Java学习之路——利用JDOM对xml文档进行解析等操作实例
JDOM的目的是成为 Java 特定文档模型,它简化与 XML 的交互并且比使用 DOM 实现更快。由于是第一个 Java 特定模型,JDOM 一直得到大力推广和促进。正在考虑通过“Java 规范请求 JSR-102”将它最终用作“Java 标准扩展”。从 2000 年初就已经开始了 JDOM 开发。
JDOM 与 DOM 主要有两方面不同。首先,JDOM 仅使用具体类而不使用接口。这在某些方面简化了 API,但是也限制了灵活性。第二,API 大量使用了 Collections 类,简化了那些已经熟悉这些类的 Java 开发者的使用。
JDOM 文档声明其目的是“使用 20%(或更少)的精力解决 80%(或更多)Java/XML 问题”(根据学习曲线假定为 20%)。JDOM 对于大多数 Java/XML 应用程序来说当然是有用的,并且大多数开发者发现 API 比 DOM 容易理解得多。JDOM 还包括对程序行为的相当广泛检查以防止用户做任何在 XML 中无意义的事。然而,它仍需要您充分理解 XML 以便做一些超出基本的工作(或者甚至理解某些情况下的错误)。这也许是比学习 DOM 或 JDOM 接口都更有意义的工作。
JDOM 自身不包含解析器。它通常使用 SAX2 解析器来解析和验证输入 XML 文档(尽管它还可以将以前构造的 DOM 表示作为输入)。它包含一些转换器以将 JDOM 表示输出成 SAX2 事件流、DOM 模型或 XML 文本文档。JDOM 是在 Apache 许可证变体下发布的开放源码。
1.以下是用JDOM对xml文档进行写入操作示例:
package com.lcq.java.jdom;
/**
* 利用JDom进行xml文档的写入操作
*
*
*/
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import org.jdom.Attribute;
import org.jdom.Comment;
import org.jdom.Document;
import org.jdom.Element;
import org.jdom.output.Format;
import org.jdom.output.XMLOutputter;
public class JdomTest1 {
/**
* @param args
* @throws Exception
* @throws FileNotFoundException
*/
public static void main(String[] args) throws Exception {
Document document = new Document();
//设置元素
Element book = new Element("book");
//将该元素设置为根元素
document.setContent(book);
//设置注释
Comment commet = new Comment("this is my comment");
//将注释加到根元素上
book.addContent(commet);
//设置元素
Element e1 = new Element("url");
e1.setAttribute(new Attribute("attr", "attr1"));
e1.setAttribute(new Attribute("attr1", "attr1"));
e1.setAttribute(new Attribute("attr2", "attr1"));
e1.setText("127.0.0.1");
//设置元素的属性
Attribute attr = new Attribute("path","localhost");
//将元素e1设置为根元素下的子元素
book.addContent(e1);
e1.setAttribute(attr);
Element e2 = new Element("title");
e2.setText("title");
e2.addContent(new Element("name").addContent(new Element("hello")));
book.addContent(e2);
//设置xml文档输出的格式
Format format = Format.getPrettyFormat();
XMLOutputter out = new XMLOutputter(format);
//将得到的xml文档输出到文件流中
out.output(document,new FileOutputStream("jdom.xml"));
}
}
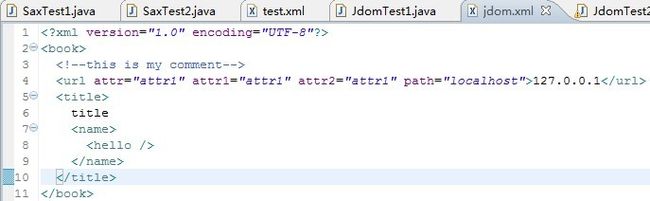
写入的xml文档如图:
2.以下是对xml文档进行解析:
package com.lcq.java.jdom;
/**
* 利用JDom进行xml文档的读取操作
*
*
*/
import java.util.List;
import org.jdom.Attribute;
import org.jdom.Document;
import org.jdom.Element;
import org.jdom.JDOMException;
import org.jdom.input.SAXBuilder;
public class JdomTest2 {
/**
* @param args
* @throws Exception
* @throws JDOMException
*/
public static void main(String[] args) throws Exception {
//建立解析器
SAXBuilder builder = new SAXBuilder();
//将解析器与文档关联
Document doc = builder.build("jdom.xml");
//读取根元素
Element e = doc.getRootElement();
//输出根元素的名字
System.out.println(e.getName());
//获得元素
Element url = e.getChild("url");
//得到元素的值
System.out.println(url.getText());
//得到元素的属性列表
List list = url.getAttributes();
for(int i = 0; i < list.size();i++){
Attribute attrs = (Attribute)list.get(i);
String name = attrs.getName();
String value = (String)attrs.getValue();
//将属性的名字和值输出
System.out.println(name + "=" + value);
}
}
}
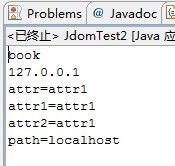
运行的结果是:
用JDOM对xml进行处理可见方便多了,它是处理xml的方式更加符合我们编程习惯。感觉不错。