C For Linux之内存访问-内存简介
1、 内存
1.1、 计算机为什么需要内存
存储器是计算机系统中非常重要的组成部分。计算机中的存储器分为两类:内存储器的外存储器(也叫辅助存储器)。
所谓外存储器在PC机中一般指硬盘、U盘、光盘等,而在嵌入式系统中一般使用nandflash、SDCard等基于flash技术的存储器。他的优点是容量大、单位存储成本低、掉电不丢失。缺点是读写速度慢(这个慢是相对于CPU的速度来说的)、不能直接寻址(如CPU需要通过nand控制器来读写外部nandflash)。因为容量大而且掉电不丢失,因此外存储器主要用来存储静态文本数据,如安装好的操作系统映象、文本文档、串行化保存的数据等。一般提到storage、disk等词汇都指的是外存储器。
而内存储器(一般简称内存)一般都是RAM(random access memory),如PC机平台广泛使用的DDR SDRAM、嵌入式系统常使用的SDRAM、单片机中使用的SRAM等都可以成为内存。RAM器件的缺点是掉电会丢失内容,因此不能用于长期存储信息。但它的优点是速度快(尽管比CPU还是慢很多,但是相比外存储器已经快太多倍了),并且CPU可以通过地址线直接寻址RAM器件的存储单元,因此内存是CPU执行任务(数据运算、程序执行等)的“演练场”。
譬如在嵌入式linux系统中,操作系统映象文件zImage(kernel image,即可被引导的二进制内核代码)被烧录到nandflash(外存储器)中保存,系统启动时bootloader将zImage复制到内存中,之后操作系统一直在内存中运行。
当我们运行应用程序的时候也是如此。程序的静态可执行文件放在文件系统中,而文件系统在外部存储器中。当我们使用./a.out运行可执行文件时,可执行程序文件先被读取到内存中特定区域然后在内存中(以进程的形式)运行。
上大学时(偶尔)都会去阅览室吧,进了阅览室先从书架上拿下自己感兴趣的图书,然后拿到阅读桌上慢慢看。如果把你看作是CPU,那么书架就是外存储器,而阅读桌就是内存。
仔细品味品味,是不是有点感觉了?是的,外存储器就是我们计算机系统的“仓库”,而内存则是计算机执行任务的“工场”。所以,与静态文本(文件、编译好的可执行程序、内核映像等在未被运行前都是静态文本)相关联的是外存储器(storage),而与运行中的程序、正在被操作的文本相关联的则是内存(memory,RAM)。CPU执行任务时以内存为场地,程序中临时变量的分配与销毁(与栈有关)、文件和数据的暂存与处理(从外存读入到内存中缓冲区)都是在内存中完成的。
1.2、 内存地址
上文说过,常用的内存有SDRAM、SRAM、DDR等种类。各种内存因为物理原理的不同而表现出不同的特性(容量、速度、操作时序等)。譬如SRAM容量小、速度快、常被用作单片机内部RAM,而SDRAM容量大、操作接口复杂(CPU需要专用的SDRAM控制器),经常用作嵌入式系统中的内存,DDR的操作特性与SDRAM类似,只是速率要比SDRAM高,PC平台与一些CPU主频较高的嵌入式场合都会选择DDR作为内存以为CPU提供较高的内存访问效率。
编程时,更多的是从逻辑层次、以地址的方式来访问内存。因此无论何种内存,对于我们写程序来说都是一致的。在逻辑层次上,我们把内存抽象成这样一种物质:
a) 内存由一个个的存储单元组成,每个单元大小为1个字节(注1:本书中均以Byte,B来表示字节)。这里我们先不提位访问和字访问形式,下文会有专门章节讲述。
b) 内存中每个单元都有一个唯一的地址来标识该单元。地址是CPU识别、定位内存的唯一凭证(C语言中的变量名、汇编中的标号等实质上都是内存地址)。打个比方,整个内存是一栋大楼,里面由一个一个的小房间组成,每个小房间就是内存这栋大楼的一个字节单元。当我们想去大楼的某个特定房间时我必须知道房间号(譬如408),当我想访问内存的某个单元时我则必须知道它对应的内存地址。用地址来标识内存是一种很好的抽象,因为它屏蔽了内存的物理细节,你根本不必考虑内存中各个单元是线性排列的还是环形排列的,也不必管物理内存是一层一层的还是一块一块的,总之你只要提供正确的内存地址就可以了。就好象你只要知道你要去的房间号,根本不用管大楼的内部结构、乘电梯还是走楼梯等细节也能找到你要去的房间。当然了,房间号不能有重复的。必须的,内存地址也不能有重复,上帝决定了一个内存地址只能对应唯一的一个物理内存字节单元。
c) 逻辑上可以认为内存是线性分布的(其实是因为作为内存地址的数字是线性分布的),事实上你所能看到的几乎所有讲述中内存都被描绘成一个长条,这让我想起了国粹麻将,实际上打麻将时你面前的牌摆成一条长城的样子逻辑上就是内存的真实写照,每个麻将牌就是一个内存单元,依次相连。
相信你现在对内存已经有了一些了解。Ok,那我们来考虑在程序中如何使用内存。程序是用编程语言写的,那么什么是语言呢?语言是人与人之间沟通思想、传递信息的媒介,而编程语言是人与机器(CPU)之间沟通信息的媒介。机器有自己的语言系统,即CPU的指令系统,除此之外它什么也听不懂。CPU的指令是什么呢?只是一串由1的0组成的编码而已。是的,既原始又麻烦枯燥、想来让人不寒而栗。听说最早期的程序员就是在纸板上用打孔机打出一串串的1和0来编程的,在我看来这份工作的难度不亚于让你“与牛聊天”、“跟树对话”,可见先辈程序员们之天赋异秉。
后来有了汇编语言情况就好很多了,程序员的要求开始由天才降低为人才。汇编语言借助汇编器来完成工作,这使得程序员可以使用汇编器可以识别的符号来编程,汇编器会在稍后将符号翻译成机器码。这样虽然CPU还是只认识那些1和0组成的长串,但是借助于汇编器程序员终于可以用人类看得懂的语言来编程了。这是一个长足的进步,因为它引入了“符号”这个概念。在汇编语言中,汇编指令、伪指令、标号这些都是符号,这些符号是给汇编器看的,汇编器会识别它们,并决定它们在最终的可执行文件中如何用1和0的长串来表达。
那么程序员如何使用编程语言访问内存呢?答案是CPU的指令集内有专门用来访问内存的指令。譬如ARM汇编中有LDR、STR、LDM、STM等内存读写指令,可以完成内存与寄存器的数据交互。在访问方式上还有所谓直接访问、间接访问等多种寻址模式(在ARM汇编访问内存一章有详细介绍),但是千变万化、原则只有一个,那就是提供正确的内存地址给汇编指令,这样CPU就可以完成相应地址的内存读写。譬如以下两句汇编指令就完成了读取内存地址0x30000000处连续4字节内存单元到寄存器中。
LDR R0, =0x30000000 // 将R0赋值为0x30000000
LDR R0, [R0] // 读取内存地址0x30000000处的内容放入R0
至于C语言等高级语言,它们的编译器更加智能、功能也更加强大。大多数时候使用内存并不会直接指出具体的内存地址(如上例的0x30000000),而是以变量名、函数名等符号地址的形式来使用,这些符号地址稍后在编译链接的过程中会被转换为具体的内存地址提供给CPU的机器指令来执行内存读写。
可见,CPU访问内存的方式就是通过内存单元的地址。汇编语言还是C语言,标号、数字形式的地址、还是变量名、函数名,这些都只是编译器提供的编程形式的不同,其实质都是为了指定一个具体的内存地址。
1.3、 内存位宽和内存对齐
前文说过,内存单元是以字节为单位的,每个字节单元有自己的地址,CPU通过该地址来访问这个内存字节。因此内存地址0x30000000和0x30000001之间相差1字节,这就是内存的自然位宽。
提到位宽,就不得不提一下CPU的数据位宽。一般来说,一款CPU的位宽是由ALU位宽、通用寄存器位宽、数据总线位宽三个值中最小的一个来决定的。也就是说,位宽描述了CPU一次运算所能处理的数据位数。譬如MCS-51系列单片机为8位CPU,所以其一次处理8bit(即1个字节)数据,而ARM系列为32位CPU(有消息说ARM会在2014年推出首款64位CPU)因此其一次处理32bit数据。
针对不同位宽的CPU平台,取得最佳内存访问效率的方法是让内存位宽和CPU位宽相同。譬如ARM在操作32位内存时一次可以读写4字节(使用LDR,STR),而在16位内存时需要2次才能读写4字节数据(LDRH,STRH),这样访问效率就差了很多。
那么32位宽的内存和16位、8位宽的内存有什么区别呢?请看下图。
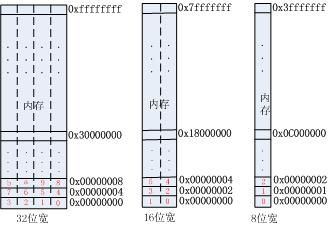
图中的长方形表示逻辑上的内存,横线和竖线(包括虚线)将内存从逻辑上分成一个一个的小块。每一块大小为1个字节,方块内的红色数字表示该内存单元的地址。可见,无论是32位内存还是8位内存,内存地址都是以字节为单位的。请原谅我不厌其烦的唠叨——是的,似乎很简单,但是这个真的很关键。
a) 首先这意味着我们以地址访问时所能精确到的最小单元就是字节,换句话说我们没法精确到要去访问某个字节单元内的某个bit(关于位访问下文会有专门讨论)。
b) 其次,对于32位宽的内存我们可以用1个地址来访问连续的4字节内存单元,这就是所谓的字地址(图中内存右侧的黑色粗体数字即是字地址)。譬如对于内存地址0,如果作为字节地址它代表的是字节地址为0的那个内存单元。而如果作为字地址,它代表的是字节地址为0、1、2、3的4个连续内存单元,这4个内存单元合称为一个字(word)。我们在访问内存时只是提供了一个数字作为地址,那么究竟访问的是字节还是字呢?本质上是由我们访问内存时使用的机器指令决定的。譬如在ARM汇编中使用LDR指令访存时地址将被解释为字地址,而使用LDRB指令访存时地址被解释成字节地址。而使用C语言访问内存时,变量的数据类型就成了如何解释变量所代表的内存地址的关键。
至此我们介绍了内存位宽,并且引入了字节地址、半字地址、字地址(注:再次强调,我这里的描述都是基于32位ARM体系的)几个概念。总结一下:所有的地址本质上都是一个数字,这个数字成为首地址。不同在于,对于字节地址,它说代表的内存空间为首地址开始的一个字节。而对于半字地址,它所代表的内存空间为首地址开始的2个字节(半字)。对于字地址,它所代表的内存空间为首地址开始的4个字节(字)。下图描述了首地址为0x33f80000时三种地址所表示的实际内存单元。
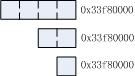
什么是内存对齐呢?首先要认识到,位宽是内存器件本身的一个物理属性。对于32位宽的内存器件,其字节地址为0、1、2、3的四个内存单元在逻辑上被整合成一个字从而可以被当作字来单周期(这里的周期指的是内存访问周期)访问。必须指出,这个整合是器件的物理特性提供的而不是无条件的。随便在内存中找4个字节单元是不能当成一个字来字访问的,这四个字节必须满足两个条件:一是四个单元的字节地址相连,二是最小的那个字节地址(组成字后的字地址、起始地址)必须被4整除。
若选出的4个单元字节地址不相连(即不满足条件一),则这4个字节根本不能组成一个字。若满足条件一则可能的排布有4种,如上图所示。图中每种排布的4个字节地址都连续分布,因此都组成了一个字。但是只有第一种同时满足条件二,因此只有第一种可以进行字(单周期)访问。其他三种情况下都要耗费多个周期才能间接完成字访问(一种惯用的做法是以字节为单位访存4次再拼接出一个对齐的字,参见llinux源码lib/string.c文件中memmove函数的实现)。
上图中第一种情况所示即为对齐访问,其他三种称为非对齐访问。可见,内存对齐访问时可以单周期字访问从而取得最佳的仿存效率,而非对齐访问却需要多次仿存及运算才能完成字访问(使用非对齐访问的一个理由是为提高内存利用率)。以上我们描述的是32位系统中的字对齐,半字对齐的概念和字对齐相类似,不同的是半字对齐要求起始地址被2整除。
1.4、 大小端模式
大小端模式是字地址的使用带来的引申问题。譬如我要将十六进制数0x12345678放到内存中一个字单元来存储,可能的存储方式有两种,如下图所示:

首先引入两个概念:MSB(Most Significant Bit)和LSB(LeastSignificant Bit)。MSB用来描述二进制数的最高加权位,类似于十进制数的最高位。LSB则用来描述最低加权位,类似于十进制数的最低位个位。如果将十六进制数0x12345678以字节为单位分割,则包含MSB的字节内容为0x12,而包含LSB的字节内容为0x78。从上图可以看出,大端模式(Big-endian)即MSB存储在内存地址的低字节处的存储方式,而小端模式为LSB存储在内存地址的低字节处的存储方式。
这两种存储方式本身并无优劣之分,在效率上也无差异,实际使用时只要保证CPU的大小端模式和内存中数据的大小端模式一致就可以。有些CPU支持小端模式,如Intel系列微处理器。而另外一些CPU支持大端模式,如Motorola公司的微处理器。还有一些CPU则可配置为支持大端模式或小端模式,典型的如ARM9 S3C2440。
另外值得一提的是,大小端模式的概念不只在内存的字存储中用到,在串行通信中也会用到,甚至Big-endian的Little-endian这两个词最早的软件搭上关系也是源于在串行通信中的大小端选择。问题其实不难理解,一条通信消息可能有多个字节(就好象一个十六进制数有多个自己长一样),而串行通信时一次只能传输一个字节(准确的说串行通信时一次只能传输一个bit,一帧才能完成一个字节的传输),因此当多个字节的一条信息被串行传输时,发送顺序是从MSB到LSB还是从LSB到MSB就造就了Big-endian和Little-endian两种字节序。
词源:据Jargon File记载,endian这个词来源于Jonathan
Swift在1726年写的讽刺小说 "Gulliver's Travels"(《格利佛游记》)。该小说
在描述Gulliver畅游小人国时碰到了如下的一个场景。在小人国里的小人因为非常
小(身高6英寸)所以总是碰到一些意想不到的问题。有一次因为对水煮蛋该从大的
一端(Big-End)剥开还是小的一端(Little-End)剥开的争论而引发了一场战争,
并形成了两支截然对立的队伍:支持从Big-End剥开的人Swift就称作Big-Endians
而支持从Little-End剥开的人就称作Little-Endians……(后缀ian表明的就是支持
某种观点的人:-)。Endian这个词由此而来。
1980年,Danny Cohen在其著名的论文"On Holy Wars and aPlea for Peace"
中为了平息一场关于在消息中字节该以什么样的顺序进行传送的争论而引用了该词。
该文中,Cohen非常形象贴切地把支持从一个消息序列的MSB开始传送的那伙人叫做
Big-Endians,支持从LSB开始传送的相对应地叫做Little-Endians。此后Endian这
个词便随着这篇论文而被广为采用。 --(内容来自于网络)--
1.5、 内存的位访问
上文一直在强调,内存地址的最小单位是字节,因此我们单次访问内存中所能读写的最小单位也是字节。如果你只想更改某个字节中的一个bit,你不得不先读出整个字节,然后使用与、或等位运算更改特定bit,最后再将更改过的完整字节重新写入字节地址内。大多数系统中都是用类似手段间接实现位访问的,如ARM驱动程序中寄存器操作部分大量充斥着此类代码。
除了硬件寄存器读写时需要位操作以外,bool类型变量的使用也使人们想到位运算。很多时候我们会需要定义bool类型变量(标志位、互斥锁等都是不错的示例),这种变量要么是0要么是1,本质上只需要1个bit内存就可以存储。如果硬件平台(主要是CPU的的仿存机制)支持内存位访问,那么使用1bit内存来存储bool类型变量可以大量节省内存。不过事实上大多数平台是不支持位访问的,所以对于bool类型变量,实际可选的存储方式有两种:一是使用一个字的32位来存储一个bool值,这样实际只是使用了该字内存的其中1bit,另外31bit实际上都浪费掉了;二是仍然使用1bit内存来存储,然后使用上段中提到的读-改-写三步策略实现间接的位操作。两种处理方式的各自特点如下表:
| 操作方式 |
使用32bit表示bool值 |
使用读-改-写实现间接位操作 |
| 优势 |
读写效率高 |
内存利用率高 |
| 劣势 |
内存浪费 |
读写效率低 |
| 总结 |
省时间,费空间 |
省空间,费时间 |
得益于半导体工业的发展,现代计算机的可用内存越来越大,因此在大多数情况下空间效率的重要性不如时间效率,这导致大多数平台都选择使用一个字来表示bool类型以追求极好的运行时效率。但是真正的位存储处理也是有的,C语言中的位段(bit-field)就是个实例。
难道就没有CPU提供真正的位访问能力吗?有,单片机就是个很好的示例。单片机因为本身内存容量很有限(像传统的8051只提供128字节内部RAM,现代32位单片机如STM32内存容量也是100KB量级),因此很在意内存使用率,提供位寻址能力以最大限度的利用内存就变得有意义起来了。可是我们之前说过,在计算机系统中地址默认是以字节为单位的,单片机系统中也不例外(想想为什么在需要位寻址的单片机系统中地址不以bit为单位呢?仅仅是为了兼容传统理念吗?)。那么单片机是如何实现位访问机制的呢?一句话,八仙过海,各有各的招吧。
8051提供128字节内存,地址为0x00-0x7f(8051汇编中习惯使用00H-7FH这样的表达方式),这些地址都是字节地址。使用MOV等普通指令读写内存也是一次操作1个字节。但是8051在字节地址20H-2FH这16个字节中提供位寻址能力,将这16个字节的总共16×8=128个bit进行按bit编址,于是乎字节地址20H-2FH的这16个字节内每个bit又有了一个额外的位地址,只要使用专用的位访问指令(如SETB、CLR)再提供位地址就可以对相应bit进行位操作。
| 字节地址 |
位地址 |
||||||||
| 7FH |
无位寻址能力 |
||||||||
| 7EH |
|||||||||
| . |
|||||||||
| 2FH |
7FH |
7EH |
7DH |
7CH |
7BH |
7AH |
79H |
78H |
|
| 2EH |
77H |
76H |
75H |
74H |
73H |
72H |
71H |
70H |
|
| . |
. |
. |
. |
. |
. |
. |
. |
. |
|
| 21H |
2FH |
2EH |
2DH |
2CH |
2BH |
2AH |
29H |
28H |
|
| 20H |
27H |
26H |
25H |
24H |
23H |
22H |
21H |
20H |
|
譬如SETB 2CH,指令执行完毕后位地址2CH、也即字节地址21H.4(.4表示该字节中的bit4)对应的bit被置位。又如CLR70H,指令执行完毕后位地址70H、也即字节地址2EH.0对应的bit被清零。
ARM Cortex-M3中提供了另一种位操作机制,称为位带操作。实现模型简单描述就是:首先从地址空间内选择一部分将要支持位操作的地址区域(譬如0x20000000-0x200fffff共1M字节),然后再挑选另外一些地址区域(譬如0x80000000开始的一段区域)作为位操作区域的地址映射区。在两个地址区域之间建立映射关系,即0x20000000开始处的一个bit对应0x80000000开始处的一个字,如下图
图中相同颜色的区域之间建立了位带映射关系,因此我们可以通过字访问0x80000000地址以达到实际位访问字节地址0x20000000处bit0的效果。具体实现细节可以参考《Cortex-M3权威手册》等书籍。