机器学习练习之正则化
这个练习是来自http://openclassroom.stanford.edu/MainFolder/DocumentPage.php?course=MachineLearning&doc=exercises/ex5/ex5.html
Regularized linear regression
之前已经做过线性回归, 我们知道线性回归就是要找到 一条直线去拟合训练数据,模型的损失函数为
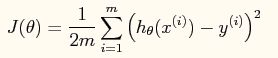
但是,这个模型可能会有些权重很大,有些权重很小,导致过拟合,就是过分拟合了训练数据,使得模型的复杂度提高,泛化能力较差,泛化能力就是对未知数据的预测能力。为了防止过拟合,通常会加入权重惩罚项,就是模型的正则项。正则项可以取不同的形式,在回归问题中取平方损失,就是参数的L2范数,也可以取L1范数。取平方损失时,模型的损失函数变为:
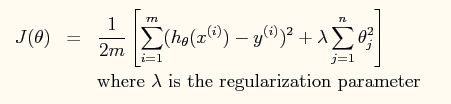
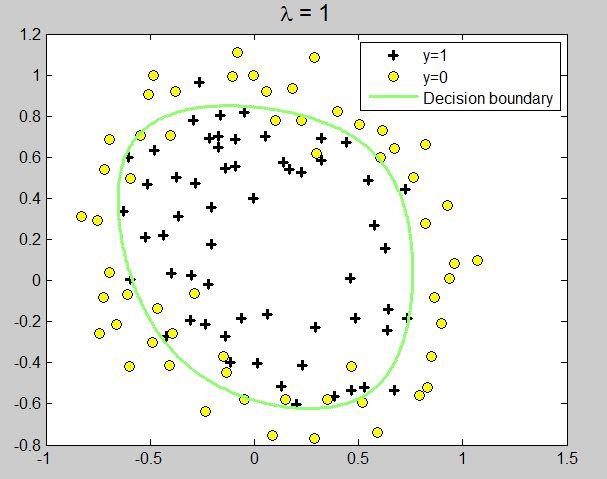
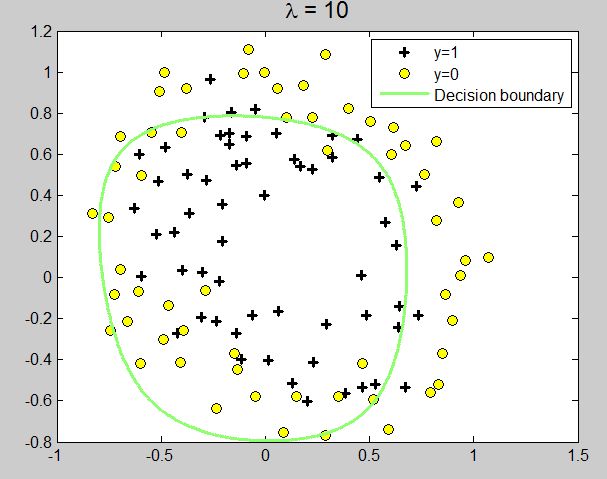
lambda是正则项系数,如果它的值很大,说明对模型的复杂度惩罚大,对拟合数据的损失惩罚小,这样它就不会过分拟合数据,在训练数据上的偏差较大,在未知数据上的variance较小,但是可能出现欠拟合的现象;相反,如果lambda值很小,说明比较注重对训练数据的拟合,在训练数据上的bias会小,但是可能会导致过拟合。
要求出theta使得损失J最小,可以将J对theta求导,得到结果如下:
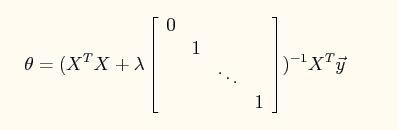
所以直接使用这个方程解就可以求出最佳的theta,不过也可以使得梯度下降算法,但是要折腾一下调步长参数。
程序如下:
%% Exercie: Regularized linear regression
% 正则化的线性回归
% 在简单的线性回归上加了正则项,用于惩罚权重,减少模型参数的搜索空间,
% 使得权重不会偏向于某些特征,模型更加平滑
%%
%% 数据初始化
x = load('ex5Linx.dat'); % x是只有一个特征,为一个列向量
y = load('ex5Liny.dat');
% 画图
figure
plot(x, y, 'o', 'MarkerFacecolor', 'r', 'MarkerSize', 8);
m = length(x); % m样本数量
x = [ones(m,1), x, x.^2, x.^3, x.^4, x.^5]; % 根据x构造特征向量,这里是多项式的特征,每个特征取(0-5)次方
n = size(x, 2); % 特征数量
%%
%% 梯度下降算法
% theta = zeros(n, 1); %初始化权重向量,一个列向量
% alpha = 0.01; %学习率,步长
% lambda = 0;
% MAX_ITR = 500;
% for i=1:MAX_ITR
% grad = (1/m).*(x'*(x*theta-y) + lambda*theta); %计算梯度
% theta = theta - alpha*grad; %更新权重
% end
% theta
% J = (0.5/m) * (sum((x*theta-y).^2) + lambda*sum(theta.^2))
% theta_norm = norm(theta)
%%
%% Normal equations
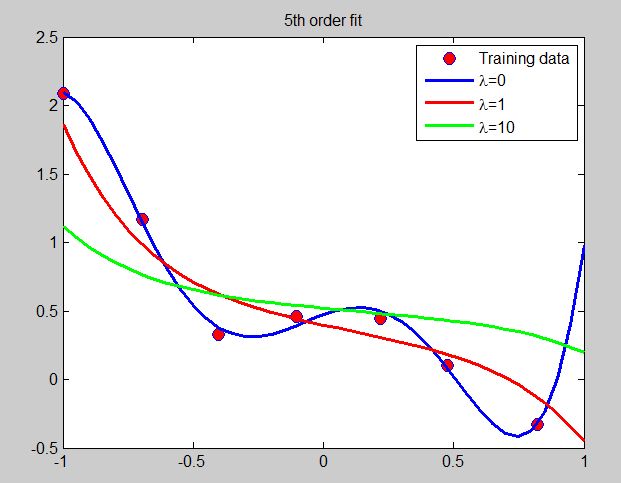
lambda = [0 1 10];
plotstyle = {'b', 'r', 'g'}
for i = 1:3
L = lambda(i).*eye(n);
L(1,1) = 0;
theta = (x'*x+L)\x'*y;
theta
J = (0.5/m) * (sum((x*theta-y).^2) + lambda(i)*sum(theta.^2))
theta_norm = norm(theta) %计算theta的L2范数
hold on
x_vals = (-1:0.05:1)'; %这个范围要根据x的范围确定
features = [ones(size(x_vals)), x_vals, x_vals.^2, x_vals.^3, ...
x_vals.^4, x_vals.^5];
plot(x_vals, features*theta, char(plotstyle(i)), 'LineWidth', 2)
legend(['lambda=', num2str(i)])
end
legend('Training data','\lambda=0', '\lambda=1', '\lambda=10');
title('5th order fit')
hold off
%%
Regularized Logistic regression
正则化的逻辑斯蒂回归模型也是在之前的 logistic regression上增加了正则项。
要使得上面的损失函数最小,同样这样使用牛顿方法,它的更新规则为:
其中一阶导和海森矩阵的形式有所变化:
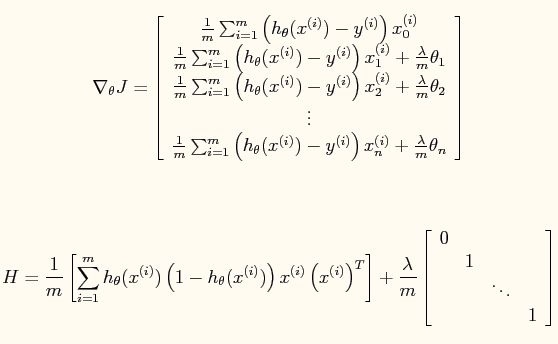
程序如下:
function out = map_feature(feat1, feat2) % MAP_FEATURE Feature mapping function for Exercise 5 % % map_feature(feat1, feat2) maps the two input features % to higher-order features as defined in Exercise 5. % % Returns a new feature array with more features % % Inputs feat1, feat2 must be the same size % % Note: this function is only valid for Ex 5, since the degree is % hard-coded in. degree = 6; out = ones(size(feat1(:,1))); for i = 1:degree for j = 0:i out(:, end+1) = (feat1.^(i-j)).*(feat2.^j); end end
%% Regularized logistic regression
% 加入正则项的逻辑斯蒂回归模型
%%
%% 数据初始化
x = load('ex5Logx.dat'); % 这里x的每一行是一个二维向量,表示有两个特征
y = load('ex5Logy.dat');
% Find the indices for the 2 classes
pos = find(y); neg = find(y==0);
x_unfeatured = x; % 保存未构造特征前的x
x = map_feature(x(:,1), x(:,2)); %由于原始数据下样本不是线性可分的,所以这里根据x的2个特征构造更多的特征
[m n] = size(x);
%%
%% 定义sigmoid函数
g = inline('1.0 ./ (1.0+exp(-z))', 'z');
%%
%% 牛顿算法
lambda = [0 1 10]; %正则项系数
MAX_ITR = 15;
for i = 1:3
theta = zeros(n, 1); %权重初始化
J = zeros(MAX_ITR, 1); %保存损失
for j = 1:MAX_ITR
h = g(x*theta); %计算sigmoid值
L = lambda(i) .* eye(n);
L(1,1) = 0;
J(j) = -(1.0/m).*sum(y.*log(h) + (1-y).*log(1-h)) + ...
lambda(i)/(2*m).*norm(theta(2:end))^2;
grad = (1/m) .* (x'*(h-y) + L*theta); %计算梯度
H = (1/m) .* x'*diag(h)*diag(1-h)*x + lambda(i)/m.*L; %计算海森矩阵
theta = theta - H\grad;
end
J
norm_theta = norm(theta)
figure
plot(x_unfeatured(pos, 1), x_unfeatured(pos, 2), 'k+', 'LineWidth', 2, 'MarkerSize', 7)
hold on
plot(x_unfeatured(neg, 1), x_unfeatured(neg, 2), 'ko', 'MarkerFaceColor', 'y', 'MarkerSize', 7)
hold on
%显示结果
u = linspace(-1, 1.5, 200);
v = linspace(-1, 1.5, 200);
z = zeros(length(u), length(v));
for ii = 1:length(u)
for jj = 1:length(v)
z(ii, jj) = map_feature(u(ii), v(jj))*theta;
end
end
z = z';
% plot z = 0
contour(u, v, z, [0,0], 'LineWidth', 2)
legend('y=1', 'y=0', 'Decision boundary')
title(sprintf('\\lambda = %g', lambda(i)), 'FontSize', 14)
hold off
end
结果: