【SQL】MySQL的安装使用以及SQL语法简介
在 Java 的开发中,数据库的应用是非常必要的,下面,我们为Java对于数据库的应用做一些必要的准备工作。、
Java 对数据库的应用统称为 JDBC。
JDBC(Java Data Base Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。
先安装两个软件 MySQL 和 Navicat Premium(数据库管理工具)。
这两个软件在百度很容易搜索下载到的。在此就不提供下载链接了。
MySQL的安装
由于软件的安装比较简单,大部分都是直接点击下一步就可以了。
所以,在这里只提及需要留意的地方。

这个界面是选择安装类型,有“Typical(默认)”、“Complete(完全)”、“Custom(用户自定义)”三个选项。
如果需要更改安装路径的话,需要选择“Custom”。
建议不要放在与操作系统同一分区,这样可以防止系统备份还原的时候,数据被清空。
安装结束后,会出现如下界面:
这里是 MySQL 配置向导,将 “Configure the Mysql Server now”前面的勾打上,点“Finish”结束软件的安装并启动 MySQL 配置向导。
不用向以前一样,自己手动乱七八糟的配置my.ini了。
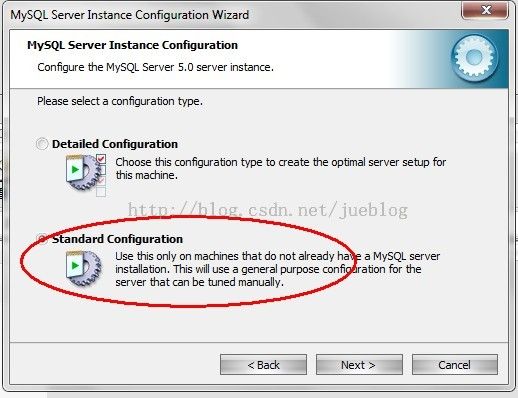
如下界面是选择配置方式,“Detailed Configuration(手动精确配置)”、“Standard Configuration(标准配置)”。
为了方便,我们选择标准配置。
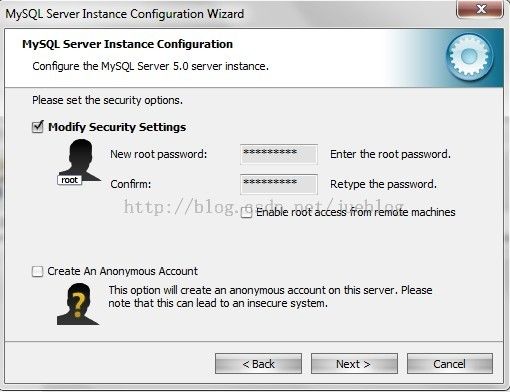
如下界面是设置 MySQL 的密码,我们在以后会经常用到的。
之后,一直选择默认,点击下一步,就可以完成MySQL的配置工作。
修改 MySQL 的默认编码类型
MySQL的默认编码类型为
Latin1。
Latin1 不支持中文,要支持中文需要把数据库的默认编码修改为 gbk 或者 utf8 。我们一般是修改为 utf8。
进入 MySQL 的安装目录,找到 my.ini 文件,以记事本的格式打开。
查找Latin1,并修改为 utf8 。
一个需要修改两个,如下所示。
修改好之后,保存退出即可。
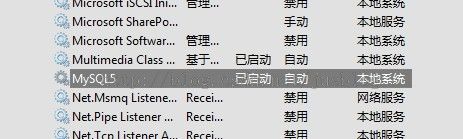
为了保存设置,我们需要重启 MySQL。
进入计算机的 【服务】,找到 MySQL ,退出并重新开启即可。
数据库管理工具Navicat Premium的简单使用
Navicat Premium 的安装非常简单,再次不再赘言。
现在,我们需要把Navicat Premium 和MySQL 连接到一起。
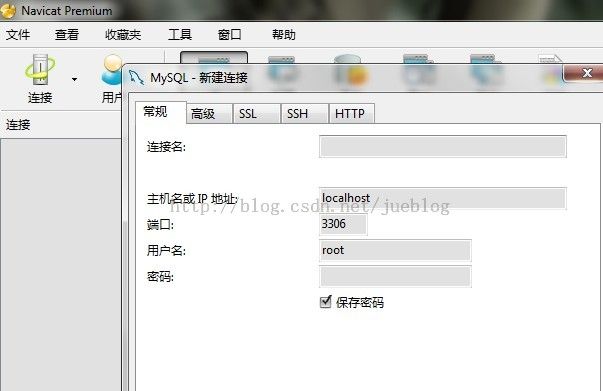
点击连接,输入刚刚在MySQL安装过程中设置的密码。连接即可。
开启之后,右键打开连接。
点击 Test 即可新建表单。
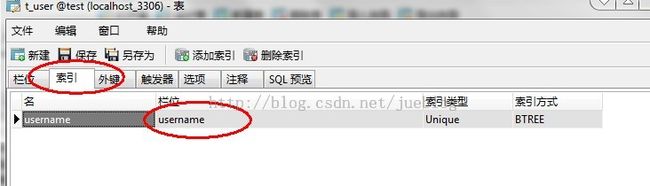
如果没有勾选允许空值,则为必填项。
设置为主键和引索的栏都不允许出现重复的内容。
建好表单栏目后,保存退出。
右击【打开表】,即可对表单内容进行编辑。
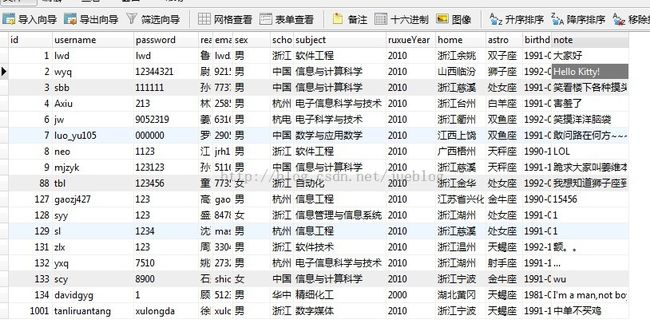
SQL增删改查范例
#增
INSERT INTO t_userr(username,password,sex) values('jj','11','n');
#删
DELETE FROM t_userr WHERE username = 'jj';
#改
UPDATE t_userr SET ruxueYear='2000',note="水电费" WHERE username='jj';
#查
SELECT id,username FROM t_userr WHERE sex='男';
SELECT username FROM t_userr;
SELECT realName FROM t_userr WHERE sex='男' AND school='中国计量';
SELECT * FROM t_userr;#全部信息
SELECT * FROM t_userr WHERE sex='女';
附录:SQL 基本语法
1、说明:创建数据库
CREATE DATABASE database-name
CREATE DATABASE database-name
2、说明:删除数据库
drop database dbname
3、说明:备份sql server
--- 创建 备份数据的 device
USE master
EXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1.dat'
--- 开始 备份
BACKUP DATABASE pubs TO testBack
4、说明:创建新表
create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..)
根据已有的表创建新表:
A:create table tab_new like tab_old (使用旧表创建新表)
B:create table tab_new as select col1,col2… from tab_old definition only
5、说明:删除新表
drop table tabname
6、说明:增加一个列
Alter table tabname add column col type
注:列增加后将不能删除。DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。
7、说明:添加主键: Alter table tabname add primary key(col)
说明:删除主键: Alter table tabname drop primary key(col)
8、说明:创建索引:create [unique] index idxname on tabname(col….)
删除索引:drop index idxname
注:索引是不可更改的,想更改必须删除重新建。
9、说明:创建视图:create view viewname as select statement
删除视图:drop view viewname
10、说明:几个简单的基本的sql语句
选择:select * from table1 where 范围
插入:insert into table1(field1,field2) values(value1,value2)
删除:delete from table1 where 范围
更新:update table1 set field1=value1 where 范围
查找:select * from table1 where field1 like ’%value1%’ ---like的语法很精妙,查资料!
排序:select * from table1 order by field1,field2 [desc]
总数:select count as totalcount from table1
求和:select sum(field1) as sumvalue from table1
平均:select avg(field1) as avgvalue from table1
最大:select max(field1) as maxvalue from table1
最小:select min(field1) as minvalue from table1
11、说明:几个高级查询运算词
A: UNION 运算符
UNION 运算符通过组合其他两个结果表(例如 TABLE1 和 TABLE2)并消去表中任何重复行而派生出一个结果表。当 ALL 随 UNION 一起使用时(即 UNION ALL),不消除重复行。两种情况下,派生表的每一行不是来自 TABLE1 就是来自 TABLE2。
B: EXCEPT 运算符
EXCEPT 运算符通过包括所有在 TABLE1 中但不在 TABLE2 中的行并消除所有重复行而派生出一个结果表。当 ALL 随 EXCEPT 一起使用时 (EXCEPT ALL),不消除重复行。
C: INTERSECT 运算符
INTERSECT 运算符通过只包括 TABLE1 和 TABLE2 中都有的行并消除所有重复行而派生出一个结果表。当 ALL 随 INTERSECT 一起使用时 (INTERSECT ALL),不消除重复行。
注:使用运算词的几个查询结果行必须是一致的。
12、说明:使用外连接
A、left (outer) join:
左外连接(左连接):结果集几包括连接表的匹配行,也包括左连接表的所有行。
SQL: select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUT JOIN b ON a.a = b.c
B:right (outer) join:
右外连接(右连接):结果集既包括连接表的匹配连接行,也包括右连接表的所有行。
C:full/cross (outer) join:
全外连接:不仅包括符号连接表的匹配行,还包括两个连接表中的所有记录。
12、分组:Group by:
一张表,一旦分组 完成后,查询后只能得到组相关的信息。
组相关的信息:(统计信息) count,sum,max,min,avg 分组的标准)
在SQLServer中分组时:不能以text,ntext,image类型的字段作为分组依据
在selecte统计函数中的字段,不能和普通的字段放在一起;
13、对数据库进行操作:
分离数据库: sp_detach_db; 附加数据库:sp_attach_db 后接表明,附加需要完整的路径名
14.如何修改数据库的名称:
sp_renamedb 'old_name', 'new_name'
drop database dbname
3、说明:备份sql server
--- 创建 备份数据的 device
USE master
EXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1.dat'
--- 开始 备份
BACKUP DATABASE pubs TO testBack
4、说明:创建新表
create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..)
根据已有的表创建新表:
A:create table tab_new like tab_old (使用旧表创建新表)
B:create table tab_new as select col1,col2… from tab_old definition only
5、说明:删除新表
drop table tabname
6、说明:增加一个列
Alter table tabname add column col type
注:列增加后将不能删除。DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。
7、说明:添加主键: Alter table tabname add primary key(col)
说明:删除主键: Alter table tabname drop primary key(col)
8、说明:创建索引:create [unique] index idxname on tabname(col….)
删除索引:drop index idxname
注:索引是不可更改的,想更改必须删除重新建。
9、说明:创建视图:create view viewname as select statement
删除视图:drop view viewname
10、说明:几个简单的基本的sql语句
选择:select * from table1 where 范围
插入:insert into table1(field1,field2) values(value1,value2)
删除:delete from table1 where 范围
更新:update table1 set field1=value1 where 范围
查找:select * from table1 where field1 like ’%value1%’ ---like的语法很精妙,查资料!
排序:select * from table1 order by field1,field2 [desc]
总数:select count as totalcount from table1
求和:select sum(field1) as sumvalue from table1
平均:select avg(field1) as avgvalue from table1
最大:select max(field1) as maxvalue from table1
最小:select min(field1) as minvalue from table1
11、说明:几个高级查询运算词
A: UNION 运算符
UNION 运算符通过组合其他两个结果表(例如 TABLE1 和 TABLE2)并消去表中任何重复行而派生出一个结果表。当 ALL 随 UNION 一起使用时(即 UNION ALL),不消除重复行。两种情况下,派生表的每一行不是来自 TABLE1 就是来自 TABLE2。
B: EXCEPT 运算符
EXCEPT 运算符通过包括所有在 TABLE1 中但不在 TABLE2 中的行并消除所有重复行而派生出一个结果表。当 ALL 随 EXCEPT 一起使用时 (EXCEPT ALL),不消除重复行。
C: INTERSECT 运算符
INTERSECT 运算符通过只包括 TABLE1 和 TABLE2 中都有的行并消除所有重复行而派生出一个结果表。当 ALL 随 INTERSECT 一起使用时 (INTERSECT ALL),不消除重复行。
注:使用运算词的几个查询结果行必须是一致的。
12、说明:使用外连接
A、left (outer) join:
左外连接(左连接):结果集几包括连接表的匹配行,也包括左连接表的所有行。
SQL: select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUT JOIN b ON a.a = b.c
B:right (outer) join:
右外连接(右连接):结果集既包括连接表的匹配连接行,也包括右连接表的所有行。
C:full/cross (outer) join:
全外连接:不仅包括符号连接表的匹配行,还包括两个连接表中的所有记录。
12、分组:Group by:
一张表,一旦分组 完成后,查询后只能得到组相关的信息。
组相关的信息:(统计信息) count,sum,max,min,avg 分组的标准)
在SQLServer中分组时:不能以text,ntext,image类型的字段作为分组依据
在selecte统计函数中的字段,不能和普通的字段放在一起;
13、对数据库进行操作:
分离数据库: sp_detach_db; 附加数据库:sp_attach_db 后接表明,附加需要完整的路径名
14.如何修改数据库的名称:
sp_renamedb 'old_name', 'new_name'