【摘要】图像文本检测提取算法

Scene Text Recognition with Bilateral Regression
Jacqueline Feild and Erik Learned-Miller
Technical Report UM-CS-2012-021
University of Massachusetts Amherst
Abstract
This paper focuses on improving the recognition of text in images of natural scenes,
such as storefront signs or street signs. This is a difficult problem due to lighting con-
ditions, variation in font shape and color, and complex backgrounds. We present a
word recognition system that addresses these difficulties using an innovative technique
to extract and recognize foreground text in an image. First, we develop a new method,
called bilateral regression, for extracting and modeling one coherent (although not nec-
essarily contiguous) region from an image. The method models smooth color changes
across an image region without being corrupted by neighboring image regions. Second,
rather than making a hard decision early in the pipeline about which region is fore-
ground, we generate a set of possible foreground hypotheses, and choose among these
using feedback from a recognition system. We show increased recognition performance
using our segmentation method compared to the current state of the art. Overall, using
our system we also show a substantial increase in word accuracy on the word spotting
task over the current state of the art on the ICDAR 2003 word recognition data set.
Scene text detection using graph model built upon maximally stable extremal regions
Pattern Recognition Letters 34 (2013)
Abstract
Scene text detection could be formulated as a bi-label (text and non-text regions) segmentation problem.
However, due to the high degree of intraclass variation of scene characters as well as the limited number
of training samples, single information source or classifier is not enough to segment text from non-text
background. Thus, in this paper, we propose a novel scene text detection approach using graph model
built upon Maximally Stable Extremal Regions (MSERs) to incorporate various information sources into
one framework. Concretely, after detecting MSERs in the original image, an irregular graph whose nodes
are MSERs, is constructed to label MSERs as text regions or non-text ones. Carefully designed features
contribute to the unary potential to assess the individual penalties for labeling a MSER node as text or
non-text, and color and geometric features are used to define the pairwise potential to punish the likely
discontinuities. By minimizing the cost function via graph cut algorithm, different information carried by
the cost function could be optimally balanced to get the final MSERs labeling result. The proposed method
is naturally context-relevant and scale-insensitive. Experimental results on the ICDAR 2011 competition
dataset show that the proposed approach outperforms state-of-the-art methods both in recall and
precision.
Text extraction from scene images by character appearance and structure modeling
Computer Vision and Image Understanding 117 (2013)
Abstract
In this paper, we propose a novel algorithm to detect text information from natural scene images. Scene
text classification and detection are still open research topics. Our proposed algorithm is able to model
both character appearance and structure to generate representative and discriminative text descriptors.
The contributions of this paper include three aspects: (1) a new character appearance model by a struc-
ture correlation algorithm which extracts discriminative appearance features from detected interest
points of character samples; (2) a new text descriptor based on structons and correlatons, which model
character structure by structure differences among character samples and structure component co-occur-
rence; and (3) a new text region localization method by combining color decomposition, character con-
tour refinement, and string line alignment to localize character candidates and refine detected text
regions. We perform three groups of experiments to evaluate the effectiveness of our proposed algorithm,
including text classification, text detection, and character identification. The evaluation results on bench-
mark datasets demonstrate that our algorithm achieves the state-of-the-art performance on scene text
classification and detection, and significantly outperforms the existing algorithms for character
identification.
Text detection in images using sparse representation with discriminative dictionaries
Image and Vision Computing 28 (2010)
Text detection is important in the retrieval of texts from digital pictures, video databases and webpages.
However, it can be very challenging since the text is often embedded in a complex background. In this paper,
we propose a classification-based algorithm for text detection using a sparse representation with
discriminative dictionaries. First, the edges are detected by the wavelet transform and scanned into patches
by a sliding window. Then, candidate text areas are obtained by applying a simple classification procedure
using two learned discriminative dictionaries. Finally, the adaptive run-length smoothing algorithm and
projection profile analysis are used to further refine the candidate text areas. The proposed method is
evaluated on the Microsoft common test set, the ICDAR 2003 text locating set, and an image set collected
from the web. Extensive experiments show that the proposed method can effectively detect texts of various
sizes, fonts and colors from images and videos.
Scene Text Localization Using Gradient Local Correlation
2013 12th International Conference on Document Analysis and Recognition
In this paper, we propose an efficient scene text
localization method using gradient local correlation, which can
characterize the density of pairwise edges and stroke width
consistency to get a text confidence map. Gradient local
correlation is insensitive to the gradient direction and robust to
noise, small character size and shadow. Based on the text
confidence map, the regions with high confidence are segmented
into connected components (CCs), which are classified to text
CCs and non-text CCs using an SVM classifier. Then, the text
CCs with similar color and stroke width are grouped into text
lines, which are in turn partitioned into words. Experimental
results on the ICDAR 2003 text locating competition dataset
demonstrate the effectiveness of our method.
Scene Text Detection using Sparse Stroke Information and MLP
Pattern Recognition (ICPR 2012)
In this article, we present a novel set of features for
detection of text in images of natural scenes using a
multi-layer perceptron (MLP) classifier. An estimate of
the uniformity in stroke thickness is one of our features
and we obtain the same using only a subset of the
distance transform values of the concerned region.
Estimation of the uniformity in stroke thickness on the
basis of sparse sampling of the distance transform
values is a novel approach. Another feature is the
distance between the foreground and background
colors computed in a perceptually uniform and
illumination-invariant color space. Remaining features
include two ratios of anti-parallel edge gradient
orientations, a regularity measure between the skeletal
representation and Canny edgemap of the object,
average edge gradient magnitude, variation in the
foreground gray levels and five others. Here, we
present the results of the proposed approach on the
ICDAR 2003 database and another database of scene
images consisting of text of Indian scripts.
Bayesian Network Scores Based Text Localization in Scene
2014 International Joint Conference on Neural Networks (IJCNN)
July 6-11, 2014, Beijing, China
Text localization in scene images is an essential and
interesting task to analyze the image contents. In this work, a
Bayesian network scores using K2 algorithm in conjunction
with the geometric features based effective text localization
method with the help of maximally stable extremal regions
(MSERs). First, all MSER-based extracted candidate characters
are directly compared with an existing text localization method
to find text regions. Second, adjacent extracted MSER-based
candidate characters are not encompassed into text regions
due to strict edges constraint. Therefore, extracted candidate
character regions are incorporated into text regions using
selection rules. Third, K2 algorithm-based Bayesian networks
scores are learned for the complimentary candidate character
regions. Bayesian logistic regression classifier is built on the
Bayesian network scores by computing the posterior probability
of complimentary candidate character region corresponding
to non-character candidates. The higher posterior probability
of complimentary Candidate character regions are further
grouped into words or sentences. Bayesian networks scores
based text localization system, na
ICDAR 2013 Robust Reading Competition (Challenge
2 Task 2.1: Text Localization) database. Experimental results
have established significant competitive performance with the
state-of-the-art text detection systems.
K2 Algorithm-based Text Detection with An Adaptive Classifier Threshold
International Journal of Image Processing (IJIP), Volume (8) : Issue (3) : 2014
In natural scene images, text detection is a challenging study area for dissimilar content-based
image analysis tasks. In this paper, a Bayesian network scores are used to classify candidate
character regions by computing posterior probabilities. The posterior probabilities are used to
define an adaptive threshold to detect text in scene images with accuracy. Therefore, candidate
character regions are extracted through maximally stable extremal region. K2 algorithm-based
Bayesian network scores are learned by evaluating dependencies amongst features of a given
candidate character region. Bayesian logistic regression classifier is trained to compute posterior
probabilities to define an adaptive classifier threshold. The candidate character regions below
from adaptive classifier threshold are discarded as non-character regions. Finally, text regions are
detected with the use of effective text localization scheme based on geometric features. The
entire system is evaluated on the ICDAR 2013 competition database. Experimental results
produce competitive performance (precision, recall and harmonic mean) with the recently
published algorithms.
Text localization techniques can be grouped into region-based, connected component (CC)-
based [1] and hybrid methods [2].
Region-based techniques employ a sliding window to look for
image text with the use of machine learning techniques for text identification. Sliding window
based methods tend to be slow due to multi scale processing of images. A new text detection
algorithm extracts six dissimilar classes of text features. Modest AdaBoost classifier is used to
recognize text regions based on text features [3].
CC-based methods group extracted candidate
characters into text regions with similar geometric features. CC-based methods are demanding to
apply additional checks for eliminating false positives. To find CCs, stroke width for every pixel is
computed to group neighboring pixels. These CCs were screened and grouped into text regions
[4].
Pan et al. [2] proposed hybrid method that exploits image regions to detect text candidates
and extracts CCs as candidate characters by local binarization. False positive components are
eliminated efficiently with the use of conditional random field (CRFs) model. Finally, character
components are grouped into lines/words. Recently, Yin et al. [5] extracted maximally stable
extremal regions (MSERs) as letter candidates. Non-letter candidates are eliminated using
geometric information. Candidate text regions are constructed by grouping similar letter
candidates using disjoint set. For each candidate text region, vertical and horizontal variances,
color, geometry and stroke width are extracted to identify text regions using Adaboost classifier.
Besides, MSER based method is the winner of ICDAR 2011 Robust Reading Competition [6] with
promising performance.
Keywords: Bayesian Network, Adaptive Threshold, Bayesian Logistic Regression, Scene Image
. Our text localization method shows a competitive recall 62.37, precision 84.97 and a 71.94
harmonic mean, which is competitive with
the leading methods reported by [10]. However, our text localization method performs better than
the ICDAR 2011 Robust Reading Competition methods reported by [6].
TABLE 1: Performance (%) Comparison of Text Detection Methods on ICDAR 2013 Dataset.
A Skeleton Based Descriptor for Detecting Text in Real Scene Images
关键方法:相似区域作为邻居计算相似距离变成graph,骨架检测子:检验每个区域的骨架skeleton和笔画宽度,使用graph-cut消除错误区域
21st International Conference on Pattern Recognition (ICPR 2012)
November 11-15, 2012. Tsukuba, Japan

Text extraction from natural scene image: A survey

Edges are reliable features for text detection. Usually, an edge detector (e.g., Canny) is used first followed by morphological operations to extract text from background and to eliminate non-text regions. Edge-based methods are usually more efficient and simple in nature scene text extraction. Good performance is often found on scene images exhibiting strong edges. For the same reason, a major problem of edge-based methods lies with the fact that good edge profiles are hard to obtain under the influence of shadow or highlight.....
Scene text detection via stroke width
INTRODUCTION
In recent decades, detecting text in complex nature scenes is a hot topic in computer vision, since text in images provides much semantic information for human to understand the environment. Moreover, text detection is a prerequisite for a couple of purposes, such as content-based image analysis, image retrieval, etc. Unlike overlay text detection in video frames where lots of prior knowledge can be employed, text detection in natural scene images is a difficult problem due to complex background, variations in text's size, font, color, orientation and lighting conditions.
Generally, methods on this topic can be divided into two categories: learning-based methods and connected component (CC)-based methods.
In order to distinguish text regions from non-text ones, learning-based methods use some features to train a classifier (e.g., SVM or AdaBoost). Pan et al. [6] use a polynomial classifier in the verification stage and evaluate five widely used features, including HOG, LBP, DCT, Gabor filter and wavelet, then find the combination of HOG and wavelet showing the best performance. Wang et al. [9] use gray scale contrast feature and edge orientation histogram feature to train a SVM. The main limitations of learning-based methods are high computational complexity and the difficulty to select the best features for scene text detection.

View All | Next
CC-based methods, on the other hand, usually generate separated CCs using some properties, such as edge, stroke width and color. After that, some geometric constraints are designed to remove false positives. Epshtein et al. [1] propose stroke width transform, which converts value of each color pixel into the width of most likely stroke.Zhang and Kasturi [11] use HOG to locate text edges and then Graph Spectrum is utilized to group the characters and remove false positives. The advantage of these methods is that their computational complexity is low. However, the performance of CC-based methods are likely to degrade when dealing with texts in complex background.
In this paper, a novel CC-based text detection algorithm is proposed to overcome the difficulties mentioned above. We make three major contributions compared with other methods available in literature. (1) Though MSER has been exploited in the text detection task, such as [5], most of those approaches use bare MSER algorithm, ignoring the fact that MSER is sensitive to image blur. We overcome this obstacle by incorporating intensity information on the boundary between text and background. (2) Since stroke width is one of the inherent properties of text, which is insensitive to size, font, color, orientation of text, stroke width on the skeleton of CCs is extracted to distinguish between text and non-text regions. (3) We only detect text on one scale, this is more efficient than the work [6] which requires image pyramid in order to detect text with different sizes.
TEXT DETECTION ALGORITHM
An overview of our algorithm is depicted in Figure 1. On every input color image, we first resize it into resolution, then MSER-s are detected and considered as text region candidates (Section 2.1). As a next step, we design some simple heuristic rules to remove MSERs which are not text regions (Section 2.2).Different from stroke width transform in the work [1], we propose stroke width generated by distance transform on the skeleton of each CC to eliminate non-text areas (Section 2.3). In the final step, we group characters into words based on Euclidean distance, orientation and similarities between characters (Section 2.4).
2.1. Contrast-enhanced MSER Detection
The concept of MSER is introduced by Matas et al. [4]. Since a single letter usually shares similar color and its intensity is often quite different from back-ground, MSER can locate these text regions efficiently. MSER has many good properties, such as invariance to affine transformation of image intensities, stability [4] etc., however, it is sensitive to image blur. An example demonstrating this is shown in Figure 3 (b). It is obvious that most of characters are blurred and connected, so it is really difficult for us to get true stroke width of every character in Section 2.3. In order to overcome this problem, we propose a novel contranst-enhanced MSER algorithm as follows.
For an input image I, based on the observation that there are large changes in intensity at the boundary between text pixels and background, an intensity image In is obtained as ![]() in HSI color space. After that, we check intensity gradient using In , where
in HSI color space. After that, we check intensity gradient using In , where ![]() is a threshold, if this condition is met, then update:TeX Sourcewhere
is a threshold, if this condition is met, then update:TeX Sourcewhere ![]() , parameter is a predefined threshold. The aim of this procedure is to enhance the contrast between characters and background (Figure 2). Finally, we conduct MSER detection on this contrast-enhanced image. Figure 3 (c)illustrates the result of our contrast-enhanced MSER detection where all letters in the same word are separated.
, parameter is a predefined threshold. The aim of this procedure is to enhance the contrast between characters and background (Figure 2). Finally, we conduct MSER detection on this contrast-enhanced image. Figure 3 (c)illustrates the result of our contrast-enhanced MSER detection where all letters in the same word are separated.
2.2. Geometric Filtering
After locating bounding boxes of MSER, we design some simple geometric rules to filter out obvious non-text regions. Firstly, by assuming all characters have been separated, we limit the aspect ratio of each bounding box between 0.3 and 3. Secondly, text region candidates with low saturation (less than 0.3) or small area (less than 30 pixels) are unlikely to be text regions, thus they should be removed. Thirdly, since text may be surrounded by non-text CCs (e.g., the signboard containing characters is detected inFigure 1 (a)), we reject this kind of false positive by limiting the number of bounding boxes within a particular bounding box to three. For definitions of aspect ratio, saturation and area, see [12].

Previous | View All | Next
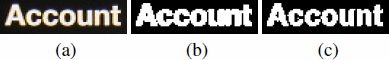
Previous | View All | Next
2.3. Stroke Width Extraction
Stroke width is defined as the length of a straight line from a text edge pixel to another along its gradient di-rection. The basic motivation of our stroke width extraction algorithm is that stroke width almost remains the same in a single character, however, there is significant change in stroke width in non-text regions as a result of their irregularity. There are several researches exploited this property, such as the work [1], [10], both of which calculate stroke width from a stroke boundary to another along gradient direction. Since skeleton is an effective tool to represent the structure of a region, inspired by the work [8] which uses skeleton to analyze text string straightness, we take advantage of skeleton to extract stroke width.
The initial step of stroke width extraction is to get skeletons of MSERs remained. On every foreground pixel on the skeleton, distance transform is applied to compute the Euclidean distance from this pixel to the nearest boundary of the corresponding MSER. Then we obtain a skeleton-distance map. This process is depicted in Figure 4. Figure 4 (a) illustrates a non-text MSER and text MSER from Figure 1 (a), and their corresponding skeleton and skeleton-distance map are shown in Figure 4 (b) andFigure 4 (c) respectively.
Variance on skeleton-distance map of each CC is computed to measure the difference between text regions and false positives. Table 1 lists values of variance obtained fromFigure 4 (c). Note that text characters have much smaller variances compared with the false positive. Based on this property we remove CCs with large variances. It can be seen in Figure 1 (c) that some false positives are eliminated after this procedure.

Previous | View All | Next
2.4. CC grouping
The main aim of CC grouping is to group adjacent characters detected in the previous steps into separated meaningful words and further reject false positives. Based on the observation that characters in the the same word usually share some similar properties, such as in-tensity, size, stroke width etc., these valuable information can be utilized in CC grouping. The details of our CC grouping method are illustrated below.
Center points of CCs are extracted as the first step of the proposed method. Then we obtain two maps, namely distance map and orientation map, by computing the Euclidean distance D and orientation angle between each CC pairs. If D is smaller thanM axDistance, which is defined as the maximum Euclidean distance from each CC to another, these two CCs are considered as adjacent candidates.
In the following step, we check between each adjacent pair of CCs on the orientation map. By assuming that texts usually lie in the horizonal direction, we set between ![]() and . Every pair of CC satisfying this rule is checked by similarity criteria below:
and . Every pair of CC satisfying this rule is checked by similarity criteria below:
- wi+wj >1.2 x D
- max(wi/wj,wj/wi) <5
- max(hi/hj, hj/hi) <2
- max(si/sj, sjsi) < 1.6
- max(ni/nj,nj/ni) <1.7
where ![]() denote width, height, mean of stroke width, intensity of bounding box respectively, and all the thresholds are obtained from ICDAR 2003 training set. This is based on the observation that adjacent characters in the same word usually share similar stroke width and intensity. Adjacent CCs obeying all the rules are considered as true adjacent text characters thus are grouped together. The result of our CC grouping method is illustrated in Figure 1 (d), it is obvious that all characters are grouped successfully, meanwhile, all false positives are rejected.
denote width, height, mean of stroke width, intensity of bounding box respectively, and all the thresholds are obtained from ICDAR 2003 training set. This is based on the observation that adjacent characters in the same word usually share similar stroke width and intensity. Adjacent CCs obeying all the rules are considered as true adjacent text characters thus are grouped together. The result of our CC grouping method is illustrated in Figure 1 (d), it is obvious that all characters are grouped successfully, meanwhile, all false positives are rejected.
EXPERIMENTS
To evaluate the robustness of the proposed algorith-m, we adopt the testing images in the public bench IC-DAR 2003 text locating dataset [3] in our experimen-t. Three widely used measurement criterions, namely precision(p), recall(r) and f measure ![]() are exploited to evaluate the performance of our method. In order to detect both bright and dark text objects, two rounds of MSER detection are performed for each testing image and the final result is the combination of two round results.
are exploited to evaluate the performance of our method. In order to detect both bright and dark text objects, two rounds of MSER detection are performed for each testing image and the final result is the combination of two round results.
As for the parameters setting, we set the gradient threshold as 30 and as 50 empirically. Besides, CCs whose stroke variance larger than 0.2 should be rejected. Furthermore, M axDistance is set as 300 to measure the maximum distance between two letters.
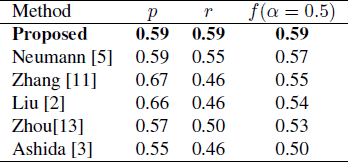
We compare our text detection result with a number of state-of-the-art methods tested on the same database using p, r and f criteria. The comparison result is shown in Table 2. We can see that the proposed approach has the highest recall rate of 0.59.
Recently, ICDAR 2011 Robust Reading Competition [7] was organized to evaluate the state-of-the-art process in text detection from complex nature scene. We also adopt the dataset used in this competition. Table 3 shows our text detection results on this dataset.
Figure 5 illustrates some results of our robust text detection algorithm. Estimated text regions are surrounded by blue bounding boxes. Note that the proposed method is insensitive to text color, font, size and position. With the proposed method, most text regions are detected, meanwhile, few false positives left.
We also present some failure examples in Figure 6. Because of the illumination problem, ‘Bus’ and ‘Times’ in Figure 6 (a) are not detected. All letters are discarded inFigure 6 (b) due to similar color between text and background. Moreover, characters ‘X’, ‘M’, and ‘L’ in Figure 6 (c) are eliminated because of large changes in stroke width, but this kind of text is rare in the dataset, which will not affect the overall result to a large ex-tent. We notice that the performance of our algorithm depends much on the potential text regions detected in the initial step (e.g., sometimes text cannot be detected using the contrast-enhanced MSER algorithm).

Previous | View All | Next

Previous | View All

CONCLUSION
In this work, a novel CC-based methodology for text detection in natural scene images is presented. MSER-![]() are first utilized as potential text regions. A significant novelty of our work compared with previous research is that we apply skeleton to extract stroke width. Moreover, our robust CC grouping method can not only group characters into separated words, but also eliminate false positives at the same time. Text detection results on the ICDAR datasets demonstrate that our algorithm performs comparable to other methods.
are first utilized as potential text regions. A significant novelty of our work compared with previous research is that we apply skeleton to extract stroke width. Moreover, our robust CC grouping method can not only group characters into separated words, but also eliminate false positives at the same time. Text detection results on the ICDAR datasets demonstrate that our algorithm performs comparable to other methods.