VMDK之动态扩展文件解析思路
版权声明:对于本博客所有原创文章,允许个人、教育和非商业目的使用,但务必保证文章的完整性且不作任何修改地以超链接形式注明原始作者、出处及本声明。
博客地址:http://blog.csdn.net/shuxiao9058
原始作者:季亚
请容许我发一点牢骚,本人小菜。起初,刚到公司时被公司研发部副总带到另外一个部门,说是搞数据分析的,但到那边后发现做的东西的确蛮不错的,只是害怕到那边后不让做C++相关方面的开发,所以还是对副总说对这个工作不是很喜欢,又说对于XX组比较感兴趣,才得以留下来做数据恢复工作。不知道以后还会做什么,心想不管做什么都要尽力吧。
也就是刚进公司的那天下午,经理说给我一个项目做,就是研究以动态扩展方式生成的VMDK文件,将其解析成DD文件。
于是,开始漫长的研究,起初脑袋有些大了。对于C++文件流的处理不是很熟悉,而且竟然也不是很知道seek函数与写文件时指针是动态移动的,呵呵,都说了嘛,我很菜的,不过我有一颗热爱学习的心。
现在,功能已经基本实现,只是代码可能需要略加修改,为了方便他人以及对自己近期工作进行总结,于是把学习及解析的思想介绍一下,也算是本人即将踏入数据恢复的处女作吧(也不知道这算不算作品)。
一、 概述
关于VMDK的资料还是蛮多的,主要有VMware官方提供的技术文档(点此下载)、Google Code中的一个格式说明文档(点此下载)和相关开源源码等。
二、 工具
需要使用的工具主要有WinHex、FTK Imager、VMware 、010 Editor等,感觉现在对于WinHex使用的还不够熟悉。
三、 组成
一个磁盘可由若干个link(姑且称之为链,如图1所示)或一个VMDK Extent文件(也就是实际存储数据的文件)组成。而且,一个link可由一个或多个扩展文件(extent file)组成(如图2所示),并通过descriptor file(姑且称之为描述文件)中的CID、parentCID记录链接起来。

图1 构成一个虚拟磁盘的链

图2 多个扩展文件(Extents)组成一个link
三、 文件结构
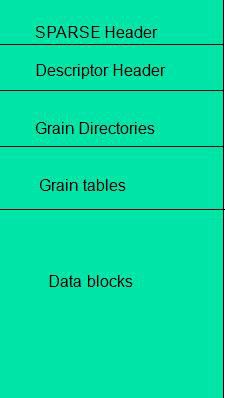
3.1 文件头
解析文件应该少不了说文件头吧,最起码对于VMDK来说文件头中的至关重要,主要包含验证信息(魔数)、存储容量(capacity)、文件内部结构的偏移(descriptorOffset 、rgdOffset 、gdOffset、overHead)等。如图1所示即为Hosted Sparse Extents的文件头结构体,注释内容为在第一扇区中的偏移。
typedef uint64 SectorType;
typedef uint8 Bool;
typedef struct SparseExtentHeader
{
uint32 magicNumber; // 0x00 - 0x03
uint32 version; // 0x04 - 0x07
uint32 flags; // 0x08 - 0x0B
SectorType capacity; // 0x0C - 0x13
SectorType grainSize; // 0x14 - 0x1B
SectorType descriptorOffset; // 0x1C - 0x23
SectorType descriptorSize; // 0x24 - 0x2B
uint32 numGTEsPerGT; // 0x2C - 0x2F
SectorType rgdOffset; // 0x30 - 0x37
SectorType gdOffset; // 0x38 - 0x3F
SectorType overHead; // 0x40 - 0x47
char uncleanShutdown; // 0x48
char singleEndLineChar; // 0x49 - 0x4C
char nonEndLineChar; // 0x49
char doubleEndLineChar1; // 0x4A
char doubleEndLineChar2; // 0x4B
uint16 compressAlgorithm; // 0x4C
uint8 pad[433];
} SparseExtentHeader;
由以上结构可以发现,文件头信息共占512个字节,即一个扇区。
3.2 需要注意
- 所有类型为SectorType的数据均以扇区为单位,即在计算偏移或数目的时候都要乘以512(0x200);
- magicNumber的值被初始化为0x564d444b(“'V' 'M' 'D' 'K'”,注意以小端序列存储),这样在读取的时候可以通过magicNumber判断文件是否为有效的VMDK 扩展文件(extent file);
- capacity字段存储的为该VMDK扩展文件的大小;
- grainSize 字段存储的为一个数据块(block,即grain)的大小为128扇区,亦即64KB;
- descriptorOffset为内嵌在extent文件中的描述信息的偏移,如果没有嵌入的描述信息,那么该字段将全为0,注意该描述信息包含了该VMDK文件的唯一ID和该VMDK文件名,有时候当其作为一个快照磁盘(snapshot disk)时也会包含Parent CID字段;
- descriptorSize当descriptorOffset有效(即不为零)时将给出内嵌描述信息的大小;
- numGTEsPerGT字段存储的为一个grain table所存储的记录个数,对于虚拟磁盘该记录的值为512;
- rgdOffset字段存储的为redundant(可以翻译为“冗余的”吗?总感觉不太合适)第0层(level 0)元数据(metadata)的偏移,这里要注意VMware Software在磁盘上保留了两份grain directories和grain tables(即元数据)提高虚拟磁盘的韧性,以防止主机硬盘损坏(详见官方文档);
- Overhead表示被元数据所占据的扇区数目,即从扇区号为metadata的扇区开始即为虚拟磁盘真实存储的数据;
- uncleanShutdown字段的具体含义详见官方文档。
3.3 Hosted Sparse Extent Metadata
在稀疏型扩展文件中有两层元数据,第0层元数据被称作一个grain directory或一个GD,第1层元数据被称为一个grain table或一个GT,第0层元数据中的每个记录均指向一个第1层元数据块,第1层元数据的大小是固定的(即每个GT包含512个记录),其中的每个记录均指向一块真实的存储数据单元(即grain),如图4和图5所示。
图4 扩展文件之元数据
图5 VMDK体系结构和设计
Grain Directory
Grain directory中的条目称作grain directory entry或GDE,一个grain directory条目占32位数据。
grain directories中记录数由VMDK扩展文件的大小所决定,其内存储是所对应grain table的偏移,每个grain table有512个记录,grain table中的每个记录存储的为实际数据块的偏移。2GbMaxExtentSparse文件最多有64个grain directories,可由以下算法计算得出(注意单位要统一,即均可以字节或扇区数进行计算):
number of grain directory entries = maximum data size / ( number of grain table entries * grain size );
if( maximum data size % ( number of grain table entries * grain size ) > 0 )
{
number of grain directory entries += 1;
}
由于一个VMDK扩展文件最多包含4192256个扇区,有:number of grain directory entries = 4192256 / ( 512 * 128 ) = 63,又4192256 % ( 512 * 128 ) = 63488 > 0,所以number of grain directory entries=63+1=64,即每个VMDK扩展文件最多包含64个grain directories(备注:这里我是以扇区的方式进行计算的)。
Grain Table
Grain table中的条目称作grain table entry或GTE,一个grain table条目占32位数据。
GTE内所存储的是所对应grain的偏移,每个grain table有512个记录。因此,一个grain table的大小为2KB:512*32/8byte=2048byte=2KB。
在一个新创建的稀疏型扩展文件中,所有的GTEs均初始化为0,这意味着该GT所指向的grain还没有分配,一旦创建grain,相应的GTE将记录该grain的偏移。当创建一个稀疏型扩展文件时,所有的GTs也被创建,因此从技术上来说GD并非必要的,然后由于历史原因一直延用至今。忽略GD所提供的抽象,可以以任意大小的GDEs块对GT重新进行定义,如果没有GDs,那就没有必要强制每一个GT的长度为512。
Grain
Grain就是虚拟磁盘中包含数据的一块扇区,granularity(姑且称之为“粒度”)是指grain的大小(单位为扇区),它是extent的一个属性,而且由文件头中grainSize所指定,默认值为128,因此每个grain包含64KB数据。稀疏型扩展文件的大小应该为grainSize的整数倍,每个grain均起始于grain size整数倍的偏移位置。
3.3.1 如何读取Hosted Sparse Extent中的一个扇区
假设你想从一个包含一个扩展文件的link中访问扇区号为x里的数据,那么就要知道你所要访问的扇区在哪个grain中:首先计算GDE序号,然后查找GD,以找到该GT的偏移。最后,在该grain中读取相应扇区中的数据即可。
gtCoverage = number of GTEs per GT * grainSize= 512 * 2G = 29 * 2G= 29+G sectors
如果grainSize 为128个扇区,那么gtCoverage = 2 9+7 = 2 16sectors = 32MB为确保包含该扇区的grain已被分配,你必须检查GT。为找到你所需要的GT,必须在GD中检查GDE:
GDE = GD [ floor(x/gtCoverage) ]
floor(s)的值为整数,函数定义如下:
floor(s) ≤ s <floor(s) + 1GTE = GT [ floor( (x % gtCoverage) /grainSize) ]
如果GTE为零,则意味着该grain还没有分配,;如果GTE为1,该grain中所有数据均为0s(更多详细内容请参考官方文档)。
3.3.2 概要
- GDE = GD [ floor(x / 2(9+G)) ]
- GTE = GT [ floor((x % 2(9+G)) /2G) ]
- [ GTE == 0 ] <==> [如果该VMDK文件无父,则表明该grain未分配,直接返0;如果该VMDK有父则从父链中读数据 ]
- [ GTE == 1 ] <==>[该grain中所有数据均为0s]
- [ GTE > 1 ] <==>[该grain存在,从中读取即可]
四、 转DD思路
- 如果有多个extent文件,则需要考虑跨文件(可理解跨GD)的情况;
- 要考虑所读取的数据跨grain、GT的情况;
- 下面是相同的多文件在使用不同工具解析出来的DD文件HASH值:
discutils_convert:562CAE2A917C5CF3C193C88A3F98E3D8
ftk_imager:7DA7C679DC5E772AE7F0B0F1CC1975FF
WinHex:D151F3A18FE89F569C9291EA700A8878
4.1 对单个VMDK文件解析算法大致如下
if( 所读取的数据在同一GT )
{
if ( 所读取的数据在同一grain )
{
if( 所对应GDE的值 == 0 )
{
// 直接读0
… …
}
else
// 正常读取数据
… …
}
else // 所读取的数据不在同一grain
{
// 读取第一个grain中的数据
… …
// 读取中间grain中的数据
… …
//读取最后一个grain中的数据
… …
}
}
else // 所读取的数据不在同一GT
{
// 读取第一个grain table所对应的数据
… …
// 先读不完整的grain到下一个grain之间的数据
… …
// 读取其后完整的grain
… …
// 读取中间grain table所对应的数据
… …
// 读取最后grain table所对应的数据
// 同第一个grain table类似,这里先读取完整的grain
… …
// 读取不完整的grain
… …
}
4.2 对于多文件的读取与对单文件的读取类似
if ( 所读取的数据在同一文件 )
{
// 直接按单文件读取即可
… …
}
else // 所读取的数据在多个文件中
{
// 读取开始文件中的数据
… …
// 读取中间文件中的数据
… …
// 读取最后文件中的数据
… …
}
参考链接: