java虚拟机运行机制
首先简单阐述下解释型语言和编译型语言的联系与区别。
编译型语言是通过编译器将程序编译成目标机器所能识别的机器码,而解释型语言不需要编译过程。由该语言的解释器读取脚本,按照语法规则进行解释,然后调用解释器内建的命令(或者库函数)。例如,C语言的printf()函数经过静态编译后,printf()所需的所以代码都以机器码的形式写入可执行文件中,shell在执行程序时,在指定路径搜索该文件,然后加载器(Loader)加载该程序的ELF文件到内存中,跳转到程序入口,将控制权交由该程序。动态编译的情况有些不同。由于printf()是很常用的函数,系统将常用函数集中起来做成库,当我写一个Myprintf()函数时调用printf() 时,动态编译后形成的ELF文件不会包含printf()相关的代码,但是会有些信息告诉系统:“我的程序将会调用printf(),因此我需要printf()的地址”。加载ELF文件后,首先运行动态连接器(ldd),ldd知道程序依赖的动态库,系统中如果没有加载该动态库,就会通知系统加载该库,并把库函数的入口地址绑定到程序需要的地方,然后跳转到程序入口地址,开始运行程序。这里,我们所写的程序一经编译,就变成特定机器的机器码和一些附属信息(符号表,地址,变量值等),然后通过系统加载运行机制就变成“动态程序”——进程。
解释型语言的执行过程离不开解释器,python,perl,ruby等等。所以脚本的第一行一般是#/usr/bin/×××。×××代表了各语言相应的解释器。脚本一般由表达式(expression)和Block of expressions组成,解释器首先要做的就是分析并理解表达式结构,形成“执行序列”。这个“执行序列”是中立的,不针对任何native machine(呵呵,我起的名字,相对于viutural machine。),所以“可移植性”高。这里不用“字节码”代替“执行序列”是考虑到在jvm中有字节码的概念,他们之间有显著的不同。决定执行序列是解释器最主要的作用。假设,python输出的函数为python_print(),那么python解释器在“解释”脚本时遇到这个表达式就将调用系统的print()函数执行输出操作。你也可以把脚本理解成高级配置文件,这个文件指导python解释器如何运行,解释器内部已经制订了“如何”运行的若干规则。
JVM执行java程序要比上述两个复杂,因为它已经被称作machine了。下图是JVM的结构框图。主要包含:垃圾回收器,类加载子系统,执行引擎,运行时数据区等。
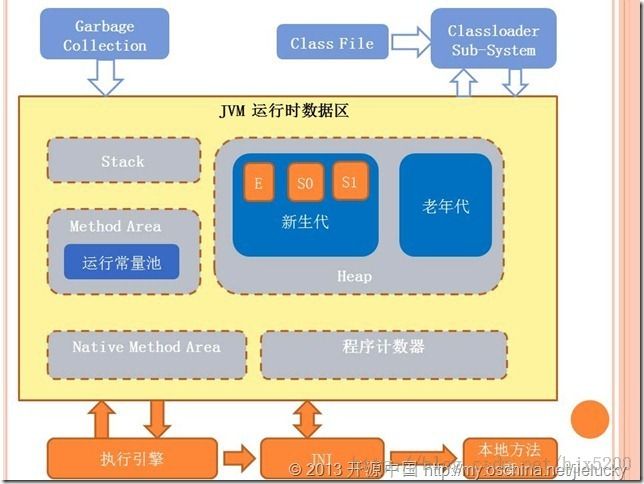
如果能较详细的理解这幅图,那么JVM的运行机制就大体过关了。下面试着分析上述各模块的功能和它们之间的相互联系。
类加载过程
java程序经过编译后形成*.class文件,内含JVM的字节码。通过类加载器将字节码(*.class)加载入JVM的内存中。类加载过程主要涉及JVM的方法区。方法区存储了类的类型信息,如运行时常量池(Runtime Constant Pool)、字段和方法数据、构造函数和普通方法的字节码内容、还包括一些在类、实例、接口初始化时用到的特殊方法。这些都可以看作静态信息,每次方法被调用,在java栈中保持该方法的临时变量,当方法返回时,java栈自动撤消。JVM将类加载过程分成加载,连接,初始化三个阶段,其中连接阶段又细分为验证,准备,解析三个阶段。
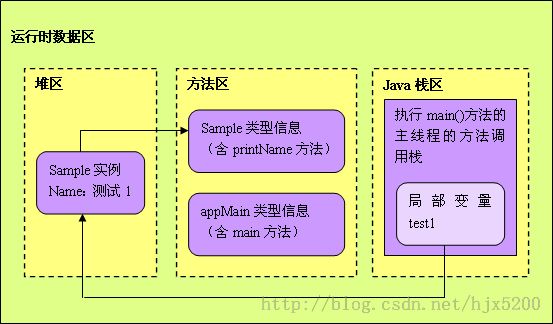
1、Java程序开始运行前,类加载器加载类名.class,将类信息保存在运行时数据区的方法区。方法区是线程共享的,里面存储的信息有一个共同的特定就是整个程序中是唯一的。所以有关class的版本号,常量池,方法的字节码等。而类的非静态域则是对象相关的,存储在堆区,其引用(类似指针)存放在栈区。下面的例子,编译后产生AppMain.class,JVM加载AppMain.class后,将字节码解析成运行时数据结构。类的静态变量和方法存放在方法区。JVM主线程执行main()函数,new一个Sample的对象。
AppMain.java
public class AppMain //运行时, jvm 把appmain的信息都放入方法区
{
public static void main(String[] args) //main 方法本身放入方法区。
{
Sample test1 = new Sample( " 测试1 " ); //test1是引用,所以放到栈区里, Sample是自定义对象应该放到堆里面
Sample test2 = new Sample( " 测试2 " );
test1.printName();
test2.printName();
}
}
这时就会到方法区寻找Sample的类型信息,发现还没有加载,就会加载Sample.class。在堆中分配内存并建立一个Sample对象,它的引用是test1。堆中的对象持有class的引用,即指向方法区中类的类型信息的地址。test1是main()函数的私有变量所以保持在主线程栈上,它执行堆中的Sample对象。
Sample.java
public class Sample //运行时, jvm 把appmain的信息都放入方法区
{
private name; //new Sample实例后,name引用放入栈区里,name对象放入堆里
public Sample(String name)
{
this .name = name;
}
public void printName() //print方法本身放入方法区里。
{
System.out.println(name);
}
}
下图是运行时的示意图
连接过程
2、连接过程主要是在加载之后、初始化之前的一些准备工作。他们有很多交叉的地方。连接时需要验证字节码是否符合java规范,数据类型是否有效,继承和实现是否合乎标准。在这个阶段还为类的静态变量分配空间,并将其设置成JVM的默认值。对于非静态变量则不会赋值。
在jvm中各类型的初始值如下:
- int,byte,char,long,float,double 默认初始值为0
- boolean 为false(在jvm内部用int表示boolean,因此初始值为0)
- reference类型为null
- final static基本类型或者String类型,则直接采用常量值(这实际上是在编译阶段就已经处理好了)
这一阶段还需要出发解析过程。JVM对于每个加载的类都会有在内部创建一个运行时常量池(参考上面图示),在解析之前是以字符串的方式将符号引用保存在运行时常量池中,在程序运行过程中当需要使用某个符号引用时,就会促发解析的过程,解析过程就是通过符号引用查找对应的类实体,然后用直接引用替换符号引用。由于符号引用已经被替换成直接引用,因此后面再次访问时,无需再次解析,直接返回直接引用。