unix环境高级编程 wait和waitpid调用
1.8.1 简介
2002 年 3 月 01 日
本文介绍了Linux下的进程概念,并着重讲解了与Linux进程管理相关的4个重要系统调用getpid,fork,exit和_exit,辅助一些例程说明了它们的特点和使用方法。
关于进程的一些必要知识
先 看一下进程在大学课本里的标准定义:“进程是可并发执行的程序在一个数据集合上的运行过程。”这个定义非常严谨,而且难懂,如果你没有一下子理解这句话, 就不妨看看笔者自己的并不严谨的解释。我们大家都知道,硬盘上的一个可执行文件经常被称作程序,在Linux系统中,当一个程序开始执行后,在开始执行到 执行完毕退出这段时间里,它在内存中的部分就被称作一个进程。
当然,这个解释并不完善,但好处是容易理解,在以下的文章中,我们将会对进程作一些更全面的认识。
|
Linux进程简介
Linux 是一个多任务的操作系统,也就是说,在同一个时间内,可以有多个进程同时执行。如果读者对计算机硬件体系有一定了解的话,会知道我们大家常用的单CPU计 算机实际上在一个时间片断内只能执行一条指令,那么Linux是如何实现多进程同时执行的呢?原来Linux使用了一种称为“进程调度(process scheduling)”的手段,首先,为每个进程指派一定的运行时间,这个时间通常很短,短到以毫秒为单位,然后依照某种规则,从众多进程中挑选一个投 入运行,其他的进程暂时等待,当正在运行的那个进程时间耗尽,或执行完毕退出,或因某种原因暂停,Linux就会重新进行调度,挑选下一个进程投入运行。 因为每个进程占用的时间片都很短,在我们使用者的角度来看,就好像多个进程同时运行一样了。
在Linux中,每个进程在创建 时都会被分配一个数据结构,称为进程控制块(Process Control Block,简称PCB)。PCB中包含了很多重要的信息,供系统调度和进程本身执行使用,其中最重要的莫过于进程ID(process ID)了,进程ID也被称作进程标识符,是一个非负的整数,在Linux操作系统中唯一地标志一个进程,在我们最常使用的I386架构(即PC使用的架 构)上,一个非负的整数的变化范围是0-32767,这也是我们所有可能取到的进程ID。其实从进程ID的名字就可以看出,它就是进程的身份证号码,每个 人的身份证号码都不会相同,每个进程的进程ID也不会相同。
一个或多个进程可以合起来构成一个进程组(process group),一个或多个进程组可以合起来构成一个会话(session)。这样我们就有了对进程进行批量操作的能力,比如通过向某个进程组发送信号来实现向该组中的每个进程发送信号。
最后,让我们通过ps命令亲眼看一看自己的系统中目前有多少进程在运行:
$ps -aux (以下是在我的计算机上的运行结果,你的结果很可能与这不同。) |
以上除标题外,每一行都代表一个进程。在各列中,PID一列代表了各进程的进程ID,COMMAND一列代表了进程的名称或在Shell中调用的命令行,对其他列的具体含义,我就不再作解释,有兴趣的读者可以去参考相关书籍。
|
getpid
在2.4.4版内核中,getpid是第20号系统调用,其在Linux函数库中的原型是:
#include<sys/types.h> /* 提供类型pid_t的定义 */ |
getpid的作用很简单,就是返回当前进程的进程ID,请大家看以下的例子:
/* getpid_test.c */ |
细心的读者可能注意到了,这个程序的定义里并没有包含 头文件sys/types.h,这是因为我们在程序中没有用到pid_t类型,pid_t类型即为进程ID的类型。事实上,在i386架构上(就是我们一 般PC计算机的架构),pid_t类型是和int类型完全兼容的,我们可以用处理整形数的方法去处理pid_t类型的数据,比如,用"%d"把它打印出 来。
编译并运行程序getpid_test.c:
$gcc getpid_test.c -o getpid_test |
再运行一遍:
$./getpid_test |
正如我们所见,尽管是同一个应用程序,每一次运行的时候,所分配的进程标识符都不相同。
|
fork
在2.4.4版内核中,fork是第2号系统调用,其在Linux函数库中的原型是:
#include<sys/types.h> /* 提供类型pid_t的定义 */ |
只看fork的名字,可能难得有几个人可以猜到它是做什么用的。fork系统调用的作用是复制一个进程。当一个进程调用它,完成后就出现两个几乎一模一样的进程,我们也由此得到了一个新进程。据说fork的名字就是来源于这个与叉子的形状颇有几分相似的工作流程。
在 Linux中,创造新进程的方法只有一个,就是我们正在介绍的fork。其他一些库函数,如system(),看起来似乎它们也能创建新的进程,如果能看 一下它们的源码就会明白,它们实际上也在内部调用了fork。包括我们在命令行下运行应用程序,新的进程也是由shell调用fork制造出来的。 fork有一些很有意思的特征,下面就让我们通过一个小程序来对它有更多的了解。
/* fork_test.c */ |
编译并运行:
$gcc fork_test.c -o fork_test |
看这个程序的时候,头脑中必须首先了解一个概念:在语句pid=fork()之前,只有一个进程在执行这段代码,但在这条语句之后,就变成两个进程在执行了,这两个进程的代码部分完全相同,将要执行的下一条语句都是if(pid==0)……。
两 个进程中,原先就存在的那个被称作“父进程”,新出现的那个被称作“子进程”。父子进程的区别除了进程标志符(process ID)不同外,变量pid的值也不相同,pid存放的是fork的返回值。fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三 种不同的返回值:
- 在父进程中,fork返回新创建子进程的进程ID;
- 在子进程中,fork返回0;
- 如果出现错误,fork返回一个负值;
fork出错可能有两种原因:(1)当前的进程数已经达到了系统规定的上限,这时errno的值被设置为EAGAIN。(2)系统内存不足,这时errno的值被设置为ENOMEM。(关于errno的意义,请参考本系列的第一篇文章。)
fork系统调用出错的可能性很小,而且如果出错,一般都为第一种错误。如果出现第二种错误,说明系统已经没有可分配的内存,正处于崩溃的边缘,这种情况对Linux来说是很罕见的。
说 到这里,聪明的读者可能已经完全看懂剩下的代码了,如果pid小于0,说明出现了错误;pid==0,就说明fork返回了0,也就说明当前进程是子进 程,就去执行printf("I am the child!"),否则(else),当前进程就是父进程,执行printf("I am the parent!")。完美主义者会觉得这很冗余,因为两个进程里都各有一条它们永远执行不到的语句。不必过于为此耿耿于怀,毕竟很多年以前,UNIX的鼻 祖们在当时内存小得无法想象的计算机上就是这样写程序的,以我们如今的“海量”内存,完全可以把这几个字节的顾虑抛到九霄云外。
说 到这里,可能有些读者还有疑问:如果fork后子进程和父进程几乎完全一样,而系统中产生新进程唯一的方法就是fork,那岂不是系统中所有的进程都要一 模一样吗?那我们要执行新的应用程序时候怎么办呢?从对Linux系统的经验中,我们知道这种问题并不存在。至于采用了什么方法,我们把这个问题留到后面 具体讨论。
|
exit
在2.4.4版内核中,exit是第1号调用,其在Linux函数库中的原型是:
#include<stdlib.h> |
不像fork那么难理解,从exit的名字就能看出,这个系统调用是用来终止一个进程的。无论在程序中的什么位置,只要执行到exit系统调用,进程就会停止剩下的所有操作,清除包括PCB在内的各种数据结构,并终止本进程的运行。请看下面的程序:
/* exit_test1.c */ |
编译后运行:
$gcc exit_test1.c -o exit_test1 |
我们可以看到,程序并没有打印后面的"never be displayed!/n",因为在此之前,在执行到exit(0)时,进程就已经终止了。
exit 系统调用带有一个整数类型的参数status,我们可以利用这个参数传递进程结束时的状态,比如说,该进程是正常结束的,还是出现某种意外而结束的,一般 来说,0表示没有意外的正常结束;其他的数值表示出现了错误,进程非正常结束。我们在实际编程时,可以用wait系统调用接收子进程的返回值,从而针对不 同的情况进行不同的处理。关于wait的详细情况,我们将在以后的篇幅中进行介绍。
|
exit和_exit
作为系统调用而言,_exit和exit是一对孪生兄弟,它们究竟相似到什么程度,我们可以从Linux的源码中找到答案:
#define __NR__exit __NR_exit /* 摘自文件include/asm-i386/unistd.h第334行 */
“__NR_”是在Linux的源码中为每个系统调用加上的前缀,请注意第一个exit前有2条下划线,第二个exit前只有1条下划线。
这时随便一个懂得C语言并且头脑清醒的人都会说,_exit和exit没有任何区别,但我们还要讲一下这两者之间的区别,这种区别主要体现在它们在函数库中的定义。_exit在Linux函数库中的原型是:
#include<unistd.h> |
和exit比较一下,exit()函数定义在 stdlib.h中,而_exit()定义在unistd.h中,从名字上看,stdlib.h似乎比unistd.h高级一点,那么,它们之间到底有什 么区别呢?让我们先来看流程图,通过下图,我们会对这两个系统调用的执行过程产生一个较为直观的认识。
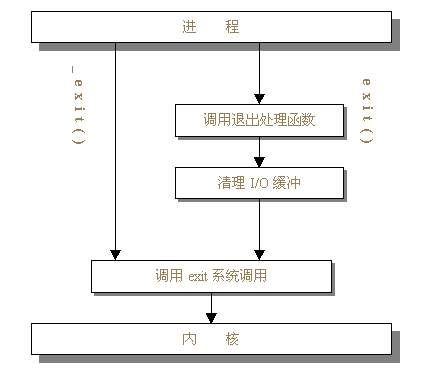
从 图中可以看出,_exit()函数的作用最为简单:直接使进程停止运行,清除其使用的内存空间,并销毁其在内核中的各种数据结构;exit()函数则在这 些基础上作了一些包装,在执行退出之前加了若干道工序,也是因为这个原因,有些人认为exit已经不能算是纯粹的系统调用。
exit()函数与_exit()函数最大的区别就在于exit()函数在调用exit系统调用之前要检查文件的打开情况,把文件缓冲区中的内容写回文件,就是图中的“清理I/O缓冲”一项。
在 Linux的标准函数库中,有一套称作“高级I/O”的函数,我们熟知的printf()、fopen()、fread()、fwrite()都在此列, 它们也被称作“缓冲I/O(buffered I/O)”,其特征是对应每一个打开的文件,在内存中都有一片缓冲区,每次读文件时,会多读出若干条记录,这样下次读文件时就可以直接从内存的缓冲区中读 取,每次写文件的时候,也仅仅是写入内存中的缓冲区,等满足了一定的条件(达到一定数量,或遇到特定字符,如换行符/n和文件结束符EOF),再将缓冲区 中的内容一次性写入文件,这样就大大增加了文件读写的速度,但也为我们编程带来了一点点麻烦。如果有一些数据,我们认为已经写入了文件,实际上因为没有满 足特定的条件,它们还只是保存在缓冲区内,这时我们用_exit()函数直接将进程关闭,缓冲区中的数据就会丢失,反之,如果想保证数据的完整性,就一定 要使用exit()函数。
请看以下例程:
/* exit2.c */ |
编译并运行:
$gcc exit2.c -o exit2 |
编译并运行:
$gcc _exit1.c -o _exit1 |
在Linux中,标准输入和标准输出都是作为文件处理的,虽然是一类特殊的文件,但从程序员的角度来看,它们和硬盘上存储数据的普通文件并没有任何区别。与所有其他文件一样,它们在打开后也有自己的缓冲区。
请读者结合前面的叙述,思考一下为什么这两个程序会得出不同的结果。相信如果您理解了我前面所讲的内容,会很容易的得出结论。
1.7 背景
在 前面的文章中,我们已经了解了父进程和子进程的概念,并已经掌握了系统调用exit的用法,但可能很少有人意识到,在一个进程调用了exit之后,该进程 并非马上就消失掉,而是留下一个称为僵尸进程(Zombie)的数据结构。在Linux进程的5种状态中,僵尸进程是非常特殊的一种,它已经放弃了几乎所 有内存空间,没有任何可执行代码,也不能被调度,仅仅在进程列表中保留一个位置,记载该进程的退出状态等信息供其他进程收集,除此之外,僵尸进程不再占有 任何内存空间。从这点来看,僵尸进程虽然有一个很酷的名字,但它的影响力远远抵不上那些真正的僵尸兄弟,真正的僵尸总能令人感到恐怖,而僵尸进程却除了留 下一些供人凭吊的信息,对系统毫无作用。
也许读者们还对这个新概念比较好奇,那就让我们来看一眼Linux里的僵尸进程究竟长什么样子。
当一个进程已退出,但其父进程还没有调用系统调用wait(稍后介绍)对其进行收集之前的这段时间里,它会一直保持僵尸状态,利用这个特点,我们来写一个简单的小程序:
/* zombie.c */ |
sleep的作用是让进程休眠指定的秒数,在这60秒内,子进程已经退出,而父进程正忙着睡觉,不可能对它进行收集,这样,我们就能保持子进程60秒的僵尸状态。
编译这个程序:
$ cc zombie.c -o zombie |
后台运行程序,以使我们能够执行下一条命令
$ ./zombie & |
列一下系统内的进程
$ ps -ax |
看到中间的"Z"了吗?那就是僵尸进程的标志,它表示1578号进程现在就是一个僵尸进程。
我 们已经学习了系统调用exit,它的作用是使进程退出,但也仅仅限于将一个正常的进程变成一个僵尸进程,并不能将其完全销毁。僵尸进程虽然对其他进程几乎 没有什么影响,不占用CPU时间,消耗的内存也几乎可以忽略不计,但有它在那里呆着,还是让人觉得心里很不舒服。而且Linux系统中进程数目是有限制 的,在一些特殊的情况下,如果存在太多的僵尸进程,也会影响到新进程的产生。那么,我们该如何来消灭这些僵尸进程呢?
先 来了解一下僵尸进程的来由,我们知道,Linux和UNIX总有着剪不断理还乱的亲缘关系,僵尸进程的概念也是从UNIX上继承来的,而UNIX的先驱们 设计这个东西并非是因为闲来无聊想烦烦其他的程序员。僵尸进程中保存着很多对程序员和系统管理员非常重要的信息,首先,这个进程是怎么死亡的?是正常退出 呢,还是出现了错误,还是被其它进程强迫退出的?其次,这个进程占用的总系统CPU时间和总用户CPU时间分别是多少?发生页错误的数目和收到信号的数 目。这些信息都被存储在僵尸进程中,试想如果没有僵尸进程,进程一退出,所有与之相关的信息都立刻归于无形,而此时程序员或系统管理员需要用到,就只好干 瞪眼了。
那么,我们如何收集这些信息,并终结这些僵尸进程呢?就要靠我们下面要讲到的waitpid调用和wait调用。这两者的作用都是收集僵尸进程留下的信息,同时使这个进程彻底消失。下面就对这两个调用分别作详细介绍。
wait的函数原型是:
#include <sys/types.h> /* 提供类型pid_t的定义 */ |
进程一旦调用了wait,就立即阻塞自己,由wait自动分析是否当前进程的某个子进程已经退出,如果让它找到了这样一个已经变成僵尸的子进 程,wait就会收集这个子进程的信息,并把它彻底销毁后返回;如果没有找到这样一个子进程,wait就会一直阻塞在这里,直到有一个出现为止。
参数status用来保存被收集进程退出时的一些状态,它是一个指向int类型的指针。但如果我们对这个子进程是如何死掉的毫不在意,只想把这个僵尸进程消灭掉,(事实上绝大多数情况下,我们都会这样想),我们就可以设定这个参数为NULL,就象下面这样:
pid = wait(NULL); |
如果成功,wait会返回被收集的子进程的进程ID,如果调用进程没有子进程,调用就会失败,此时wait返回-1,同时errno被置为ECHILD。
1.8.2 实战
下面就让我们用一个例子来实战应用一下wait调用,程序中用到了系统调用fork,如果你对此不大熟悉或已经忘记了,请参考上一篇文章《进程管理相关的系统调用(一)》。
/* wait1.c */ |
编译并运行:
$ cc wait1.c -o wait1 |
可以明显注意到,在第2行结果打印出来前有10秒钟的等待时间,这就是我们设定的让子进程睡眠的时间,只有子进程从睡眠中苏醒过来,它才能正常退 出,也就才能被父进程捕捉到。其实这里我们不管设定子进程睡眠的时间有多长,父进程都会一直等待下去,读者如果有兴趣的话,可以试着自己修改一下这个数 值,看看会出现怎样的结果。
1.8.3 参数status
如果参数status的值不是NULL,wait就会把子进程退出时的状态取出并存入其中,这是一个整数值(int),指出了子进程是正常退出还是 被非正常结束的(一个进程也可以被其他进程用信号结束,我们将在以后的文章中介绍),以及正常结束时的返回值,或被哪一个信号结束的等信息。由于这些信息 被存放在一个整数的不同二进制位中,所以用常规的方法读取会非常麻烦,人们就设计了一套专门的宏(macro)来完成这项工作,下面我们来学习一下其中最 常用的两个:
1,WIFEXITED(status) 这个宏用来指出子进程是否为正常退出的,如果是,它会返回一个非零值。
(请注意,虽然名字一样,这里的参数status并不同于wait唯一的参数--指向整数的指针status,而是那个指针所指向的整数,切记不要搞混了。)
2,WEXITSTATUS(status) 当WIFEXITED返回非零值时,我们可以用这个宏来提取子进程的返回值,如果子进程调用exit(5)退出,WEXITSTATUS(status) 就会返回5;如果子进程调用exit(7),WEXITSTATUS(status)就会返回7。请注意,如果进程不是正常退出的,也就是 说,WIFEXITED返回0,这个值就毫无意义。
下面通过例子来实战一下我们刚刚学到的内容:
/* wait2.c */ |
编译并运行:
$ cc wait2.c -o wait2 |
父进程准确捕捉到了子进程的返回值3,并把它打印了出来。
当然,处理进程退出状态的宏并不止这两个,但它们当中的绝大部分在平时的编程中很少用到,就也不在这里浪费篇幅介绍了,有兴趣的读者可以自己参阅Linux man pages去了解它们的用法。
1.9 waitpid
1.9.1 简介
waitpid系统调用在Linux函数库中的原型是:
#include <sys/types.h> /* 提供类型pid_t的定义 */ |
从本质上讲,系统调用waitpid和wait的作用是完全相同的,但waitpid多出了两个可由用户控制的参数pid和options,从而为我们编程提供了另一种更灵活的方式。下面我们就来详细介绍一下这两个参数:
pid
从参数的名字pid和类型pid_t中就可以看出,这里需要的是一个进程ID。但当pid取不同的值时,在这里有不同的意义。
- pid>0时,只等待进程ID等于pid的子进程,不管其它已经有多少子进程运行结束退出了,只要指定的子进程还没有结束,waitpid就会一直等下去。
- pid=-1时,等待任何一个子进程退出,没有任何限制,此时waitpid和wait的作用一模一样。
- pid=0时,等待同一个进程组中的任何子进程,如果子进程已经加入了别的进程组,waitpid不会对它做任何理睬。
- pid<-1时,等待一个指定进程组中的任何子进程,这个进程组的ID等于pid的绝对值。
options
options提供了一些额外的选项来控制waitpid,目前在Linux中只支持WNOHANG和WUNTRACED两个选项,这是两个常数,可以用"|"运算符把它们连接起来使用,比如:
ret=waitpid(-1,NULL,WNOHANG | WUNTRACED); |
如果我们不想使用它们,也可以把options设为0,如:
ret=waitpid(-1,NULL,0); |
如果使用了WNOHANG参数调用waitpid,即使没有子进程退出,它也会立即返回,不会像wait那样永远等下去。
而WUNTRACED参数,由于涉及到一些跟踪调试方面的知识,加之极少用到,这里就不多费笔墨了,有兴趣的读者可以自行查阅相关材料。
看到这里,聪明的读者可能已经看出端倪了--wait不就是经过包装的waitpid吗?没错,察看<内核源码目录>/include/unistd.h文件349-352行就会发现以下程序段:
static inline pid_t wait(int * wait_stat) |
1.9.2 返回值和错误
waitpid的返回值比wait稍微复杂一些,一共有3种情况:
- 当正常返回的时候,waitpid返回收集到的子进程的进程ID;
- 如果设置了选项WNOHANG,而调用中waitpid发现没有已退出的子进程可收集,则返回0;
- 如果调用中出错,则返回-1,这时errno会被设置成相应的值以指示错误所在;
当pid所指示的子进程不存在,或此进程存在,但不是调用进程的子进程,waitpid就会出错返回,这时errno被设置为ECHILD;
/* waitpid.c */ |
编译并运行:
$ cc waitpid.c -o waitpid |
父进程经过10次失败的尝试之后,终于收集到了退出的子进程。
因为这只是一个例子程序,不便写得太复杂,所以我们就让父进程和子进程分别睡眠了10秒钟和1秒钟,代表它们分别作了10秒钟和1秒钟的工作。父子进程都有工作要做,父进程利用工作的简短间歇察看子进程的是否退出,如退出就收集它。
原文地址 http://www.ibm.com/developerworks/cn/linux/kernel/syscall/part3/index.html