = best_sad;
//printf("\nxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx = %d, y = %d, sad = %d",best_mvx, best_mvy, best_sad);
}