Linux2.6物理内存管理
一、物理内存的分配
1.Linux2.6支持非一致内存访问(NUMA),被分为一节点,每一个节点内是UMA
80x86系统不使用NUMA,因为只有一个节点
每个节点分为3个管理区:ZONE_DMA , ZONE_NORMAL , ZONE_HIGHMEM
2.3个管理区的分布与特点见表格:
| ZONE_DMA | ZONE_NAORMAL | ZONE_HIGHMEM | |
| 物理地址范围 | 低于16MB的物理页框 DMA不经过MMU提供的地址映射,导致(1)外部设备直接访问物理的地址(前16MB)(2)DMA不能依靠MMU将连续的线性地址映射到不连续的物理地址。因此前16MB地址的分配与寻址需要特殊处理。 |
高于16MB,低于896MB的物理页框 上限不一定是896MB,这只是一个最大值 若物理内存高于1G,就无法访问(因为内核态的线性地址只有1G),因此从线性地址中取最高128MB,用于间接映射,前896MB用于线性映射,因此这个值是896MB不是1G |
高于896MB的物理页框 与线性地址最高128MB建立非线性的映射 64位硬件平台上,ZONE_HIGHMEM是空的。因为可使用的线性空间远大于可安装的RAM大小 |
| 使用方式 | (1)可由老式的基于ISA的设备通过DMA使用 (2)可由CPU直接访问,线性地址0xc0000000=物理地址 |
可由CPU直接访问,线性地址0xc0000000=物理地址 | 不能由CPU直接访问 |
| 映射方式 | 线性映射到线性地址第4个G的前16MB空间 | 线性映射到线性地址第4个B的16-896MB空间 | 非线性地映射到线性地址第4个G的剩余空间,见“高端内存的页框的内核映射” |
3.Linux内核安装在从物理地址0x00100000开始的地址(ZONE_DMA),如图所示
图中上面的标号是页框号,不是物理地址。
这是前3MB的RAM,从物理地址0x00100000开始,依次是内核代码、内核数据。

二、内核页表
1.什么是内核页表?参见Linux2.6虚拟内存管理
主内核页全局目录的最高目录项部分作为参考模型,为系统中每个普通进程对应的页全局目录项提供参考模型
2.内核页表的初始化
(1)第一阶段:创建一个临时页表
(2)第二阶段:内核充分地利用剩余的RAM并适当地建立分页表。
3.建立临时内核页表
分析:
(1)页面大小为4KB + 一个页表项指向一个页面 + 一页页表有1024个页表项 ------> 一页页表可以映射4MB内容
(2)假设内核初始化所需要的内容都能容纳于RAM的前8MB
内核初始化所需要的内容 = 内核使用的代码段、数据段 + 临时页表 + 128KB的内存范围(用于存放动态的数据结构)
(3)(1)+(2)-----> 需要2页临时页表
建立映射:
(1)临时页全局目录存放在swapper_pg_dir中,其中第0、0x300指向第一个页表,第1、0x301指向第二个页表
(2)临时页表存放在上图的_end开始的位置,这两页页表指向前8MB的物理空间
4.建立最终内核页表
.(1)RAM<896MB -----> 不激活PAE,没有ZONE_HIGHMEM
物理地址与3G以上线性地址建立线性映射,即线性地址-0xc0000000=物理地址
(2)RAM > 896MB && RAM < 4096MB
前896MB的物理地址与3G以上的物理地址建立线性映射,即线性地址-0xc0000000=物理地址
896MB-----4096MB的物理地址与3G+896MB-----4G的空间建议非线性映射,见“高端内存的页框的内核映射”
(3)RAM>4086MB ----->激活PAE,使用三级分页模型
(4)内核空间与物理RAM的映射关系,图见Linux地址映射(1)--线性映射与非线性映射
四、对于大片连续内存的管理---伙伴系统
1.为什么要引入伙伴系统?
(1)能够满足大片连续的内存分配
DMA忽略分页单元而直接访问地址总线,因此,所请求的缓冲区必须位于连续的页框中
(2)能够解决外碎片问题
2.原理
把所有的空闲框分为11个块链表
每个块链表的大小分别包含大小为1,2,4,8,16,32,64,512,1024个连续的页框
不同管理区使用不同的伙伴系统
分配时,选择能满足需求的最小的连续页框的链表,取分,分配,把剩下的链入相应大小的队列
回收时,如果可以就合并
四、对于小内存区的分配和管理 ----- slab
见Linux2.6为数据结构分配内存-slab
五、为用户空间分配一个物理内存的过程:
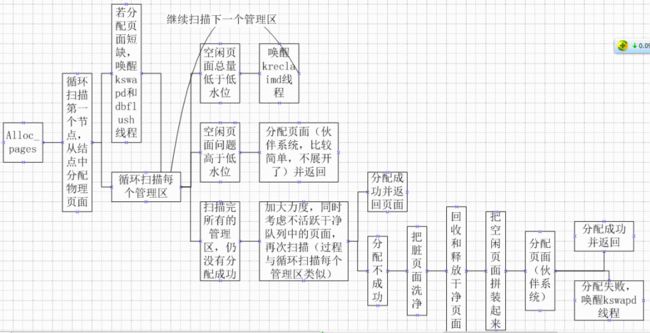
所有直线箭头都是从左向右,有一个弧线箭头是往回指的
六、物理页面的回收
1.物理页面分配的来源:
(1)当前尚存的空闲页面
(2)不活跃的干净页面
(3)不活跃的脏页面
2.kswapd的作用:
(1)预先找出若干页面,且将这些页面的映射断开,使这些页面从活跃状态转入不活跃状态
(2)把已经处于不活跃的脏页面写入交换设备,使它们成为不活跃的干净页面,或进一步回收成为空闲页面
3.kswapd需要在代码中显示地调用schedule()来进行调度,因为:
每当CPU结束一次系统调用或中断服务,从系统空间返回时,就会检查调度标志。kswapd是个内核线程,永远不会回到用户空间,就可能会绕过这个机制而占住CPU不放,所以只能靠自律,自己在可能需要运行较长时间的操作之前调用schedule()