线性区的数据结构
上一篇博文我们会看到,内核使用一种新的资源成功实现了对进程动态内存的推迟分配。当用户态进程请求动态内存时,并没有获得请求的页框,而仅仅获得对一个新的线性地址区间的使用权,而这一线性地址区间就成为进程地址空间的一部分。这一区间就叫做“线性区”。本博,我们就来详细讨论这个线性区。
1 线性区数据结构
Linux通过类型为vm_area_struct的对象实现线性区,它的字段如下所示:
struct vm_area_struct {
struct mm_struct * vm_mm; /* 指向线性区所属的内存描述符 */
unsigned long vm_start; /* 线性区内的第一个线性地址 */
unsigned long vm_end; /* 线性区之后的第一个线性地址 */
/* linked list of VM areas per task, sorted by address 进程链表中的下一个线性区*/
struct vm_area_struct *vm_next;
pgprot_t vm_page_prot; /* 线性区中页框的访问许可权 */
unsigned long vm_flags; /* 线性区的标志 */
struct rb_node vm_rb; /* 用于红-黑树的数据 */
/*
* For areas with an address space and backing store,
* linkage into the address_space->i_mmap prio tree, or
* linkage to the list of like vmas hanging off its node, or
* linkage of vma in the address_space->i_mmap_nonlinear list.
*/
union {
struct {
struct list_head list;
void *parent; /* aligns with prio_tree_node parent */
struct vm_area_struct *head;
} vm_set;
struct raw_prio_tree_node prio_tree_node;
} shared; /* 链接到反映射所使用的数据结构 */
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
struct list_head anon_vma_node; /* Serialized by anon_vma->lock 指向匿名线性区链表的指针 */
struct anon_vma *anon_vma; /* Serialized by page_table_lock 指向anon_vma数据结构的指针 */
/* Function pointers to deal with this struct. 指向线性区的方法 */
struct vm_operations_struct * vm_ops;
/* Information about our backing store: */
unsigned long vm_pgoff; /* 在映射文件中的偏移量。对匿名页,
它等于0或vm_start/PAGE_SIZE */
struct file * vm_file; /* 指向映射文件的文件对象(如果有的话) */
void * vm_private_data; /* 指向内存区的私有数据 */
unsigned long vm_truncate_count;/* 释放非线性文件内存映射中的一个线性地址区间时使用 */
#ifndef CONFIG_MMU
atomic_t vm_usage; /* refcount (VMAs shared if !MMU) */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
};
每个线性区描述符表示一个线性地址区间。vm_start字段包含区间的第一个线性地址,而vm_end字段包含区间之外的第一个线性地址。vm_end - vm_start表示线性区的长度。vm_mm字段指向拥有这个区间的进程的mm_struct内存描述符。我们稍后将描述vm_area_struct的其他字段。
进程所拥有的线性区从来不重叠,并且内核尽力把新分配的线性区与紧邻的现有线性区进行合并。两个相邻区的访问权限如果相匹配,就能把它们合并在一起。
当一个新的线性地址区间加入到进程的地址空间时,内核检查一个已经存在的线性区是否可以扩大。如果不能,就创建一个新的线性区。类似地,如果从进程的地址空间删除一个线性地址区间,内核就要调整受影响的线性区大小。有些情况下,调整大小迫使一个线性区被分成两个更小的部分(从理论上说,如果没有空闲的内存给新的内存描述符使用,删除一个线性地址区间可能会失败,不过这种情况出现的概率太小太小)。
vm_ops字段指向vm_operations_struct数据结构,该结构中存放的是线性区的方法。只有如表下所示的几种方法可应用于UMA系统:
struct vm_operations_struct {
/* 当把线性区增加到进程所拥有的线性区集合时调用 */
void (*open)(struct vm_area_struct * area);
/* 当从进程所拥有的线性区集合删除线性区时调用 */
void (*close)(struct vm_area_struct * area);
/* 当进程试图访问RAM中不存在的一个页,但该页的线性地址属于线性区时,由缺页异常处理程序调用 */
struct page * (*nopage)(struct vm_area_struct * area, unsigned long address, int *type);
unsigned long (*nopfn)(struct vm_area_struct * area, unsigned long address);
/* 设置线性区的线性地址(预缺页)所对应的页表项时调用。主要用于非线性文件内存映射 */
int (*populate)(struct vm_area_struct * area, unsigned long address, unsigned long len, pgprot_t prot, unsigned long pgoff, int nonblock);
/* notification that a previously read-only page is about to become
* writable, if an error is returned it will cause a SIGBUS */
int (*page_mkwrite)(struct vm_area_struct *vma, struct page *page);
#ifdef CONFIG_NUMA
int (*set_policy)(struct vm_area_struct *vma, struct mempolicy *new);
struct mempolicy *(*get_policy)(struct vm_area_struct *vma,
unsigned long addr);
int (*migrate)(struct vm_area_struct *vma, const nodemask_t *from,
const nodemask_t *to, unsigned long flags);
#endif
};
进程所拥有的所有线性区是通过一个简单的链表链接在一起的。出现在链表中的线性区是按内存地址的升序排列的;不过,每两个线性区可以由未用的内存地址区隔开。每个vm_area_struct元素的vm_next字段指向链表的下一个元素。内核通过进程的内存描述符的mmap字段来查找线性区,其中mmap字段指向链表中的第一个线性区描述符。
内存描述符的map_count字段存放进程所拥有的线性区数目。默认情况下,一个进程可以最多拥有65536个不同的线性区,系统管理员可以通过写/proc/sys/vm/max_map_count文件来修改这个限定值。
下图显示了进程的地址空间、它的内存描述符以及线性区链表三者之间的关系。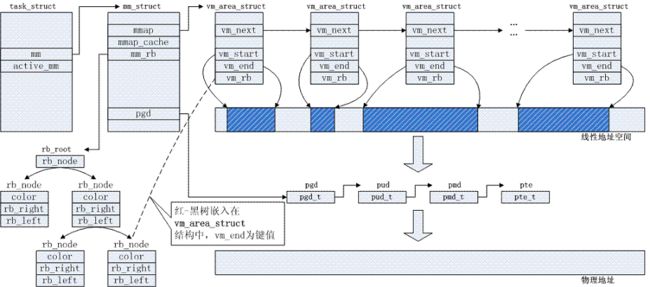
内核频繁执行的一个操作就是查找包含指定线性地址的线性区。由于链表是经过排序的,因此,只要在指定线性地址之后找到一个线性区,搜索就可以结束。
然而,仅当进程的线性区非常少时使用这种链表才是很方便的,比如说只有一二十个线性区。在链表中查找元素、插入元素、删除元素涉及许多操作,这些操作所花费的时间与链表的长度成线性比例。
尽管多数的Linux进程使用的线性区的数量非常少,但是诸如面向对象的数据库,或malloc()的专用调试器那样过于庞大的大型应用程序可能会有成百上千的线性区。在这种情况下,线性区链表的管理变得非常低效,因此,与内存相关的系统调用的性能就降低到令人无法忍受的程度。
因此,Linux 2.6把内存描述符存放在叫做红-黑树(red-black tree)的数据结构中。
2 红-黑树算法
红-黑树是一个扩展了的平衡二叉树。我们先来回忆回忆二叉排序树的概念:每个元素(或说节点)通常有两个孩子:左孩子和右孩子。树中的元素被排序。对关键字为N的节点,它的左子树上的所有元素的关键字都比N小;相反,它的右子树上的所有元素的关键字都比N大【如图(a)所示】;节点的关键字被写入节点内部。而除了具有基本的二叉排序树的特点以外,红-黑树必须满足下列5条规则:
1、每个节点必须或为黑或为红。
2、树的根必须为黑。
3、新插入的节点必须为红色。
4、红节点的孩子必须为黑。
5、从一个节点到后代叶子节点的每个路径都包含相同数量的黑节点。当统计黑节点个数时,空指针也算作黑节点。
这4条规则确保具有n个内部节点的任何红一黑树其高度最多为2 × log(n+l)。
在红-黑树中搜索一个元素因此而变得非常高效,因为其操作的执行时间与树大小的对数成线性比例。换句话说,双倍的线性区个数只多增加一次循环。
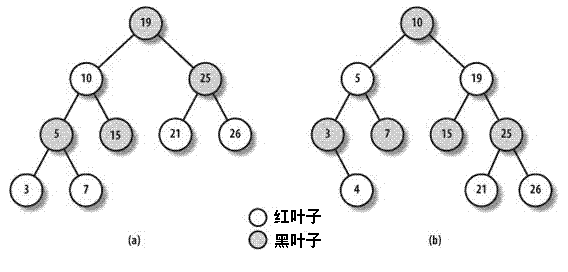
例如,假如值为4的一个元素必须插入到图(a)所示的红一黑树中。它的正确位置是关键值为3的节点的右孩子,但是,一旦把它插入,值为3的红节点就具有红孩子,因此而违背了规则3。为了满足这条规则,值为3、4、7的节点颜色就得改变。但是,这种操作又会违背规则5,因此,算法在以关键值为19的节点为根节点的子树上执行“旋转”操作,产生如图(b)所示的新红一黑树。这看起来较复杂,但是,在红-黑树上插人或删除一个元素只需要少量的操作——这个操作的复杂度仅仅与树大小的对数成线性比例。
因此,为了存放进程的线性区,Linux既使用了链表,也使用了红-黑树。这两种数据结构包含指向同一线性区描述符的指针,当插入或删除一个线性区描述符时,内核通过红-黑树搜索前后元素,并用搜索结果快速更新链表而不用扫描链表。
链表的头由内存描述符的mmap字段所指向。任何线性区对象都在vm_next字段存放指向链表下一个元素的指针。红-黑树的首部由内存描述符的mm_rb字段所指向。任和线性区对象都在类型为rb_node的vm_rb字段中存放节点颜色以及指向双亲、左孩子和右孩子的指针。
一般来说,红-黑树用来确定含有指定地址的线性区,而链表通常在扫描整个线性区集合时来使用。
3 线性区访问权限
在讲述下一部分以前,我们先阐明页与线性区之间的关系。正如前面博文中所提到的,我们使用“页”这个术语既表示一组线性地址和其物理地址对应的关系。尤其是,我们把介于0-4095之间的线性地址区间称为第0页,介于4096-8191之间的线性地址区间称为第1页,依此类推。因此每个线性区都由一组号码连续的页所构成。
在前面我们已经讨论了与页相关的两种标志:
- 在每个页表项中存放的几个标志,如:Read/Write、Present等(参见的“基于80x86的Linux的分段和分页机制”博文)。
- 存放在每个页描述符flags字段中的一组标志(参见的“Linux页框管理”博文)。
第一种标志由80x86硬件用来检查能否执行所请求的寻址类型;第二种标志由Linux用于许多不同的目的。
现在介绍第三种标志,即与线性区的页相关的那些标志。它们存放在vm_area_struct描述符的vm_flags字段中。一些标志给内核提供有关这个线性区全部页的信息,例如它们包含有什么内容,进程访问每个页的权限是什么。另外的标志描述线性区自身,例如它应该如何增长(这些标志位于include/linux/Mm.h):
VM_READ:页是可读的
VM_WRITE:页是可写的
VM_EXEC:页是可执行的
VM_SHARED:页可以由几个进程共享
VM_MAYREAD:可以设置VM_READ标志
VM_MAYWRITE:可以设置VM_WRITE标志
VM_MAYEXEC:可以设置VM_EXEC标志
VM_MAYSHARE:可以设置VM_SHARE标志
VM_GROWSDOWN:线性区可以向低地址扩展
VM_GROWSUP:线性区可以向高地址扩展
VM_SHM:线性区用于IPC的共享内存
VM_DENYWRITE:线性区映射一个不能打开用于写的文件
VM_EXECUTABLE:线性区映射一个可执行文件
VM_LOCKED:线性区中的页被锁住,且不能换出
VM_IO:线性区映射设备的I/O地址空间
VM_SEQ_READ:应用程序顺序地访问页
VM_RAND_READ:应用程序以真正的随机顺序访问页
VM_DONTCOPY:当创建一个新进程时不拷贝线性区
VM_DONTEXPAND:通过mremap()系统调用禁止线性区扩展
VM_RESERVED:线性区是特殊的(如:它映射某个设备的I/O地址空间),因此它的页不能被交换出去
VM_ACCOUNT:创建IPC共享线性区时检查是否有足够的空闲内存用干映射
VM_HUGETLB:通过扩展分页机制处理线性区中的页
VM_NONLINEAR:线性区实现非线性文件映射
线性区描述符所包含的页访问权限可以任意组合。例如,存在这样一种可能性,允许一个线性区中的页可以执行但是不可以读取。为了有效地实现这种保护方案,与线性区的页相关的访问权限(读、写及执行)必须被复制到相应的所有表项中,以便由分页单元直接执行检查。换句话说,页访问权限表示何种类型的访问应该产生一个缺页异常。后面的博文我们会看到,Linux委派缺页处理程序查找导致缺页的原因,因为缺页处理程序实现了许多页处理策略。
页表标志的初值(注意,同一线性区所有页标志的初值必须一样)存放在vm_area_struct描述符的vm_page_prot字段中。当增加一个页时,内核根据vm_page_prot字段的值设置相应页表项中的标志。
typedef struct { unsigned long long pgprot; } pgprot_t; /* include/asm-i386/Page.h */
那么,有些兄弟会问了,为啥不能把线性区的访问权限直接转换成页保护位,这是因为:
- 在某些情况下,即使由相应线性区描述符的vm flags字段所指定的某个页的访问权限允许对该页进行访问,但是,对该页的访问还是应当产生一个缺页异常。例如“写时复制”的情况,内核可能决定把属于两个不同进程的两个完全一样的可写私有页(它的VM_SHARE标志被清0)存入同一个页框中;在这种情况下,无论哪一个进程试图改动这个页都应当产生一个异常。
- 80x86处理器的页表仅有两个保护位,即Read/Write和User/Supervisor标志。此外,一个线性区所包含的任何一个页的User/Supervisor标志必须总置为1,因为用户态进程必须总能够访问其中的页。
- 启用PAE的新近Intel Pentium 4微处理器,在所有64位页表项中支持NX(No eXecute)标志。
如果内核没有被编译成支持PAE,那么Linux采取以下规则以克服80x86微处理器的硬件限制:
- 读访问权限总是隐含着执行访问权限,反之亦然。
- 写访问权限总是隐含着读访问权限。
反之,如果内核被编译成支持PAE,而且CPU有NX标志,Linux就采取不同的规则:
- 行访问权限总是隐含着读访问权限。
- 访问权限总是隐含着读访问权限。
因此,要根据以下规则精简由读、写、执行和共享访问权限的16种可能组合:
- 如果页具有写和共享两种访问权限,那么,Read/Write位被设置为1。
- 如果页具有读或执行访问权限,但是既没有写也没有共享访问权限,那么,Read/Write位被清0。
- 如果支持NX位,而且页没有执行访问权限,那么,把NX位设置为1。
- 如果页没有任何访问权限,那么,Presen七位被清0,以便每次访问都产生一个缺页异常。然而,为了把这种情况与真正的页框不存在的情况相区分,Linux还把Page size位置为1(你可能认为Page size位的这种用法并不正当,因为这个位本来是表示实际页的大小。但是,Linux可以侥幸逃脱这种骗局,因为80 x 86芯片在页目录项中检查Page size位,而不是在页表的表项中检查该位。)
访问权限的每种组合所对应的精简后的保护位存放在protection_map数组的16个元素中(mm/Mmap.c):
pgprot_t protection_map[16] = {
__P000, __P001, __P010, __P011, __P100, __P101, __P110, __P111,
__S000, __S001, __S010, __S011, __S100, __S101, __S110, __S111
};
//include/asm-i386/Pgtable.h
#define __P000 PAGE_NONE
#define __P001 PAGE_READONLY
#define __P010 PAGE_COPY
#define __P011 PAGE_COPY
#define __P100 PAGE_READONLY_EXEC
#define __P101 PAGE_READONLY_EXEC
#define __P110 PAGE_COPY_EXEC
#define __P111 PAGE_COPY_EXEC
#define __S000 PAGE_NONE
#define __S001 PAGE_READONLY
#define __S010 PAGE_SHARED
#define __S011 PAGE_SHARED
#define __S100 PAGE_READONLY_EXEC
#define __S101 PAGE_READONLY_EXEC
#define __S110 PAGE_SHARED_EXEC
#define __S111 PAGE_SHARED_EXEC
例如:
#define COPY_EXEC /
__pgprot(_PAGE_PRESENT | _PAGE_USER | _PAGE_ACCESSED)
其他的情况我们就不一一去关注了,有兴趣的可以到Pgtable.h里去找找。