使用Jpcap进行java平台下的ipv6网络抓包
前阵子做网络实验的时候,要求做一个抓包程序,还要能处理ipv6的报文。如此底层的操作,通常我们都认为是C或者C++的分内事,但其实java也可以做到这一点!
java的网络功能
稍微熟悉jdk的人都知道java对于网络的支持基本都在传输层以上,也就是说java代码能操作到的数据最底层也就是面向tcp、udp,动不动就被封装成“流”或是socket什么的。如果要实现抓包,通常都要涉及到数据链路层的操作。在c或c++,我们可以使用大名鼎鼎的wincap;而在java平台,现在已经有人将wincap的接口封装成为jar包了,所以我们只需要下载wincap和jpcap,安装后就能直接用java代码操作底层数据流了
jpcap下载:http://netresearch.ics.uci.edu/kfujii/jpcap/doc/download.html
这里不打算细述jpcap的基本用法,只是记录使用jpcap的一些心得,以及jpcap的一些缺陷和不足
jpcap功能简述
JVM从来没有提供过操作网络底层数据的接口,我估计未来也不会,因为这很明显不是java“应该和擅长做的事情”,不过还好有JNI这个东西,让java的触角可以延伸到许多c++才能做的地方。jpcap的原理说来其实很简单,就是利用JNI以java开发者喜闻乐见的方式封装了wincap的接口,所以如果你熟悉wincap,相信jpcap只是小菜一碟
jpcap的jar包很小,里面封装的类也不多,如下:
Class Hierarchy
- java.lang.Object
- jpcap.packet.DatalinkPacket
- jpcap.packet.EthernetPacket
- jpcap.packet.IPv6Option
- jpcap.JpcapCaptor
- jpcap.JpcapSender
- jpcap.JpcapWriter
- jpcap.NetworkInterface
- jpcap.NetworkInterfaceAddress
- jpcap.packet.Packet
- jpcap.packet.ARPPacket
- jpcap.packet.IPPacket
- jpcap.packet.ICMPPacket
- jpcap.packet.TCPPacket
- jpcap.packet.UDPPacket
- jpcap.packet.DatalinkPacket
类的用法基本上看看文档就知道了,去google一下“jpcap”的教程也有一大把,基本过程如下:
抓取的报文通常都继承了jpcap.packet.Packet 类,可以通过datalink字段获得该Packet的数据链路层帧,也就是jpcap.packet.DatalinkPacket,从而进行数据链路层的包解析
针对常见的报文,如ARP、IP报文,jpcap都有相应的类,例如IPPacket类就封装了IP报文的各个字段(包括IPV4和IPV6),因此,程序主要的逻辑过程就是用java的instanceof关键字,判断属于哪一类报文,从而进行相应的处理。
一切都很方便!下面重点说一下如何处理ipv6
jpcap for ipv6
从文档可以看出,jpcap对ipv6有一定的支持,提供了不少静态字段和类用于表示ipv6的包,但是在使用过程中,我发现jpcap对于ipv6的支持还是远远不够的(我使用的jpcap版本为0.6),最主要问题就是缺少对隧道IPV6的支持
现在很多地方由于硬件或其他限制,使用的还不是纯粹的ipv6,譬如我宿舍的网络就是使用隧道的,在配置ipv6时必须输入“netsh interface ipv6 isatap set router”命令来设置isatap隧道路由器的地址,否则无法连接到www.kame.net等网站。如果用ethereal等软件进行抓包,就可以看出是在ipv4的PDU里面包含了ipv6的报文,例如:
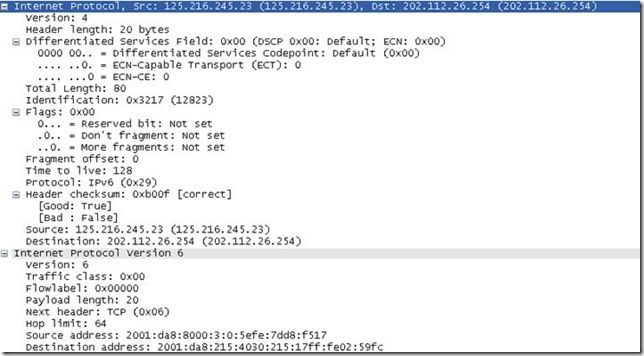
可见是使用了隧道机制的ipv6,在ipv4报文的protocol字段,指明了是“ipv6”
在遇到隧道形式的ipv6时,JPCAP并没有提供相应的封装,抓获的报文是“jpcap.packet.IPPacket”,但JPCAP仅仅将其解析为ipv4报文,隧道ipv6报文全部被认为是ipv4的载荷。我尝试使用了JPCAP提供的一个demo程序抓取隧道ipv6报文,发现其仍旧无法正确解析v6的内容。在参考了JPCAP的文档后,发现 JPCAP不能直接提供隧道ipv6的功能,,看来是jpcap的设计者暂时没有考虑到“v6 on v4”的情况,因此只能像wincap那样手动处理字节序列。
JPCAP中每个Packet的子类都有一个字段是data[],可以获得报文载荷,例如jpcap.packet.IPPacket.data[]获得的就是IP报文的载荷。处理比特位对java来说是弱项,很多方面不如c或c++那样方便,但撇开效率不谈,仍然是有办法做到的,只要掌握一些java环境下的字节移位操作即可。下面是我的程序实例:
/** * 由于jpcap未提供隧道ipv6的封装,故专门写一函数,针对ipv4中作为负荷的ipv6内容的字节流进行解析 * @param ipp * @return */ private DefaultMutableTreeNode parseTunnelIpv6(IPPacket ipp){ byte[] ipv6byte = ipp.data; if(ipv6byte.length <=40){ return null; } DefaultMutableTreeNode ipv6Node = new DefaultMutableTreeNode("隧道IPv6报文"); //version int version = ipv6byte[0]>>>4; ipv6Node.add(new DefaultMutableTreeNode("版本(version):"+ version)); //Traffic Class int trafficClass = ipv6byte[0]<<4 + ipv6byte[1]>>>4; ipv6Node.add(new DefaultMutableTreeNode("通信流类别(Traffic Class):"+ trafficClass)); //flow label String flowLabel = "0x" + (ipv6byte[1] & 0x0f) + (ipv6byte[2]>>>4) + (ipv6byte[2]& 0x0f) + (ipv6byte[3]>>>4) + (ipv6byte[3]& 0x0f); ipv6Node.add(new DefaultMutableTreeNode("流标签(Flow Label):"+ flowLabel)); //Payload int payloadLength = ipv6byte[4]<<8 + ipv6byte[5]&0xff; ipv6Node.add(new DefaultMutableTreeNode("有效载荷长度(Payload Length):"+ payloadLength)); //next header int nextHeader = ipv6byte[6]&0xff; DefaultMutableTreeNode nextHeaderNode = this.getIpv6NextHeader((short)nextHeader); // nextHeaderNode.add(this.getIpv6Option(ipv6byte[6])); ipv6Node.add(nextHeaderNode); //hop limit int hopLimit = ipv6byte[7]&0xff; ipv6Node.add(new DefaultMutableTreeNode("跳数限制(Hop Limit):"+ hopLimit)); //source address byte[] sourceAddByte = Arrays.copyOfRange(ipv6byte, 8, 24); String sourceAdd; try { sourceAdd = InetAddress.getByAddress(sourceAddByte).toString(); } catch (UnknownHostException e) { // TODO Auto-generated catch block e.printStackTrace(); sourceAdd = "0::0"; } ipv6Node.add(new DefaultMutableTreeNode("源地址(Source Address):"+ sourceAdd)); //target address byte[] destAddByte = Arrays.copyOfRange(ipv6byte, 24, 40); String destAdd; try { destAdd = InetAddress.getByAddress(destAddByte).toString(); } catch (UnknownHostException e) { // TODO Auto-generated catch block e.printStackTrace(); destAdd = "0::0"; } ipv6Node.add(new DefaultMutableTreeNode("目的地址(Destination Address):"+ destAdd)); return ipv6Node; }
里面的关键部分是对字节的移位操作,分以下几个步骤:
- 获得负载信息,每个Package类都有一个“字节数组”字段data[],包含了报文的负载,如:byte[] ipv6byte = ipp.data;
- 然后根据ipv6的报头结构,逐个处理data里面的字节
- 比如头四位是报文的version字段,可以这样处理:int version = ipv6byte[0]>>>4; 关键是搞清楚java里面的右移操作符,“>>>”是指右移并补0,而“>>”则是补1,需要一些基本的计算机组成原理的知识
- 紧接着,是八个比特位的“trafficClass”字段,需要把data[0]的后四位跟data[1]的前四位拼起来:int trafficClass = ipv6byte[0]<<4 + ipv6byte[1]>>>4;
- 还有一个需要注意的地方,就是java里面byte类型是有符号的,即字节的最高位是符号位。而ip报文是无符号的,所以要手动转换一下,如:int nextHeader = ipv6byte[6]&0xff; 否则可能得到一个负号的int
其他的字段同理可得
附一张截图,我自己做的一个抓包程序抓到的隧道ipv6报文
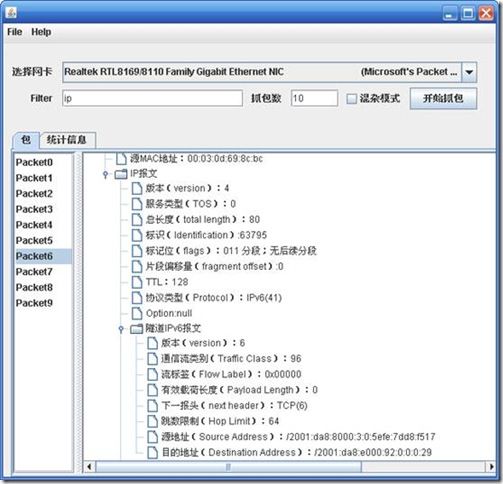
最后是广告时间,推荐一个MyEclipse平台下的SWING开发插件:M4M。如果你用过NetBean,应该对里面的GUI开发工具印象深刻,可以支持拖拽和自动对齐,感觉已经很接近VC,至少比以往的java GUI开发工具好很多。但是NetBean开发出来的GUI代码不能在Eclipse里面用,现在有了M4M,也一样可以实现这种方便的开发模式了,至少对我这种GUI傻瓜来说,方便了不少
小结
JPCAP由于对隧道ipv6的支持不够,必须手工进行解析,那样如果使用隧道机制,则对于所有上层协议的解析都要手工进行,jpcap里面的“TCPPacket,UDPPacket”等类就作废了,希望以后的版本可以解决这个问题
本demo的源码下载:http://download.csdn.net/source/2256471