[置顶] ICTCLAS2014 C++版本 的使用方法
这个工具是什么?先看看他的官方介绍吧:
NLPIR汉语分词系统(又名ICTCLAS2013),主要功能包括中文分词;词性标注;命名实体识别;用户词典功能;支持GBK编码、UTF8编码、BIG5编码。新增微博分词、新词发现与关键词提取;张华平博士先后倾力打造十余年,内核升级10次。
虽然介绍时候还是用的ICTCLAS2013,但是你会发现下载的版本里面dll是2014版本的。以前的博客可能不能成功使用。
ICTCLAS2013 Java版本的使用方法 请点击点击打开链接
ICTCLAS2013 c++版本的使用方法 请点击点击打开链接
一,先下载2014版本的c++版本:点击打开链接
此本版下面后的文件名字:20131115123549_nlpir_ictclas2013_u20131115_release.zip
解压文件后看到很多文件的:
![[置顶] ICTCLAS2014 C++版本 的使用方法_第1张图片](http://img.e-com-net.com/image/info5/ac4163093657412bad9d48f25904d4d2.jpg)
图1. rar解压后的文件图
但是2014版本中的bin文件夹打开时这样的:
图2. 图1中bin文件夹打开后看到的图
注意: 此dll是2014版本的。
二,自己新建一个c++工程,在vs2010建名为ICTCLAS2014的工程(不要使用预编译头)。
建好后如图所示:
图3. 工程ICTCLAS2014根目录下的文件
三,将图1中的example-c文件夹(是整个文件夹,下同)复制到图3的ICTCLAS2014目录下,并且在ICTCLAS2014源文件中导入,同时将ICTCLAS2014.cpp文件下的_tmain函数注释掉。如图:
图4. 导入example-c文件夹下的Example-C.cpp文件
![[置顶] ICTCLAS2014 C++版本 的使用方法_第2张图片](http://img.e-com-net.com/image/info5/4d3f6f63baf04b719cb9a447162be007.png)
图5. 导入完成后,工程下面出现Example-C.cpp文件(图中红底线示意)
四,将图1中的include文件夹复制到图2的工程根目录下。否则,会出现下图所示错误。
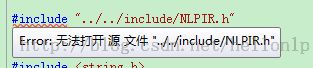
图6. 复制include文件夹之前工程提示“无法打开源文件 "../../include/NLPIR.h"
![[置顶] ICTCLAS2014 C++版本 的使用方法_第3张图片](http://img.e-com-net.com/image/info5/71d69cf4043b4f5ca8e52fa4c37af0c2.jpg)
图7.复制include文件夹之后,工程ICTCLAS2014根目录下的文件
五,
1>将图1中的lib文件夹复制到图2工程根目录下面,并且在项目->添加现有项中导入lib下的NLPIR.lib文件。
![[置顶] ICTCLAS2014 C++版本 的使用方法_第4张图片](http://img.e-com-net.com/image/info5/eba5d27da494433ba0a2fea5b7c8273e.jpg)
图8. 导入lib文件夹下NLPIR.lib文件
2>将图2中ICTCLAS2014文件夹下的NLPIR.dll文件复制到工程根目录下ICTCLAS2014目录下Debug目录下[注意:没有Debug目录,请将工程编译一次]。
注意:如果机器是32位的,请去下载32位对应的dll。
3>注释掉Example-C.cpp文件第9行语句。
#pragma comment(lib, "../../bin/NLPIR.lib") --> // #pragma comment(lib, "../../bin/NLPIR.lib")
(不要问我为什么,我只能告诉你,我也不知道。在我实验中不注释掉这句话,依然报错 fatal error LNK1104。)
六,将图1中的Data文件夹和test文件夹复制到图3工程根目录下。
![[置顶] ICTCLAS2014 C++版本 的使用方法_第5张图片](http://img.e-com-net.com/image/info5/6e0c244207a9412cb739f0e6f0e6b4db.png)
图9, 步骤六完成后工程根目录下的文件
七,不做修改,编译后,运行工程。
失败了!!!!!!
![[置顶] ICTCLAS2014 C++版本 的使用方法_第6张图片](http://img.e-com-net.com/image/info5/4c43b08bf31d4f7cb6fbeefedd766877.jpg)
图10, 编译,运行未做任何修改Example-C.cpp代码的结果。
解决方法:
将Example-C.cpp的322行注释掉,并且将323行注符号删除。修改后的两行如下:
testNewWord(GBK_CODE);
//testNewWord(UTF8_CODE);
编译后运行程序。成功了,如图:
![[置顶] ICTCLAS2014 C++版本 的使用方法_第7张图片](http://img.e-com-net.com/image/info5/663c32b0def64cb48f4b7c011fa23e8c.jpg)
图11,修改322行和323行后运行结果,识别新词。
如果想试试分词,继续行动。将327行注释符号去掉。编译,运行。
可惜的是......ICTCLAS INIT FAILED! 如图:
![[置顶] ICTCLAS2014 C++版本 的使用方法_第8张图片](http://img.e-com-net.com/image/info5/181c607a8aaa4c16a1a5ec7033baf601.jpg)
图12, 同时开启识别新词和分词函数的失败结果图。
不要泄气,注释掉322行,然后修改第80行代码:
if(!ICTCLAS_Init())//数据在当前路径下,默认为GBK编码的分词 ==》 if(!NLPIR_Init("..",0)//数据在当前路径下,默认为GBK编码的分词
注意:此处的NLPIR_Init("..",0)中的0是表示GBK编码。
编译,运行。 成功!!
图13,运行成功图。
注意事项:
1. 如果细心你会发现在图2中ICTCLAS2014文件夹中有一个20131213.err文件。

图14,ICTCLAS2014文件夹中文件,下划线为20131213.err文件
打开20131213.err文件
图15,20131213.err文件内容
此处的报错和图10报错是同一个类型(图10报错时候log文件也显示这个)。
2,testNewWord(GBK_CODE) 和 SplitGBK(sInput)同时使用报错。错误类型还未知。