spring batch学习笔记之领域模型
Job&JobInstance&JobExecution
spring batch中对job的定义是:job是唯一的,由一系列有序步骤组成的,并可以按步骤从头到尾运行的实体。
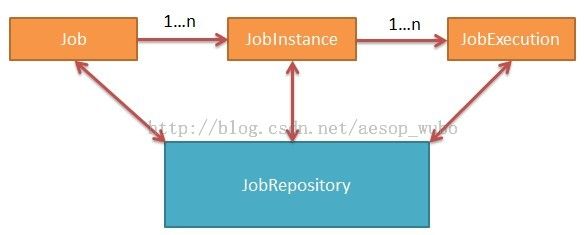
在运行job之前需要先创建或者获取一个job实例,job实例由job和其需要的参数组成,每个job实例可以执行多次。为了保证job执行失败或者抛出异常后可以重新执行,需要保存job的上下文,job上下文包括job参数,执行状态等信息,这些信息都是持久化在被称为jobRepository中。下图展示了job、jobInstance、jobExecution之间的关系:
Step&StepExecution
由job的定义可知,job由一系列有序step组成,体现在配置如下:
<job id="userJob" xmlns="http://www.springframework.org/schema/batch">
<step id="addAgeStep" next="archiveUserStep">
<tasklet>
<chunk reader="userReader" processor="userProcessor" writer="userWriter" commit-interval="5"
retry-policy="retryPolicy"/>
</tasklet>
</step>
<step id="archiveUserStep">
<tasklet ref="archiveUserTasklet"/>
</step>
</job>step通过next属性来维护step之前的顺序,和job一样,每个step含有一个stepExecution。
spring batch提供了常用的几种step:
FlowStep:这是一种可以并行执行的step
JobStep:这种实现可以把job当成一个step来看待
PartitionStep:这种step可以对数据进行拆分然后并行处理
TaskletStep:这种step可以执行一个tasklet,tasklet下面介绍
tasklet
tasklet代表step的一种处理策略,配置如下:
<step id="addAgeStep">
<tasklet>
<chunk reader="userReader" processor="userProcessor" writer="userWriter" commit-interval="5"/>
</tasklet>
</step>可以把chunk看做是数据库中的多行记录或者文件的多行数据,每个chunk对应一个reader,一个processor,一个writer。执行流程如下:
ItemReader
itemReader表示tasklet的数据源,可以来自数据库、文件,也可以来自消息中间件等。spring batch提供了几种itemReader,其中最常用的是FlatFileItemReader。它代指各种类型的文件,包括表格。配置这个reader时需要通过resource属性指定文件位置,lineMapper来指定每列的映射情况。
ItemProcessor
这是对业务处理的一个抽象,用户可以基于这个接口扩展自己的业务逻辑。其实现类CompositeItemProcessor可以为一个tasklet指定多个processor。
ItemWriter
是对处理结果的一个抽象,可以将处理结果写入到文件中(FlatFileItemWriter),也可以执行SQL保存到DB中(JdbcBatchItemWriter)等。