Ng机器学习系列补充:7、神经网络反向传播BP算法(Back Propagation)
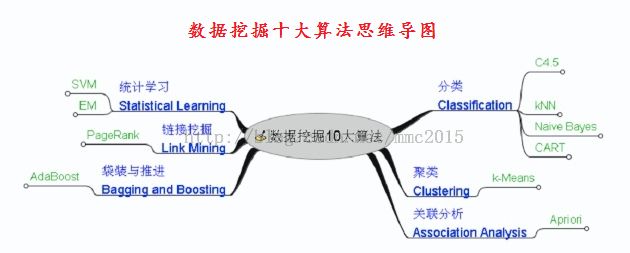
机器学习补充系列国际权威的学术组织the IEEE International Conference on Data Mining (ICDM,国际数据哇局会议) 2006年12月评选出了数据挖掘领域的十大经典算法:C4.5, k-Means, SVM, Apriori, EM, PageRank, AdaBoost, kNN, Naive Bayes, and CART,它们在数据挖掘领域都产生了极为深远的影响,这里对他们做一个简单介绍,仅作为对Ng机器学习教程的补充。
由于k-Means、SVM、EM、kNN、Naive Bayes在Ng的系列教程中都有涉及,所以此系列教程只涉及决策树算法C4.5、关联规则算法Apriori、网页排名算法PageRank、集成学习算法AdaBoost(Adaptive Boosting,自适应推进)、分类与回归树算法CART(Classification and Regression Trees);另外会加上对神经网络的BP算法介绍,后续也会考虑介绍遗传算法等内容。
1)BP算法简介
2)BP算法反向传播实例
1)BP算法简介
BP神经网络模型拓扑结构包括输入层(input)、隐含层(hide layer)和输出层(output layer)。
BP的思想可以总结为:利用输出后的误差来估计输出层的直接前导层的误差,再用这个误差估计更前一层的误差,如此一层一层的反传下去,就获得了所有其他各层的误差估计。
BP利用“激活函数”来描述各层输入和输出之间的关系,激活函数必须满足处处可导的条件,常用的是S型函数:y = f(x) = 1 / ( 1 + e-x),且S函数导函数为y ' = y*(1-y)。
下面举个例子,只介绍如何反向传播误差,至于隐含层选几个神经元、计算量非常大等内容不在本文讨论范围之内。
2)BP算法反向传播实例
BP网络如下:

假设对应输入X={x1=0.35, x2=0.9}的预期输出是Y=0.5;假设P、Q、O三个神经元的激活函数都是S型函数,但为了区分,分别记为P(x)、Q(x)、O(x);下面介绍如何E-BP。
a)输入正向传播:
P(x) = 1 / ( 1 + e-x) = 1 / ( 1 + e-(x1*AP+x2*BP) ) = 1 / ( 1 + e-(0.35*0.1+0.9*0.8) ) = 0.68;
Q(x) = 1 / ( 1 + e-x) = 1 / ( 1 + e-(x1*AQ+x2*BQ) ) = 1 / ( 1 + e-(0.35*0.4+0.9*0.6) ) = 0.6637;
O(x) = 1 / ( 1 + e-x) = 1 / ( 1 + e-(P(x)*PO+Q(x)*QO) ) = 1 / ( 1 + e-(0.68*0.3+0.6637*0.9) ) = 0.69;
b)计算最终均方误差:
ε = 1/2 * E2 = 1/2 * (O(x) - 0.5)2 = 1/2 * (0.69 - 0.5)2 =0.01805,我们希望他越小越好!
调整原则:for each training example d every weight wji is updated by adding to it Δwji, where Δwji = - & * wji\ε'。(&为速率,wji\ε' 表示ε对wji求偏导数)
c)误差反向传播更新权值:
还是用最典型的办法,求梯度(不考虑常数&)。
PO\ε' = 1/2*2*E*E' = E*(O(X)') = E * ( O(X) * ( 1 - O(X) ) * ( PO\ (P(x)*PO+Q(x)*QO)' ) ) = E * O(X) * ( 1 - O(X) ) * P(x) = (0.69 - 0.5) * 0.69 * ( 1 - 0.69 ) * 0.68 = 0.02763,注意这里的PO不再是固定的0.3,而是看作变量。
同理,QO\ε' = E * O(X) * ( 1 - O(X) ) * Q(x) = (0.69 - 0.5) * 0.69 * ( 1 - 0.69 ) * 0.6637 = 0.02711。
所以,PO^ = PO - PO\ε' = 0.3 - 0.02763 = 0.2723;QO^ = QO - QO\ε' = 0.9 - 0.02711 = 0.8730。(PO^表示更新后的PO)
AP\ε' = 1/2*2*E*E' = E*(O(X)') = E * ( O(X) * ( 1 - O(X) ) * ( AP \ (P(x)*PO+Q(x)*QO)' ) ) = E * O(X) * ( 1 - O(X) ) * PO^ * AP\P(x)'
= E * O(X) * ( 1 - O(X) ) * PO^ * ( P(x) * (1 - P(x)) * ( AP\(x1*AP+x2*BP)' ) ) = E * O(X) * ( 1 - O(X) ) * PO^ * P(x) * (1 - P(x)) * x1 = (0.69-0.5) * 0.69 * (1-0.69) * 0.8730 * 0.68 * (1-0.68) * 0.35 = …,注意这里使用更新后的PO^,同上面,AP不再是固定的0.1,而是看作变量。
同理,BP\ε' = E * O(X) * ( 1 - O(X) ) * PO^ * P(x) * (1 - P(x)) * x2
AQ\ε' = E * O(X) * ( 1 - O(X) ) * QO^ * Q(x) * (1 - Q(x)) * x1
BQ\ε' = E * O(X) * ( 1 - O(X) ) * QO^ * Q(x) * (1 - Q(x)) * x2
所以,AP^ = AP - AP\ε';AQ^ = AQ - AQ\ε';BP^ = BP - BP\ε';BQ^ = BQ - BQ\ε'。
上面过程持续迭代,直到神经元的计算结果逼近目标值0.5。
参考:
http://blog.csdn.net/pennyliang/article/details/6695355
http://www.cnblogs.com/wentingtu/archive/2012/06/05/2536425.html