BoW图像检索Python实战
下文来自我的博客:BoW图像检索Python实战
前几天把HABI哈希图像检索工具包更新到V2.0版本后,小白菜又重新回头来用Python搞BoW词袋模型,一方面主要是练练Python,另一方面也是为了CBIR群开讲的关于图像检索群活动第二期而准备的一些素材。关于BoW,网上堆资料讲得挺好挺全的了,小白菜自己在曾留下过一篇讲解BoW词袋构建过程的博文Bag of Words模型,所以这里主要讲讲BoW的实战。不过在实战前,小白菜还想在结合自己这两年多BoW的思考和沉淀重新以更直白的方式对BoW做一下总结。
举两个例子来说明BoW词袋模型。第一个例子在介绍BoW词袋模型时一般资料里会经常使用到,就是将图像类比成文档,即一幅图像类比成一个文档,将图像中提取的诸如SIFT特征点类比成文档中的单词,然后把从图像库中所有提取的所有SIFT特征点弄在一块进行聚类,从中得到具有代表性的聚类中心(单词),再对每一幅图像中的SIFT特征点找距离它最近的聚类中心(单词),做词频(TF)统计,图解如下: 做完词频(TF)统计后,为了降低停用词带来的干扰,可以再算个逆文档词频(IDF),也就是给TF乘上个权重,该过程可以图解如下: 上面单词权重即逆文档词频(IDF),那时通过统计每个单词包含了多少个文档然后按设定的一个对数权重公式计算得来的,具体如下: 对于上传上来的查询图像,提取SIFT然后统计tf后乘上上面的idf便可得到id-idf向量,然后进行L2归一化,用内积做相似性度量。
在做TF统计的时候,我们知道一般为了取得更好的效果,通常单词数目会做得比较大,动则上万或几十万,所以在做聚类的时候,可以对这些类中心做一个K-D树,这样在做TF词频统计的时候便可以加快单词直方图计算的速度。
上面举的例子对于初次接触BoW的人来说可能讲得不是那么的直观,小白菜可以举一个更直观的例子(虽然有些地方可能会不怎么贴切,但还是触及BoW的本质),比如美国总统全国大选,假设有10000个比较有影响力的人参加总统竞选,这10000个人表示的就是聚类中心,他们最具有代表性(K-means做的就是得到那些设定数目的最具有代表性的特征点),每个州类比成一幅图像,州里的人手里持的票就好比是SIFT特征点,这样的话,我们就可以对每个州做一个10000维的票数统计结果,这个统计出来的就是上面第一个例子里所说的词频向量。另外,我们还可以统计每个竞选人有多少个州投了他的票,那么就可以得到一个10000维长的对州的统计结果,这个结果再稍微和对数做下处理,便得到了所谓的逆文档词频。
上面的两个例子应该讲清楚了BoW词袋模型吧,下面就来看看BoW词袋模型用Python是怎么实现的。
#!/usr/local/bin/python2.7
#python findFeatures.py -t dataset/train/
import argparse as ap
import cv2
import imutils
import numpy as np
import os
from sklearn.externals import joblib
from scipy.cluster.vq import *
from sklearn import preprocessing
from rootsift import RootSIFT
import math
# Get the path of the training set
parser = ap.ArgumentParser()
parser.add_argument("-t", "--trainingSet", help="Path to Training Set", required="True")
args = vars(parser.parse_args())
# Get the training classes names and store them in a list
train_path = args["trainingSet"]
#train_path = "dataset/train/"
training_names = os.listdir(train_path)
numWords = 1000
# Get all the path to the images and save them in a list
# image_paths and the corresponding label in image_paths
image_paths = []
for training_name in training_names:
image_path = os.path.join(train_path, training_name)
image_paths += [image_path]
# Create feature extraction and keypoint detector objects
fea_det = cv2.FeatureDetector_create("SIFT")
des_ext = cv2.DescriptorExtractor_create("SIFT")
# List where all the descriptors are stored
des_list = []
for i, image_path in enumerate(image_paths):
im = cv2.imread(image_path)
print "Extract SIFT of %s image, %d of %d images" %(training_names[i], i, len(image_paths))
kpts = fea_det.detect(im)
kpts, des = des_ext.compute(im, kpts)
# rootsift
#rs = RootSIFT()
#des = rs.compute(kpts, des)
des_list.append((image_path, des))
# Stack all the descriptors vertically in a numpy array
#downsampling = 1
#descriptors = des_list[0][1][::downsampling,:]
#for image_path, descriptor in des_list[1:]:
# descriptors = np.vstack((descriptors, descriptor[::downsampling,:]))
# Stack all the descriptors vertically in a numpy array
descriptors = des_list[0][1]
for image_path, descriptor in des_list[1:]:
descriptors = np.vstack((descriptors, descriptor))
# Perform k-means clustering
print "Start k-means: %d words, %d key points" %(numWords, descriptors.shape[0])
voc, variance = kmeans(descriptors, numWords, 1)
# Calculate the histogram of features
im_features = np.zeros((len(image_paths), numWords), "float32")
for i in xrange(len(image_paths)):
words, distance = vq(des_list[i][1],voc)
for w in words:
im_features[i][w] += 1
# Perform Tf-Idf vectorization
nbr_occurences = np.sum( (im_features > 0) * 1, axis = 0)
idf = np.array(np.log((1.0*len(image_paths)+1) / (1.0*nbr_occurences + 1)), 'float32')
# Perform L2 normalization
im_features = im_features*idf
im_features = preprocessing.normalize(im_features, norm='l2')
joblib.dump((im_features, image_paths, idf, numWords, voc), "bof.pkl", compress=3)
将上面的文件保存为findFeatures.py,前面主要是一些通过parse使得可以在敲命令行的时候可以向里面传递参数,后面就是提取SIFT特征,然后聚类,计算TF和IDF,得到单词直方图后再做一下L2归一化。一般在一幅图像中提取的到SIFT特征点是非常多的,而如果图像库很大的话,SIFT特征点会非常非常的多,直接聚类是非常困难的(内存不够,计算速度非常慢),所以,为了解决这个问题,可以以牺牲检索精度为代价,在聚类的时候先对SIFT做降采样处理。最后对一些在在线查询时会用到的变量保存下来。对于某个图像库,可以在命令行里通过下面命令生成BoF: sh python findFeatures.py -t dataset/train/
在线查询阶段相比于上面简单了些,没有了聚类过程,具体代码如下:
#!/usr/local/bin/python2.7
#python search.py -i dataset/train/ukbench00000.jpg
import argparse as ap
import cv2
import imutils
import numpy as np
import os
from sklearn.externals import joblib
from scipy.cluster.vq import *
from sklearn import preprocessing
import numpy as np
from pylab import *
from PIL import Image
from rootsift import RootSIFT
# Get the path of the training set
parser = ap.ArgumentParser()
parser.add_argument("-i", "--image", help="Path to query image", required="True")
args = vars(parser.parse_args())
# Get query image path
image_path = args["image"]
# Load the classifier, class names, scaler, number of clusters and vocabulary
im_features, image_paths, idf, numWords, voc = joblib.load("bof.pkl")
# Create feature extraction and keypoint detector objects
fea_det = cv2.FeatureDetector_create("SIFT")
des_ext = cv2.DescriptorExtractor_create("SIFT")
# List where all the descriptors are stored
des_list = []
im = cv2.imread(image_path)
kpts = fea_det.detect(im)
kpts, des = des_ext.compute(im, kpts)
# rootsift
#rs = RootSIFT()
#des = rs.compute(kpts, des)
des_list.append((image_path, des))
# Stack all the descriptors vertically in a numpy array
descriptors = des_list[0][1]
#
test_features = np.zeros((1, numWords), "float32")
words, distance = vq(descriptors,voc)
for w in words:
test_features[0][w] += 1
# Perform Tf-Idf vectorization and L2 normalization
test_features = test_features*idf
test_features = preprocessing.normalize(test_features, norm='l2')
score = np.dot(test_features, im_features.T)
rank_ID = np.argsort(-score)
# Visualize the results
figure()
gray()
subplot(5,4,1)
imshow(im[:,:,::-1])
axis('off')
for i, ID in enumerate(rank_ID[0][0:16]):
img = Image.open(image_paths[ID])
gray()
subplot(5,4,i+5)
imshow(img)
axis('off')
show()
将上面的代码保存为search.py,对某幅图像进行查询时,只需在命令行里输入:
#python search.py -i dataset/train/ukbench00000.jpg(查询图像的路径)
上面的代码中,你可以看到rootSIFT注释掉了,你也可以去掉注释,采用rootSIFT,但这里实验中我发觉rootSIFT并没有SIFT的效果好。最后看看检索的效果,最上面一张是查询图像,后面的是搜索到的图像:
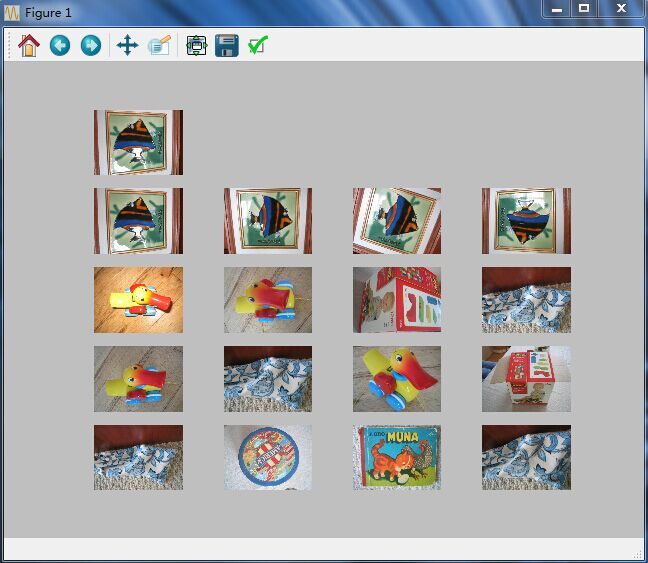
整个实战的代码可以在这里下载:下载地址。